目录
一、MapReduce实现大矩阵相乘
二. Spark中分布式矩阵使用
一、MapReduce实现大矩阵相乘
超大矩阵相乘(亿级别)的MapReduce实现思想详解
地址:https://blog.csdn.net/heyuanhao1989/article/details/50218911
MapReduce实现大矩阵乘法
参考:https://blog.csdn.net/xyilu/article/details/9066973
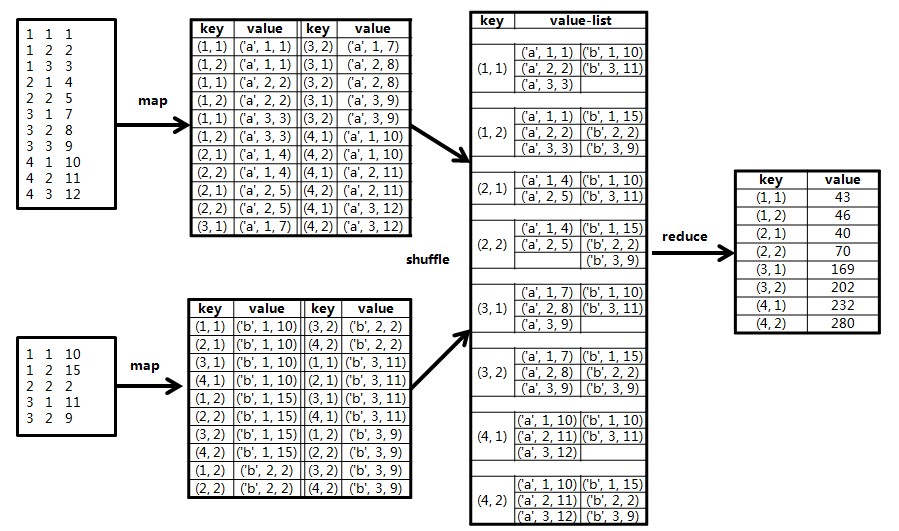
(1)在Map阶段,把来自表的元素,标识成条<key, value>的形式。其中,;把来自表的元素,标识成条<key, value>形式,其中,。
于是乎,在Map阶段,我们实现了这样的战术目的:通过key,我们把参与计算的数据归为一类。通过value,我们能区分元素是来自还是,以及具体的位置。
(2)在Shuffle阶段,相同key的value会被加入到同一个列表中,形成<key, list(value)>对,传递给Reduce,这个由Hadoop自动完成。
(3)在Reduce阶段,有两个问题需要自己问问:
当前的<key, list(value)>对是为了计算的哪个元素?
list中的每个value是来自表或表的哪个位置?
第一个问题可以从key中获知,因为我们在Map阶段已经将key构造为形式。第二个问题,也可以在value中直接读出,因为我们也在Map阶段做了标志。
接下来我们所要做的,就是把list(value)解析出来,来自的元素,单独放在一个数组中,来自的元素,放在另一个数组中,然后,我们计算两个数组(各自看成一个向量)的点积,即可算出的值。
示例矩阵和相乘的计算过程如下图所示:
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.StringTokenizer;import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.RecordWriter;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.mapred.lib.MultipleOutputFormat;
import org.apache.hadoop.util.Progressable;public class Bigmmult {public static final String CONTROL_I = "\u0009";public static final int MATRIX_I = 4;public static final int MATRIX_J = 3;public static final int MATRIX_K = 2;public static String makeKey(String[] tokens, String separator) {StringBuffer sb = new StringBuffer();boolean isFirst = true;for (String token : tokens) {if (isFirst)isFirst = false;elsesb.append(separator);sb.append(token);}return sb.toString();}public static class MapClass extends MapReduceBase implementsMapper<LongWritable, Text, Text, Text> { public static HashMap<String , Double> features = new HashMap<String, Double>();public void configure(JobConf job) {super.configure(job);}public void map(LongWritable key, Text value, OutputCollector<Text, Text> output,Reporter reporter) throws IOException, ClassCastException {// 获取输入文件的全路径和名称String pathName = ((FileSplit)reporter.getInputSplit()).getPath().toString();if (pathName.contains("m_ys_lab_bigmmult_a")) { String line = value.toString();if (line == null || line.equals("")) return;String[] values = line.split(CONTROL_I);if (values.length < 3) return;String rowindex = values[0];String colindex = values[1];String elevalue = values[2];for (int