词法分析器
- 一.前言
- 二.什么是“词法分析器”?
- 三.正式设计
- 1.设计种别码表
- 2.设置判断为字母或数字的函数
- 3.设置全局参数
- 4.核心:scan()函数
- 5.主函数里结合scan函数进行循环扫描
- 6.结果截图
- 7.需要注意(比较难)的地方
- 四.心得体会
- 五.源代码
一.前言
编译原理的第一个实验:设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
如果你有点思路但码力不足,可以跟着我一步步来手肝!
二.什么是“词法分析器”?
词法分析程序简单来说就是“读单词程序”,
该程序扫描高级语言编写的源程序,将源程序中由“单词符号”组成的字符串分解出一个个单词来。
单词符号分为5种:
1.保留字:例如C语言中的if、else、while、do等等
2.标识符:通常由用户自己定义。用来标记常量、数组、变量、类型等等。a,b,c等
3.常数:整型常数369、布尔常数TRUE等
4.运算符:如“+、-、*、/、<、>”
5.界符:在语言中是作为语法上的分界符号使用的,如“,”“;”“(”“)”等注意:保留字、运算符、界符的个数是确定的; 而常数、标识符则是不限定个数的。
词法分析器例子:
输入内容:源程序字符串。
例如“int a=1;a++;”
输出内容:输出的是与源程序等价的单词符号序列,并且所输出的单词符号通常表示成如下的二元式:
(单词种别,单词自身的词)
单词种别:我们可以类比成,每个种类都有相对应的“种别码”,即给对应的种别进行编号以加以区分。
就像自然界中,我们可以将植物编号为0,动物编号为1等等
单词自身的词:就是说在同一种类的不同单词区别开来。
比如,动物中可以再细分:两栖动物内码编号为1,哺乳动物内码编号为2等
所以当我们输入“小狗”,则输出二元式(1,2)
当然这只是形象的比喻,在计算机中我们往往需要识别什么“int、a、+、-”等等符号,其实原理和刚刚举的例子有相同之处的。
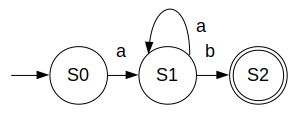
- [1] 流程图:
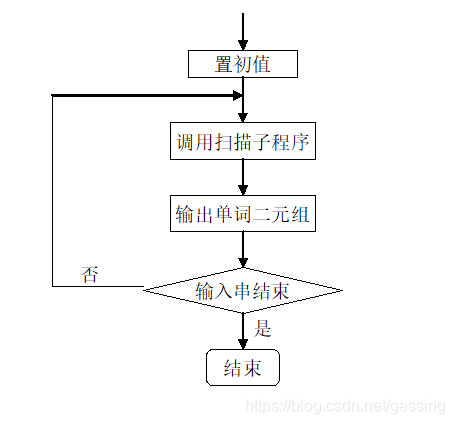
- [2] 状态转化图:
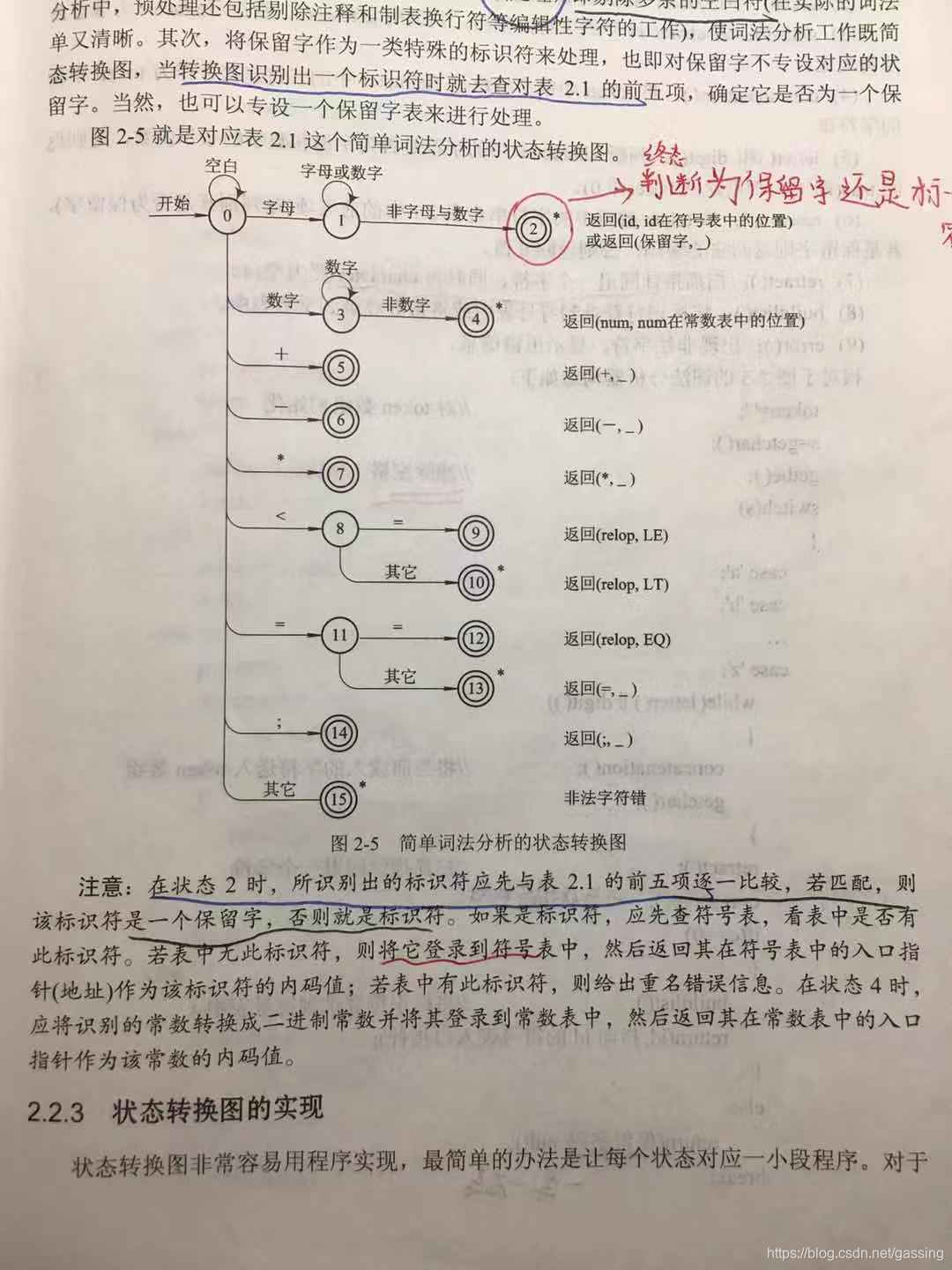
三.正式设计
1.设计种别码表
由于实验里已经给出了,我们就按照它纯cout出来就行了。
用一个函数showAll()来展示
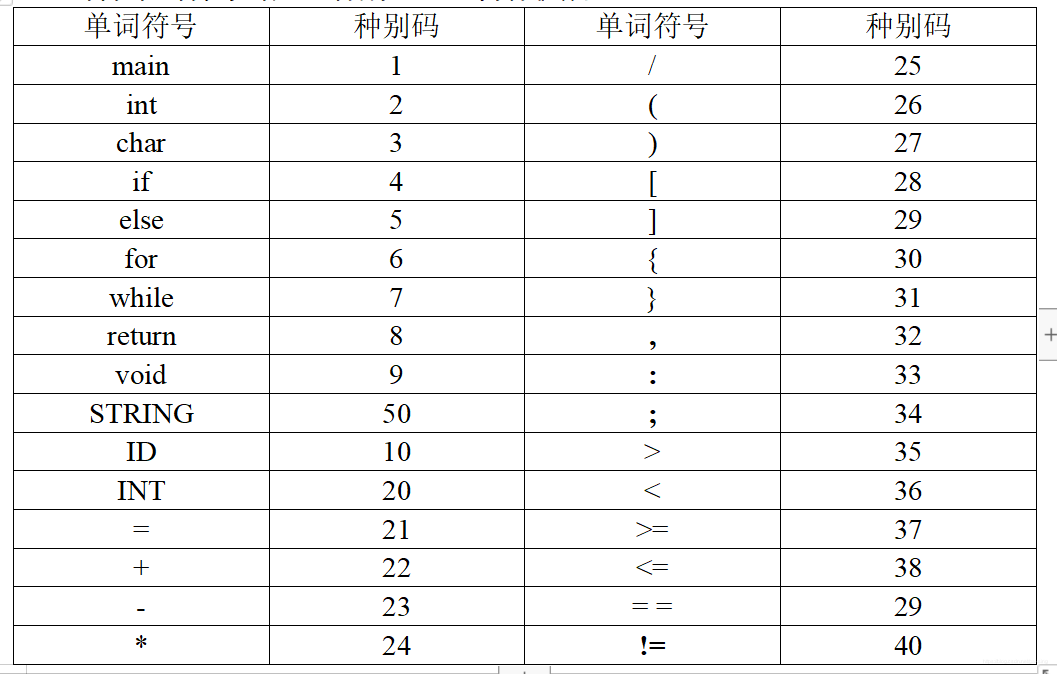
void showAll() //展示部分单词符号所对应的种别码(可自行扩展)
