-
实验目的
- 掌握词法分析器的功能。
- 掌握词法分析器的实现。
-
实验内容及要求
对于如下文法所定义的语言子集,试编写并上机调试一个词法分析程序:
<程序>→PROGRAM <标识符>;<分程序>.
<分程序>→<变量说明>BEGIN<语句表>END
<变量说明>→VAR<变量表>:<类型>;| <空>
<变量表>→<变量表>,<变量> | <变量>
<类型>→INTEGER
<语句表>→<语句表>;<语句> | <语句>
<语句>→<赋值语句> | <条件语句> | <WHILE语句> | <复合语句> | <过程定义>
<赋值语句>→<变量>:=<算术表达式>
<条件语句>→IF<关系表达式>THEN<语句>ELSE<语句>
<WHILE语句>→WHILE<关系表达式>DO<语句>
<复合语句>→BEGIN<语句表>END
<过程定义>→PROCEDURE<标识符><参数表>;
BEGIN<语句表>END
<参数表>→(<标识符表>)| <空>
<标识符表>→<标识符表>,<标识符> | <标识符>
<算术表达式>→<算术表达式>+<项> | <项>
<项>→<项>*<初等量> | <初等量>
<初等量>→(<算术表达式>)| <变量> | <无符号数>
<关系表达式>→<算术表达式><关系符><算术表达式>
<变量>→<标识符>
<标识符>→<标识符><字母> | <标识符><数学> | <字母>
<无符号数>→<无符号数><数字> | <数字>
<关系符>→= | < | <= | > | >= | <>
<字母>→A | B | C | ··· | X | Y | Z
<数字>→0 | 1 | 2 | ··· | 8 | 9
<空>→
要求和提示:
(1)单词的分类。
可将所有标识符归为一类;将常数归为另一类;保留字和分隔符则采取一词 一类。
(2)符号表的建立。
可事先建立一保留字表,以备在识别保留字时进行查询。变量名表及常数表 则在词法分析过程中建立。
(3)单词串的输出形式。
所输出的每一单词,均按形如(CLASS,VALUE)的二元式编码。对于变量标 识符和常数,CLASS字段为相应的类别码,VALUE字段则是该标识符、常数 在其符号表中登记项的序号(要求在变量名表登记项中存放该标识符的字符 串,其最大长度为四个字符;常数表登记项中则存放该整数的二进制形式)。 对于保留字和分隔号,由于采用一词一类的编码方式,所以仅需在二元式的 CLASS字段上放置相应的单词的类别码,VALUE字段则为“空”。不过,为便 于查看由词法分析程序所输出的单词串,也可以在CLASS字段上直接放置单 词符号串本身。
-
单词分类表
以下为单词分类表(单词符号,种别编码):
| 单词符号 | 种别编码 | 单词符号 | 种别编码 |
| auto | 1 | void | 30 |
| break | 2 | volatile | 31 |
| case | 3 | while | 32 |
| char | 4 | 标识符 | 33 |
| const | 5 | 常型整量 | 34 |
| continue | 6 | + | 35 |
| default | 7 | - | 36 |
| do | 8 | * | 37 |
| double | 9 | / | 38 |
| else | 10 | < | 39 |
| enum | 11 | <= | 40 |
| extern | 12 | > | 41 |
| float | 13 | >= | 42 |
| for | 14 | = | 43 |
| goto | 15 | == | 44 |
| if | 16 | <> | 45 |
| int | 17 | ; | 46 |
| long | 18 | ( | 47 |
| register | 19 | ) | 48 |
| return | 20 | ^ | 49 |
| short | 21 | , | 50 |
| signed | 22 | # | 51 |
| sizeof | 23 | % | 52 |
| static | 24 | [ | 53 |
| struct | 25 | ] | 54 |
| switch | 26 | { | 55 |
| typedef | 27 | } | 56 |
| union | 28 | . | 57 |
| unsigned | 29 | // | 58 |
-
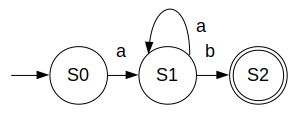
单词状态图

-
算法描述
1.首先,我将单词类别总分为六大类:
1:标识符
2:数字
3:算数运算符 + - * \
4:关系运算符 <、<=、>、>=、<>、=、==
5:保留字(32)
auto break case char const continue
default do double else enum extern
float for goto if int long
register return short signed sizeof static
struct switch typedef union unsigned void
volatile while
6:界符 ;、(、)、^、,、#、%、[、]、{、}、.、\\
2.每种单词类别的识别及判断方法如下:
首先从文件中读一个字符,赋值给ch,
如果ch为空格,则文件扫描列序号加一;
如果ch为回车,则文件扫描行序号加一;
其它情况如下:
(1)如果ch为字母或下划线,继续扫描,直到ch不是数字、字母或下划 线,则开始判断单词类型:
查找关键字表,若找到匹配项,则为关键字;
否则为标识符,查找标识符表,若没有找到匹配项,则添加到标识符表中。(动态生成标识符表)
如果ch为数字,继续扫描,直到ch不是数字,则开始判断单词类型: 若数字在合法范围内,则为数字,查找标识符表,若没有找到 匹配项,则添加到数字表中;(动态生成数字表)
否则为非法单词。
(2)如果ch是加减乘,一定是算数运算符。
(3)如果ch为;、(、)、^、,、#、%、[、]、{、}、.,则一定是界符。
(4)如果ch为<,则继续扫描下一个:
若下一个为=,则为<=;
若下一个为>,则为<>;
否则,为<。
(5)如果ch为>,则继续扫描下一个:
若下一个为=,则为>=;
否则,为>。
(6)如果ch为/,则继续扫描下一个:
若下一个为/,则为注释,这一行剩下的全被注释了;
否则,则为/。
3.出错处理:
我使用了两个全局变量:line,col,分别用于定位文件中扫描的位置信息,当发现当前字符为非法字符时,输出报错信息,并输出非法字符在文件中的所在位置信息。
4.输出显示:
将所输出的每一单词,均按形如(CLASS,VALUE)的二元式编码。对于变量标识符和常数,CLASS字段为相应的类别码,VALUE字段则是该标识符、常数在其符号表中登记项的序号。对于保留字和分隔号,由于采用一词一类的编码方式,为便于查看由词法分析程序所输出的单词串,所以在CLASS字段上直接放置单词符号串本身,VALUE字段则为“空”。使用分支结构,根据判断结果,从而进行相应输出显示。
-
程序结构
1.变量常量定义:
对程序所需常量以及全局变量进行定义,其中包含:
(1)全局变量:
int seekresult:fseek的时候用来接着的;
string word="":字符串,当前词;
char ch:每次读进来的一个字符;
int num=0:每个单词中当前字符的位置;
int line=1:行数;
int col=1:列数;
bool flag:文件是否结束扫描;
int type;:单词的类型;
char IDentifierTable[1000][40]:标识符表;
char DigitBTable[1000][40]常数表等。
(2)常量:
static char ReserveWord[32][20]:保留字表;
static char SuanshuOperator[4][4]:算术运算符表;
static char GuanxiOperator[7][4]:逻辑运算符表;
static char Jiefu[36][4]:界符表。
2.主要函数:
(1)bool Isletter(char x)函数:判断字符x是否为字母;
(2)bool IsDigit(char x)函数:判断字符x是否为数字;
(3)bool IsJiefu(char x)函数:判断字符x是否为界符;
(4)bool IsSuanshuyunsuanfu(char x) 函数:判断字符x是否为算数运算符;
(5)bool IsGuanxiyunsuanfu(char x)函数:判断字符x是否为关系运算符;
(6)int Scanner(FILE *fp)函数:其主要功能为从文件里读一个单词,调用基础函数进行单词类别,。
(7)int main()函数:程序入口,进行文件扫描,并调用Scanner(FILE *fp)函数对单词进行判断,输出分析结果。
-
运行结果
1.待分析文件code.txt:

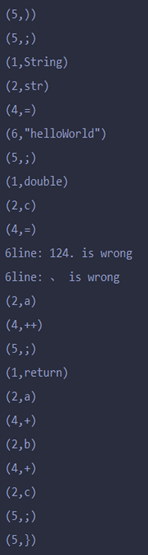
2.运行结果:


3.文件目录:

4.常数表:

5.标识符表:

-
调试情况
在此次实验中,遇到的问题还是比较多的,主要分为以下几种:
1.读文件和写文件操作:
由于待分析内容存储在文本文件中,所以文件的读取是必不可少的操作;而单词分析时需要动态生成标识符表和常数表,故需要追写文件。一开始由于语言功底不太扎实,实现的不太顺利,但是在上网查找了解决方案以后,问题就迎刃而解了。
2.各种单词类别的识别和判断以及出错处理:
这是词法分析器的核心也是难点,这部分必须逻辑十分清晰才可以实现,一开始虽然听懂了课堂上的内容,但是理解的还是不够深刻,感觉自己已经将单词类别进行了合理的划分,但是具体实现细节上还是遇到了不少的困难。比如,在一些相似单词的识别上面困惑了一段时间,想到了老师上课所说的“超前搜索”算法,所以我进行了实现,但是发现位置定位是一个需要特别关注的问题,我的解决方案就是:添加两个全局位置变量以及一些局部位置变量,将文件中现在正在扫描的位置以及这个单词第一个字符的位置信息记录下来,然后捋清他们之间的关系以及使用目的,则问题也就解决了,并且也使得报错信息可以包含非法字符在文件中的位置所在。
3.标识符表和常数表的动态生成:
关于这个问题的解决,我将它放在了识别的过程当中,就可以做到动态生成,并且添加了文件追写,则可以在文件中查看生成的表信息了。
4.输出显示:
这个问题一开始实现的有些困难,当我发现它的重心在于认清每个单词的分类情况,并通过识别结果就可以很好的实现了。
-
测试文件 code.txt
int main(void) {int min=2, mid=3, max=1, t;if (min > mid) {t = min;min = mid;mid = t;}if (min > max) {t = min;min = max;max = t;}if (mid > max) {t = mid;mid = max;max = t;}
}-
源代码
#include<iostream>
#include<fstream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cstdlib>using namespace std;/*
1:标识符
2:数字
3:算数运算符 + - *
4:关系运算符 <=、 >=、 <>、 == =、 <、>
5:保留字(32)
auto break case char const continue
default do double else enum extern
float for goto if int long
register return short signed sizeof static
struct switch typedef union unsigned void
volatile while
6:界符
*/int seekresult; //fseek的时候用来接着的
string word=""; //字符串,当前词
char ch; //每次读进来的一个字符
int num=0; //每个单词中当前字符的位置
int line=1; //行数
int col=1; //列数
bool flag; //文件是否结束扫描
int type; //单词的类型//保留字表
static char ReserveWord[32][20] = {"auto", "break", "case", "char", "const", "continue","default", "do", "double", "else", "enum", "extern","float", "for", "goto", "if", "int", "long","register", "return", "short", "signed", "sizeof", "static","struct", "switch", "typedef", "union", "unsigned", "void","volatile", "while"
};//算术运算符表
static char SuanshuOperator[4][4] = {"+", "-", "*", "/"
};
//逻辑运算符表
static char GuanxiOperator[7][4] = {"<", "<=", ">", ">=", "=", "==","<>"
};
//界符表(12)
static char Jiefu[36][4] = {";", "(", ")", "^", ",", "#","%", "[", "]", "{", "}","."