i = 1; i <= MATRIX_K; i ++) {output.collect(new Text(rowindex + CONTROL_I + i), new Text("a#"+colindex+"#"+elevalue));}}if (pathName.contains("m_ys_lab_bigmmult_b")) { String line = value.toString();if (line == null || line.equals("")) return;String[] values = line.split(CONTROL_I);if (values.length < 3) return;String rowindex = values[0];String colindex = values[1];String elevalue = values[2];for (int i = 1; i <= MATRIX_I; i ++) {output.collect(new Text(i + CONTROL_I + colindex), new Text("b#"+rowindex+"#"+elevalue));}}}}public static class Reduce extends MapReduceBaseimplements Reducer<Text, Text, Text, Text> {public void reduce(Text key, Iterator<Text> values,OutputCollector<Text, Text> output, Reporter reporter)throws IOException {int[] valA = new int[MATRIX_J];int[] valB = new int[MATRIX_J];int i;for (i = 0; i < MATRIX_J; i ++) {valA[i] = 0;valB[i] = 0;}while (values.hasNext()) {String value = values.next().toString();if (value.startsWith("a#")) {StringTokenizer token = new StringTokenizer(value, "#");String[] temp = new String[3];int k = 0;while(token.hasMoreTokens()) {temp[k] = token.nextToken();k++;}valA[Integer.parseInt(temp[1])-1] = Integer.parseInt(temp[2]);} else if (value.startsWith("b#")) {StringTokenizer token = new StringTokenizer(value, "#");String[] temp = new String[3];int k = 0;while(token.hasMoreTokens()) {temp[k] = token.nextToken();k++;}valB[Integer.parseInt(temp[1])-1] = Integer.parseInt(temp[2]);}}int result = 0;for (i = 0; i < MATRIX_J; i ++) {result += valA[i] * valB[i];}output.collect(key, new Text(Integer.toString(result)));}}
}基于MapReduce的大矩阵乘法(Spark实现)
参考:https://www.cnblogs.com/fang-jie/articles/6138789.html


二. Spark中分布式矩阵使用
相关参考: Spark中分布式矩阵使用https://www.aboutyun.com//forum.php/?mod=viewthread&tid=25271&extra=page%3D1&page=1&
Spark中的矩阵乘法源码分析 :https://blog.csdn.net/yhb315279058/article/details/50989974
综述
最近在开发一版基于协同过滤算法的推荐系统,需要用到历史7天的访问数据,约1万件商品,8千万用户。单机已经跑不动,只能转向Spark。为了计算相似度方便,就需要用到Spark中的分布式矩阵。
分布式矩阵
分布式矩阵由长整型的行列索引值和双精度浮点型的元素值组成。它可以分布式地存储在一个或多个RDD上,MLlib提供了三种分布式矩阵的存储方案:行矩 阵RowMatrix,索引行矩阵IndexedRowMatrix、坐标矩阵CoordinateMatrix和分块矩阵Block Matrix。它们都属于org.apache.spark.mllib.linalg.distributed包。
行矩阵