{cout << "---------- 符号表---------------------- " << endl;cout << "符号\t种别码" << "\t" << "符号\t种别码" << endl;cout << "main" << '\t' << '1' << '\t' << "/" << '\t' << "25" << endl;cout << "int" << '\t' << '2' << '\t' << "(" << '\t' << "26" << endl;cout << "char" << '\t' << '3' << '\t' << ")" << '\t' << "27" << endl;cout << "if" << '\t' << '4' << '\t' << "[" << '\t' << "28" << endl;cout << "else" << '\t' << '5' << '\t' << "]" << '\t' << "29" << endl;cout << "for" << '\t' << '6' << '\t' << "{" << '\t' << "30" << endl;cout << "while" << '\t' << '7' << '\t' << "}" << '\t' << "31" << endl;cout << "return" << '\t' << '8' << '\t' << "," << '\t' << "32" << endl;cout << "void" << '\t' << '9' << '\t' << ":" << '\t' << "33" << endl;cout << "STRING" << '\t' << "50" << '\t' << ";" << '\t' << "34" << endl;cout << "ID" << '\t' << "10" << '\t' << ">" << '\t' << "35" << endl;cout << "INT" << '\t' << "20" << '\t' << "<" << '\t' << "36" << endl;cout << "=" << '\t' << "21" << '\t' << ">=" << '\t' << "37" << endl;cout << "+" << '\t' << "22" << '\t' << "<=" << '\t' << "38" << endl;cout << "-" << '\t' << "23" << '\t' << "==" << '\t' << "39" << endl;cout << "*" << '\t' << "24" << '\t' << "!=" << '\t' << "40" << endl;cout << "---------------------------------------" << endl;cout << "@author(Gassing)" << endl;
}
2.设置判断为字母或数字的函数
