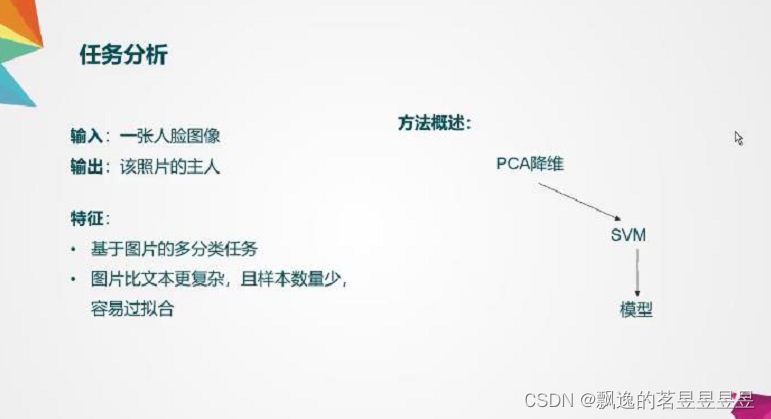
ORL人脸数据集共包含40个不同人的400张图像。所有图像都是以PGM格式存储的灰度图。每一个目录下的图像是在不同的时间、不同的光照、不同的面部表情条件下采集的。在该数据集中,每个人有10张照片。这10张照片中,前8张作为训练集,而后2张归为测试集。这样可以获得一个40×8大小的训练集,以及40×2大小的测试集。
特征提取
先将每张图片展开成 1x10304的维度,这里展开时会丢失一些图像信息,暂未采用卷积神经网络来进行规避。人脸数据有40种人脸,我们就用1到40来表示类别(py语言中for循环就是(1,41)),但是要注意在把400组1x10304的特征向量进行堆叠时是从第二次开始的。特征向量矩阵最后一列为类别,故最后的特征向量矩阵为400x10305
import numpy as np
from PIL import Image
import sklearnclass_fisher = []feature = np.array([[0]])
for i in range(1, 41):class_fisher.append(i)class_arry = np.array(class_fisher)for j in range(1, 11):path = 's{}/{}.pgm'.format(i, j)data = np.asarray(Image.open(path))value = np.column_stack((np.reshape(data, (1, -1)), class_arry))if i == 1 and j == 1:feature = valuecontinue feature = np.row_stack((feature, value))class_fisher.pop()
np.savetxt('feature.txt', feature)PCA降维
利用PCA降维至15维度,SVM系数C取50(可以根据模型预测情况变化),核函数选取的高斯核rbf
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
train_data = np.loadtxt('feature.txt')
data = train_data[:, :10304]
target = train_data[:, -1:]
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
pca = PCA(n_components=15)
x_train = pca.fit_transform(x_train)
model = SVC(C=50,kernel="rbf")
model.fit(x_train, y_train)
x_trans = pca.transform(x_test)
y_predict = model.predict(x_trans)
print('测试集前20个样本类别:', y_test[:20].tolist())
print('测试集前20个样本预测类别:', y_predict[:20])
from sklearn.metrics import classification_report
print(classification_report(y_test, y_predict))
完整代码
import numpy as np
from PIL import Image
import sklearnclass_fisher = []feature = np.array([[0]])
for i in range(1, 41):class_fisher.append(i)class_arry = np.array(class_fisher)for j in range(1, 11):path = 's{}/{}.pgm'.format(i, j)data = np.asarray(Image.open(path))value = np.column_stack((np.reshape(data, (1, -1)), class_arry))if i == 1 and j == 1:feature = valuecontinuefeature = np.row_stack((feature, value))class_fisher.pop()
np.savetxt('feature.txt', feature)from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
train_data = np.loadtxt('feature.txt')
data = train_data[:, :10304]
target = train_data[:, -1:]
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
pca = PCA(n_components=15)
x_train = pca.fit_transform(x_train)
model = SVC(C=50,kernel="rbf")
model.fit(x_train, y_train)
x_trans = pca.transform(x_test)
y_predict = model.predict(x_trans)
print('测试集前20个样本类别:', y_test[:20].tolist())
print('测试集前20个样本预测类别:', y_predict[:20])
from sklearn.metrics import classification_report
print(classification_report(y_test, y_predict))






![[编译原理]词法分析器的分析与实现](https://img-blog.csdn.net/20150616134813310)