行矩阵RowMatrix是最基础的分布式矩阵类型。每行是一个本地向量,行索引无实际意义(即无法直接使用)。数据存储在一个由行组成的RDD中,其中 每一行都使用一个本地向量来进行存储。由于行是通过本地向量来实现的,故列数(即行的维度)被限制在普通整型(integer)的范围内。在实际使用时, 由于单机处理本地向量的存储和通信代价,行维度更是需要被控制在一个更小的范围之内。RowMatrix可通过一个RDD[Vector]的实例来创建, 如下代码所示
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 | // 创建两个本地向量dv1 dv2 val dv1 = Vectors.dense(1.0,2.0,3.0) val dv2 = Vectors.dense(4.0,5.0,6.0) // 使用两个本地向量创建一个RDD[Vector] val rows = sc.parallelize(Array(dv1,dv2)) // 通过RDD[Vector]创建一个行矩阵 val mat = new RowMatrix(rows) //可以使用numRows()和numCols()方法得到行数和列数 mat.numRows() mat.numCols() // 通过computeColumnSummaryStatistics()方法获取统计摘要 val summary = mat.computeColumnSummaryStatistics() summary.count summary.max summary.variance summary.mean summary.normL1 |
索引行矩阵
索引行矩阵IndexedRowMatrix与RowMatrix相似,但它的每一行都带有一个有意义的行索引值,这个索引值可以被用来识别不同行,或是 进行诸如join之类的操作。其数据存储在一个由IndexedRow组成的RDD里,即每一行都是一个带长整型索引的本地向量。
底层实现,是一个带行索引的RDD,这个RDD,每行是Long型索引和本地向量
与RowMatrix类似,IndexedRowMatrix的实例可以通过RDD[IndexedRow]实例来创建。如下代码段所示:
| 01 02 03 04 05 06 07 08 09 10 11 12 13 | import org.apache.spark.mllib.linalg.distributed.{IndexedRow, IndexedRowMatrix} // 通过本地向量dv1 dv2来创建对应的IndexedRow // 在创建时可以给定行的索引值,如这里给dv1的向量赋索引值1,dv2赋索引值2 val idxr1 = IndexedRow(1,dv1) val idxr2 = IndexedRow(2,dv2) // 通过IndexedRow创建RDD[IndexedRow] val idxrows = sc.parallelize(Array(idxr1,idxr2)) // 通过RDD[IndexedRow]创建一个索引行矩阵 val idxmat: IndexedRowMatrix = new IndexedRowMatrix(idxrows) idxmat.rows.foreach(println) |
坐标矩阵
坐标矩阵CoordinateMatrix是一个基于矩阵项构成的RDD的分布式矩阵。每一个矩阵项MatrixEntry都是一个三元组:(i: Long, j: Long, value: Double),其中i是行索引,j是列索引,value是该位置的值。坐标矩阵一般在矩阵的两个维度都很大,且矩阵非常稀疏的时候使用。
CoordinateMatrix实例可通过RDD[MatrixEntry]实例来创建,其中每一个矩阵项都是一个(rowIndex, colIndex, elem)的三元组
坐标矩阵可以通过transpose()方法对矩阵进行转置操作,并可以通过自带的toIndexedRowMatrix()方法转换成索引行矩阵IndexedRowMatrix。但目前暂不支持CoordinateMatrix的其他计算操作。
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 | import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry} // 创建两个矩阵项ent1和ent2,每一个矩阵项都是由索引和值构成的三元组 val ent1 = new MatrixEntry(0,1,0.5) val ent2 = new MatrixEntry(2,2,1.8) // 创建RDD[MatrixEntry] val entries = sc.parallelize(Array(ent1,ent2)) // 通过RDD[MatrixEntry]创建一个坐标矩阵 val coordMat = new CoordinateMatrix(entries) coordMat.entries.foreach(println) // 将coordMat进行转置 val transMat = coordMat.transpose() transMat.entries.foreach(println) // 将坐标矩阵转换成一个索引行矩阵 val indexedRowMatrix = transMat.toIndexedRowMatrix() indexedRowMatrix.rows.foreach(println) |