为什么要做这一步?因为在状态转化图中,我们可以看到当我们要判断是保留字还是标识符时,首先要判断这个输入的字符是字母还是数字以方便后续的判断。
因此我们设置两个函数:
- bool IsLetter(char ch); //判断是否为字母
- bool IsDigit(char ch); //判断是否为数字
具体代码:
bool IsLetter(char ch) //判断是否为字母
{if ((ch >= 'a'&&ch <= 'z') || (ch >= 'A'&&ch <= 'Z'))return true;elsereturn false;}bool IsDigit(char ch) //判断是否为数字
{if (ch >= '0'&&ch <= '9')return true;elsereturn false;}
3.设置全局参数
//保留字
const string KeyWord[12] = { "main","int","char","if","else","for","while","return","void","STRING","ID","INT" }; //这个还可以有很多东西加,这里只是简单模拟而已,感兴趣的可以自己多加int syn; //单词种别码
string token; //单词自身字符串int sum; //INT整型里的码内值int i = 0; int tag = 1; //后面判断STRING字符的 string a=""; //你所输入的字符串4.核心:scan()函数
我们自己设置一个函数scan(),此函数就是整个词法分析器的核心。
因为我们输入字符串进去,众所周知,字符串可以当作由多个字符组成的,即string a = “int”,也可以分解为a[0]=‘i’,a[1]=‘n’,a[2]=‘t’,a[3]=’\0’。
所以其实计算机是在字符串里一个个的单个字符进行分析的,而这个scan函数的作用就是对输入的这个字符进行判断,是属于哪一种种类。
token:用来记录扫描到的成型的标识符或关键字
syn:种别码
可以看到有空格就会跳过,若没有空格,则清空token,然后进行判断是字母、数字还是符号。然后若是字母或者数字则用个while循环来将s[i]加入到token这个字符串里,最后当扫描到不是字母或数字时就会跳出循环。此时判断并给出相对应的syn,然后保存token。
举个栗子,我现在输入字符串s=“int”,int i=0 然后扫描第i个字符,s[i] (即s[0])为 ‘i’ ,然后进到“拼字符串”环节,用while实现(每次都要i++),
token += s[i] ;
然后得到token = “int” ;
然后得到syn = 2 ;// int关键字对应种别码2
~ 代码有点长,放在最后了,可自行拉到最后查看。
- scan函数的流程图,非常清晰!