};//标识符表
//string IDentifierTable[1000] = { "" };
char IDentifierTable[1000][40] = {};//常数表
//int DigitBTable[1000][50] = {};
char DigitBTable[1000][40] = {};int Inum=0;int Dnum=0;//判断是否是:字母
bool Isletter(char x)
{if((x>='a'&&x<='z')||(x>='A'&&x<='Z'))return true;else return false;
}//判断是否是:数字
bool IsDigit(char x)
{if(x>='0'&&x<='9')return true;elsereturn false;
}//判断是否是:界符
bool IsJiefu(char x)
{int i=0;int temp=0;for(i=0;i<14;i++){if( x == Jiefu[i][0] ){temp=1;break;} }if( temp == 1 )return true;elsereturn false;
}//判断是否是 算数运算符:加减乘
bool IsSuanshuyunsuanfu(char x)
{if(x=='+'||x=='-'||x=='*')return true;else return false;
}//判断是否是 关系运算符:等于(赋值),大于小于(大于等于,小于等于,大于小于)
bool IsGuanxiyunsuanfu(char x)
{if(x=='='||x=='<'||x=='>')return true;elsereturn false;
} //从文件里读一个单词
int Scanner(FILE *fp)
{//先读一个字符,赋值给ch ch=fgetc(fp);if(feof(fp)){flag=0;return 0;}else if(ch==' '){col++;return 0;}else if(ch=='\n'){line++;col=1;return 0;}//如果是字母开头或 '_' 看关键字还是标识符 else if( Isletter(ch) || ch=='_' ){word+=ch;col++;while( (ch=fgetc(fp)) && ( Isletter(ch) || IsDigit(ch) || ch=='_')){word+=ch;col++;}//文件读完,返回trueif(feof(fp)){flag=0;return 1;}//检验是否是保留字 for(int i=1;i<=32;i++){if( word == ReserveWord[i] ){//SEEK_CUR当前位置,fseek函数作用:文件位置指针从当前位置位移一个位置 seekresult=fseek(fp,-1,SEEK_CUR);//5+i-1:保留字 return 5+i-1;}}for(int Ii=0;Ii<Inum;Ii++){if(Inum!=0 && strcmp(IDentifierTable[Ii],word.c_str())==0){seekresult=fseek(fp,-1,SEEK_CUR); //1:标识符 //return 1;return 1000+Ii+1;}}strcpy(IDentifierTable[Inum],word.c_str());Inum=Inum+1;//写追加 ofstream Arithmetic_operator;Arithmetic_operator.open("IDentifierTable.txt",ios::app);Arithmetic_operator<<word<<" "<<endl;Arithmetic_operator.close();seekresult=fseek(fp,-1,SEEK_CUR); //1:标识符 //return 1;return 1000+Inum;}//开始是加减乘,一定是算数运算符3 else if(IsSuanshuyunsuanfu(ch)){word+=ch;col++;//3:算数运算符 return 3;}//开始是数字就一定是数字2 else if(IsDigit(ch)){word+=ch;col++;while((ch=fgetc(fp)) && IsDigit(ch)){word+=ch;col++;}int Di=0;for(Di=0;Di<Inum;Di++){if(Dnum!=0 && strcmp(DigitBTable[Di],word.c_str())==0){seekresult=fseek(fp,-1,SEEK_CUR); //2:数字 //return 2;return 2000+Di+1;}}strcpy(DigitBTable[Dnum],word.c_str());Dnum=Dnum+1;//写追加 ofstream Arithmetic_operator;Arithmetic_operator.open("DigitBTabl.txt",ios::app);Arithmetic_operator<<word<<" "<<endl;Arithmetic_operator.close();// if(feof(fp)){
// flag=0;
// return 2;