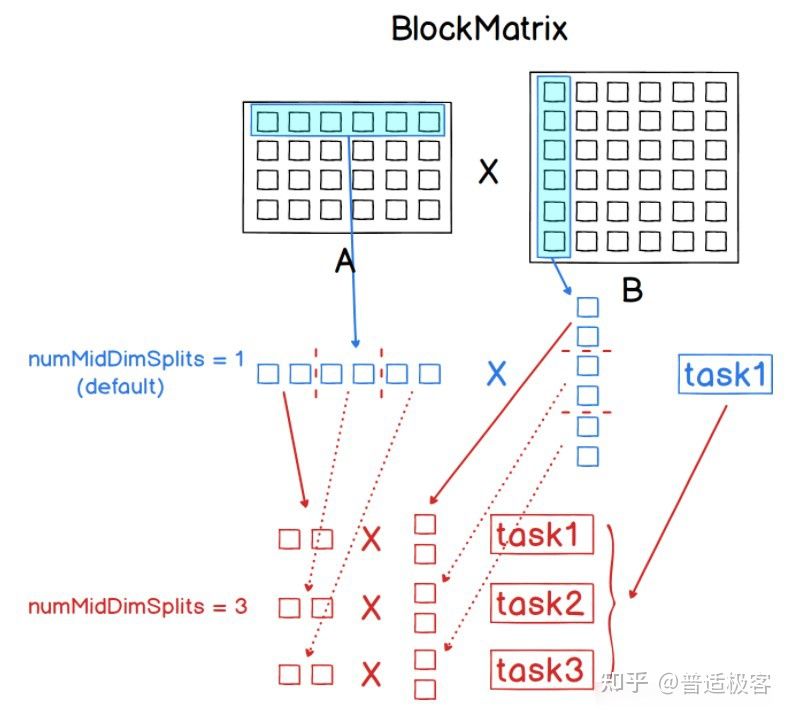
分块矩阵
分块矩阵是基于矩阵块MatrixBlock构成的RDD的分布式矩阵,其中每一个矩阵块MatrixBlock都是一个元组((Int, Int), Matrix),其中(Int, Int)是块的索引,而Matrix则是在对应位置的子矩阵(sub-matrix),其尺寸由rowsPerBlock和colsPerBlock决 定,默认值均为1024。分块矩阵支持和另一个分块矩阵进行加法操作和乘法操作,并提供了一个支持方法validate()来确认分块矩阵是否创建成功。
分块矩阵可由索引行矩阵IndexedRowMatrix或坐标矩阵CoordinateMatrix调用toBlockMatrix()方法来进行转 换,该方法将矩阵划分成尺寸默认为1024×1024的分块,可以在调用toBlockMatrix(rowsPerBlock, colsPerBlock)方法时传入参数来调整分块的尺寸。
| 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry} import org.apache.spark.mllib.linalg.distributed.BlockMatrix // 创建8个矩阵项,每一个矩阵项都是由索引和值构成的三元组 val ent1 = new MatrixEntry(0,0,1) val ent2 = new MatrixEntry(1,1,1) val ent3 = new MatrixEntry(2,0,-1) val ent4 = new MatrixEntry(2,1,2) val ent5 = new MatrixEntry(2,2,1) val ent6 = new MatrixEntry(3,0,1) val ent7 = new MatrixEntry(3,1,1) val ent8 = new MatrixEntry(3,3,1) // 创建RDD[MatrixEntry] val entries = sc.parallelize(Array(ent1,ent2,ent3,ent4,ent5,ent6,ent7,ent8)) // 通过RDD[MatrixEntry]创建一个坐标矩阵 val coordMat = new CoordinateMatrix(entries) // 将坐标矩阵转换成2x2的分块矩阵并存储,尺寸通过参数传入 val matA = coordMat.toBlockMatrix(2,2).cache() // 可以用validate()方法判断是否分块成功 matA.validate() //构建成功后,可通过toLocalMatrix转换成本地矩阵,并查看其分块情况: matA.toLocalMatrix // 查看其分块情况 matA.numColBlocks matA.numRowBlocks // 计算矩阵A和其转置矩阵的积矩阵 val ata = matA.transpose.multiply(matA) ata.toLocalMatrix |
分块矩阵BlockMatrix将矩阵分成一系列矩阵块,底层由矩阵块构成的RDD来进行数据存储。值得指出的是,用于生成分布式矩阵的底层RDD必须是 已经确定(Deterministic)的,因为矩阵的尺寸将被存储下来,所以使用未确定的RDD将会导致错误。而且,不同类型的分布式矩阵之间的转换需 要进行一个全局的shuffle操作,非常耗费资源。所以,根据数据本身的性质和应用需求来选取恰当的分布式矩阵存储类型是非常重要的。
存在的坑
1. CoordinateMatrix 的columnSimilarities()方法用来计算每两列之间的余弦相似度,原始数据为n*31的矩阵,计算每两列的余弦相似度,理论上得到一个 31*31的对称矩阵,对角线值为1(相同维度余弦相似度为1),及31*31=961个值,实际得到的是一个上三角稀疏矩阵,只有465个值。
这是因为相似矩阵是一个对角线全为1的对称矩阵,为了节约空间,最后的结果省略了对角线,且只保存了一半。
故而实际为 (1+30)*31/2 = (31*31 -31)/2 = 465
2. BlockMatrix multiply求矩阵乘法时,官网上给出下面一段注释
'''
If other contains SparseMatrix, they willhave to be converted to a DenseMatrix.The output BlockMatrix will only consist of blocks of DenseMatrix. This maycause some performance issues until support for multiplying two sparse matricesis added.