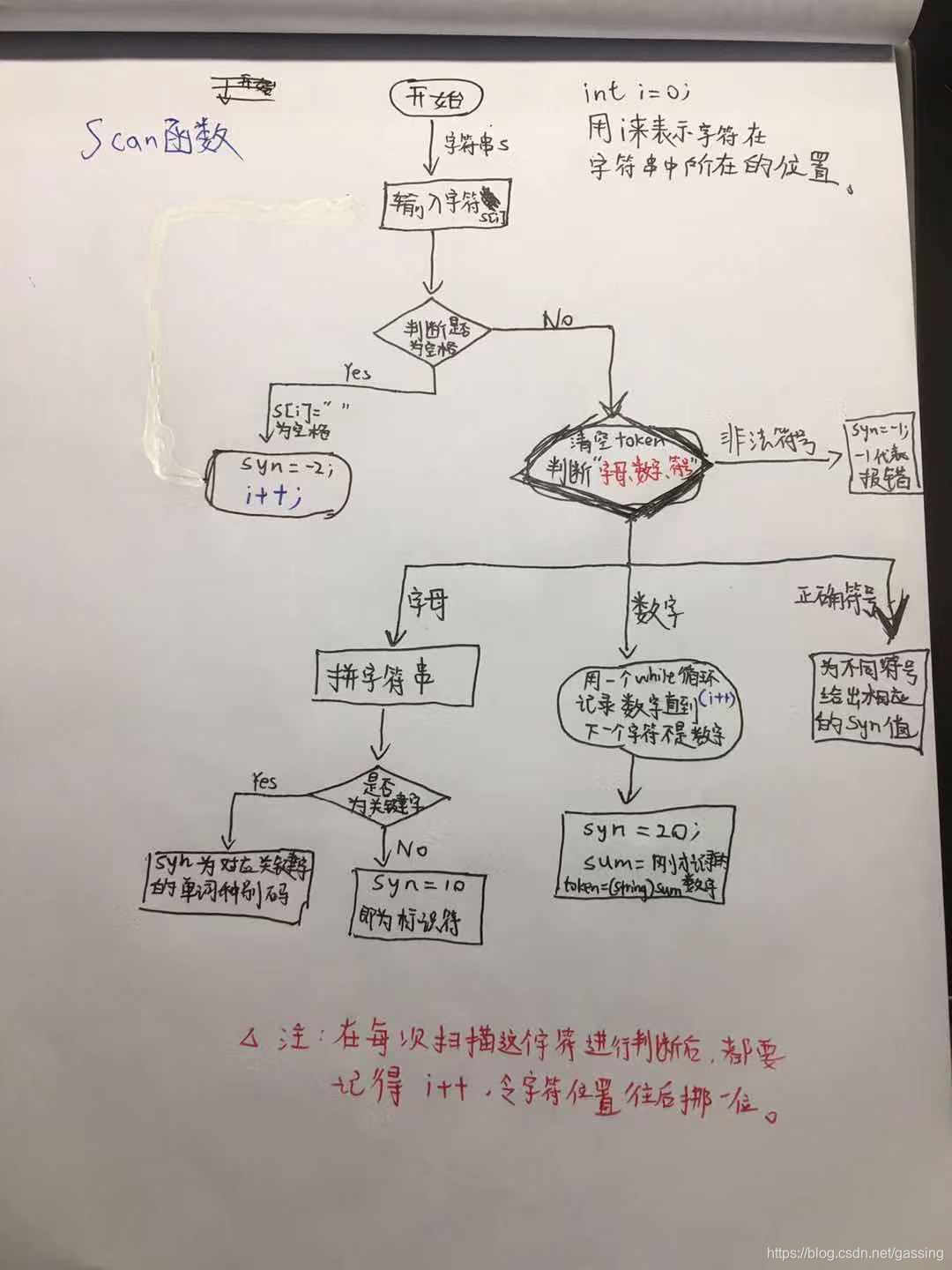
5.主函数里结合scan函数进行循环扫描
我们可以把上面的scan函数当作是一个扫描机器,每次只能扫描一个字符。
所以我们若要扫描完所有字符,则可以在主函数里设置一个do-while函数,使得输入的字符串可以循环扫描完。
do{scan(a);switch (syn) //最后判断一波syn{case -1:cout << "error:无结束符或存在非法字符" << endl;syn = 0;break;case -2: //遇到空格跳过break;default:if(syn!=0)cout << "( " << syn << "," << token << " )" << endl;}} while (syn!=0);
可以看出,我们跳出的条件是syn = 0;
那么syn =0 的情况:
- 正常情况:我们可以要求我们输入的字符串在最后必须加入一个结束符“#”,来表示结束,当scan扫描到最后一个字符是“#”的时候就知道结束了,然后将syn = 0,跳出循环。
- 非正常情况:如果遇到非法字符的话就将syn=0;然后告诉我们error,存在非法字符,结束循环。
此时有人会问:刚刚在scan里面得到的token和syn在哪里展示出来呢?
---- 我们在do-while 循环里用switch(syn)来选择,在default那里,在每次scan结束后进行输出二元组(syn,token)。
case-1: 代表error。
case-2:代表刚刚scan那里遇到空格,则直接break,不进行选择。