// }seekresult=fseek(fp,-1,SEEK_CUR);//2:数字 return 2000+Dnum;}//检验界符6 else if(IsJiefu(ch)){int Ji;for(Ji=0;Ji<12;Ji++){if( ch == Jiefu[Ji][0] ){break;} }word+=ch;col++;//6-1+32+i:界符 return (6-1+32+Ji);}//检验关系运算符4 :<=、>=、<>、==、 < 、>else if( IsGuanxiyunsuanfu(ch) ){col++;word+=ch;//检验 <> <=if(ch=='<') {ch=fgetc(fp);if(ch=='>' || ch=='='){word+=ch;col++; return 4;}}//检验 >= ==else{ch=fgetc(fp);if(ch=='='){word+=ch;col++;return 4;}}if(feof(fp)){flag=0;}seekresult=fseek(fp,-1,SEEK_CUR);//3:算数运算符 return 3;}//首字符是 / 有可能是除号 也有可能是注释else if(ch=='/'){col++;word+=ch;ch=fgetc(fp);//这种情况是除号if(ch!='*' && ch !='/'){seekresult=fseek(fp,-1,SEEK_CUR);//3:算数运算符 return 3;}//注释符//:这一行剩下的全被注释了if(ch=='/'){word.clear();while((ch=fgetc(fp)) && ch!='\n' && !feof(fp) ){}if(feof(fp)){flag=0;return 0;}else{seekresult=fseek(fp,-1,SEEK_CUR);}line++;col=1;return 0;}if(ch=='*'){bool flag5=1;while(flag5){word.clear();ch=fgetc(fp);col++;if(ch=='\n'){line++;col=1;}if(ch!='*')continue;else {ch=fgetc(fp);col++;if(ch=='\n'){line++;col=1;}if(ch=='/'){flag5=0;}else continue;}if(feof(fp)){flag=0;return 0;}}}}else {word+=ch;col++;return -1;}
}int main()
{FILE *fp;cout<<"open "<<"code.txt"<<endl;system("pause");flag=1;//打开源代码文件 //未打开 if((fp=fopen("code.txt","r"))==NULL){cout<<"Sorry,can't open this file."<<endl;flag=0;}//已打开 while(flag==1){//反复调用扫描函数提取单词type=Scanner(fp); //1:标识符if(type>1000&&type<2000){//cout<<"type:1 identifier "<<"line "<<line<<" col "<<col-word.length()<<" "<<word<<endl;cout<<"("<<word<<","<<type-1000<<")"<<endl; if(word.length()>20)cout<<"ERROR Identifier length cannot exceed 20 characters"<<endl;word.clear();}//2:数字 else if(type>2000){//cout<<"type:2 positive number "<<"line "<<line<<" col "<<col-word.length()<<" "<<word<<endl;cout<<"("<<word<<","<<(type-2000)<<")"<<endl;if(word[0]=='0')cout<<"ERROR: The first digit cannot be 0!"<<endl;word.clear();}//3:算数运算符 + - * / else if(type==3){//cout<<"type:3 unary_operator "<<"line "<<line<<" col "<<col-1<<" "<<word<<endl;cout<<"("<<word<<","<<"3"<<")"<<endl;word.clear();}//4:关系运算符 <、<=、>、>=、= 、<> else if(type==4){//cout<<"type:4 double_operator "<<"line "<<line<<" col "<<col-2<<" "<<word<<endl;cout<<"("<<word<<","<<"4"<<")"<<endl;word.clear();}//6-1+32 - 6-1+32+11:界符else if(type>=37){//cout<<"type:5 Separator "<<"line "<<line<<" col "<<col-1<<" "<<word<<endl;cout<<"("<<word<<","<<"_"<<")"<<endl;//cout<<"("<<type<<","<<"_"<<")"<<endl; word.clear();}//5 - 5-1+32:保留字 else if( type>=5 && type<=36){//cout<<"type:6 reserved word "<<"line "<<line<<" col "<<col-word.length()<<" "<<word<<endl;cout<<"("<<word<<","<<"_"<<")"<<endl;//cout<<"("<<type<<","<<"_"<<")"<<endl; word.clear();}//非法字符else if(type==-1){cout<<"Illegal character "<<"line "<<line<<" col "<<col-1<<" "<<word<<endl;word.clear();}}int a=fclose(fp);cout<<"Do you want to close?(Y or N)"<<endl;char end;while(cin>>end && end!='Y'){cout<<"Do you want to close?(Y or N)"<<endl;}return 0;
}





![[编译原理]词法分析器的分析与实现](https://img-blog.csdn.net/20150616134813310)