'''
就是两个相乘的矩阵必须都是稠密的,因为结果中之会包含稠密矩阵的Block。但是其它几种矩阵的toBlockMatrix()方法,转成的都是稀疏矩阵。这里spark出现了自相矛盾的情况。
上述问题可以通过spark core实现,将小的矩阵做成广播变量,运行速度很快。
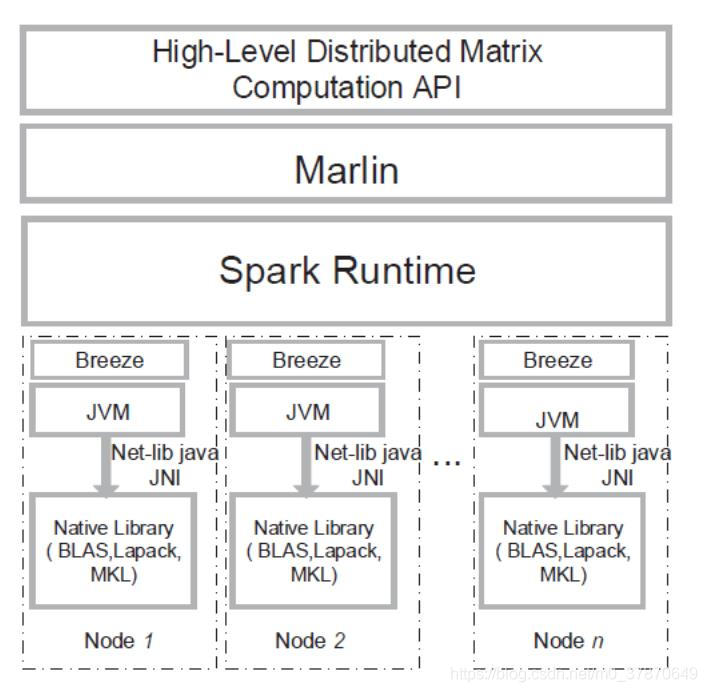
进阶--Marlin
Marlin 是南京大学 顾荣团队提出的基于Spark平台完成的矩阵运算库,为用户提供了大量矩阵运算的高层抽象原语,在性能方面远胜MapReduce相关的实现,在某些情况 下甚至优于传统数据并行处理时代的MPI实现,Malin无论是在易用性还是性能方面都达到了一个很好的高度。
架构如下:
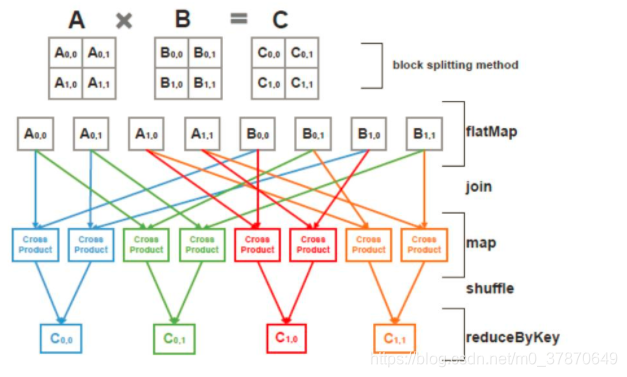
思想其实很简单,就是矩阵分块计算,而分块矩阵就成了小矩阵,然后就借助于Breeze实现。而对于Spark平台而言,其处理流程如下图:
感兴趣的,可以去看下他们的github
总结
通过分布式矩阵的方式,可以提高相似度计算的效率,达到推荐系统的实现需求。