~@经过一系列的分析,整个词法分析器就完成啦!
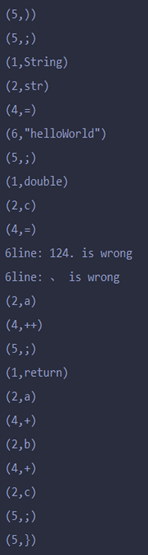
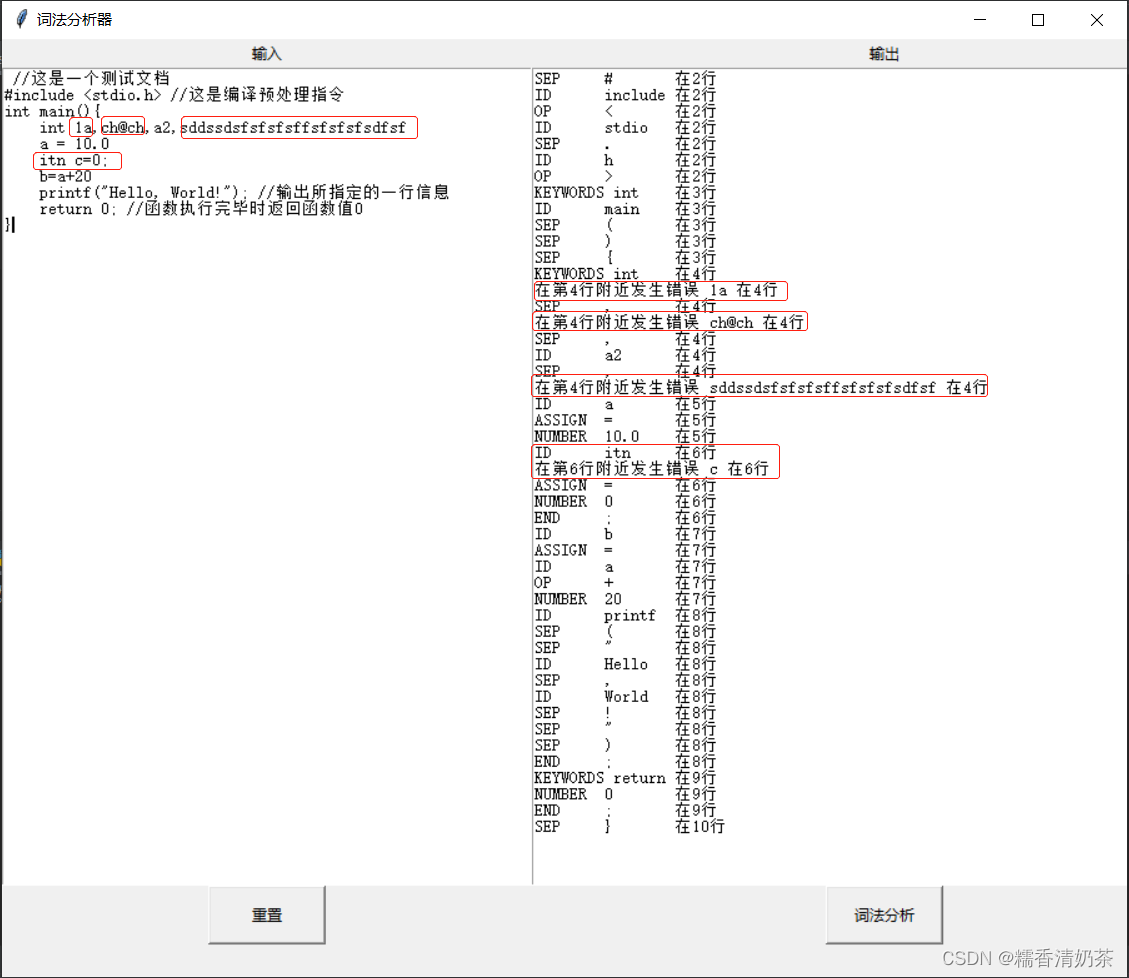
6.结果截图
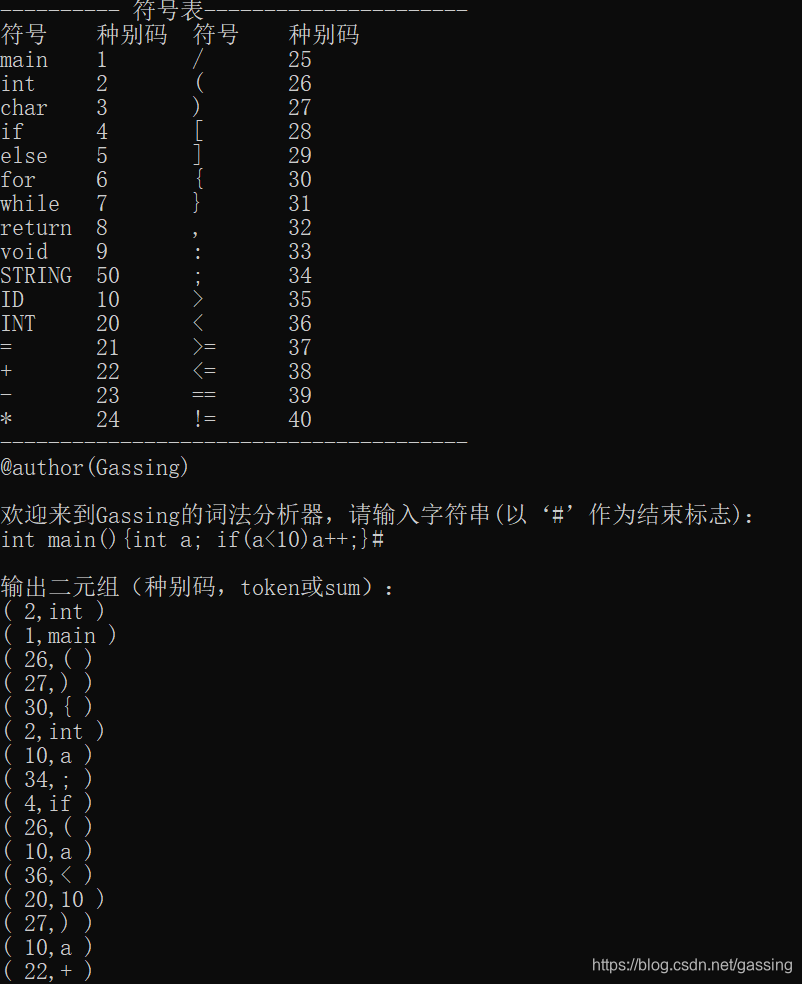

- 还有含字符串的,看下图
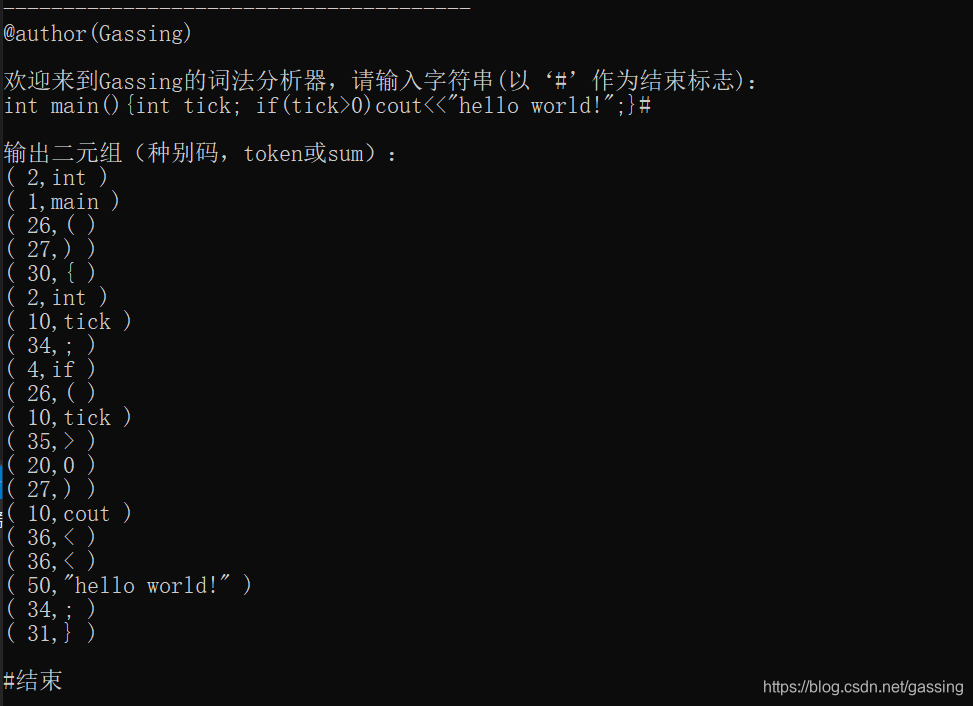
7.需要注意(比较难)的地方
- 判断字符串这里
case '"':syn = -1;token += s[i];i++;while (s[i] != '"'){if (s[i] == '#'){tag = 0;break;}else{token += s[i];i++;}}if (tag){token += s[i];i++;syn = 50;break;}else{syn = -1;cout << "双引号只存在一个,非法输入 " << endl;break;}
遇到单引号的时候我们先说它是非法字符,然后继续扫描,在遇到另一个单引号之前用token记录,若遇到另一个单引号,则说明两个双引号之间是字符串STRING,则让syn=50;
若一直遇不到,直到扫描到最后的字符是‘#’结束符,则说明只存在一个单引号,说明是非法的,则令syn=-1;
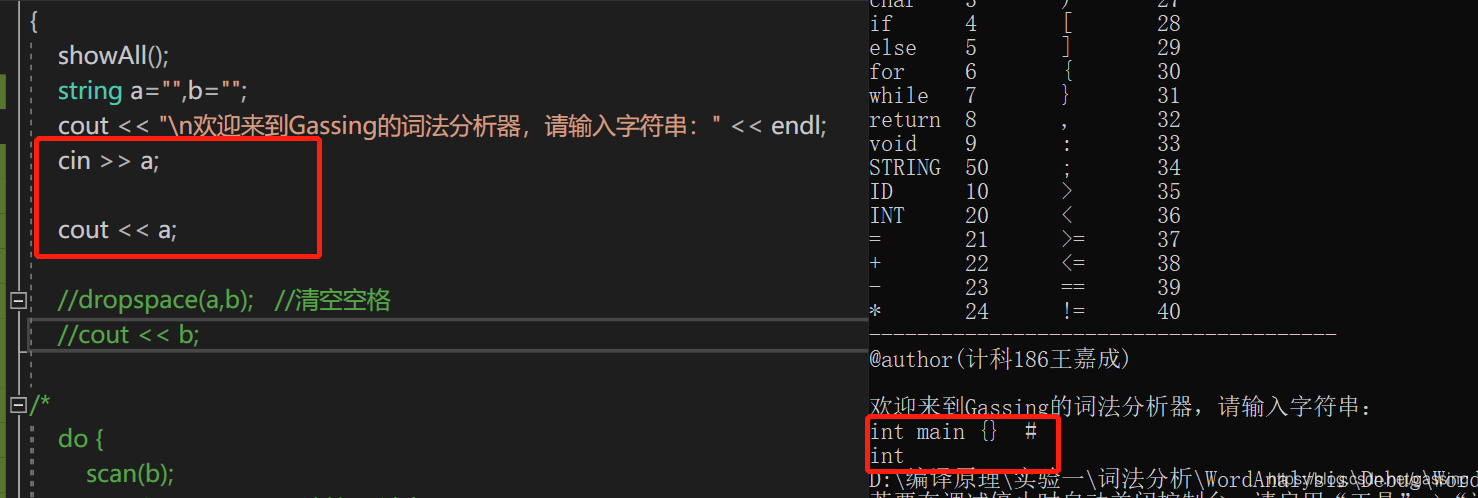
小技巧:
在开始的时候string a;然后我输入int main,中间有个空格,但输出的却是只有int,空格后面的却不见了。
若想要保留空格的话,要用getline(cin,a);
四.心得体会
其实看起来简单,但还是调试了两三天,思路其实不难,感觉还是细节的问题。其实大家有余力的话可以在种别码表里加多点种类,然后就是CV的苦力活了,很简单的,照葫芦画瓢,来充实你的词法分析器。
其实这个输入字符串,我们也可以创建一个txt文件,里面就输入些字符串,然后在main函数里open就行了。这只是一个形式,最主要还是思想吧~
最后希望大家都能看得懂,如果有什么不懂或评价都可以在评论区,或者私信我都可以,大家讨论交流!
@如果这篇文章能帮到你的话,可以点个赞给作者一个支持哦!也可以关注我~
五.源代码
#include "pch.h"
#include <iostream>
#include<string>
#include <stdio.h>
using namespace std;//保留字
const string KeyWord[12] = { "main","int","char","if","else","for","while","return","void","STRING","ID","INT" }; //这个还可以有很多东西加,这里只是简单模拟而已,感兴趣的可以自己多加int syn; //单词种别码
string token; //单词自身字符串int sum; //INT整型里的码内值int i = 0; int tag = 1; //后面判断STRING字符的 void showAll(); //输入部分单词符号所对应的种别码(可自行扩展)bool IsLetter(char ch); //判断是否为字母bool IsDigit(char ch); //判断是否为数字void scan(string s); //扫描int main()
{showAll();string a="";cout << "\n欢迎来到Gassing的词法分析器,请输入字符串(以‘#’作为结束标志):" << endl;getline(cin,a);cout<<"\n输出二元组(种别码,token或sum):"<<endl;do{scan(a);switch (syn) //最后判断一波syn{case -1:cout << "error:无结束符或存在非法字符" << endl;syn = 0;break;case -2: //遇到空格跳过break;default:if(syn!=0)cout << "( " << syn << "," << token << " )" << endl;}} while (syn!=0);}void showAll() //展示部分单词符号所对应的种别码(可自行扩展)
{cout << "---------- 符号表---------------------- " << endl;cout << "符号\t种别码" << "\t" << "符号\t种别码" << endl;cout << "main" << '\t' << '1' << '\t' << "/" << '\t' << "25" << endl;cout << "int" << '\t' << '2' << '\t' << "(" << '\t' << "26" << endl;cout << "char" << '\t' << '3' << '\t' << ")" << '\t' << "27" << endl;cout << "if" << '\t' << '4' << '\t' << "[" << '\t' << "28" << endl;cout << "else" << '\t' << '5' << '\t' << "]" << '\t' << "29" << endl;cout << "for" << '\t' << '6' << '\t' << "{" << '\t' << "30" << endl;cout << "while" << '\t' << '7' << '\t' << "}" << '\t' << "31" << endl;cout << "return" << '\t' << '8' << '\t' << "," << '\t' << "32" << endl;cout << "void" << '\t' << '9' << '\t' << ":" << '\t' << "33" << endl;cout << "STRING" << '\t' << "50" << '\t' << ";" << '\t' << "34" << endl;cout << "ID" << '\t' << "10" << '\t' << ">" << '\t' << "35" << endl;cout << "INT" << '\t' << "20" << '\t' << "<" << '\t' << "36" << endl;cout << "=" << '\t' << "21" << '\t' << ">=" << '\t' << "37" << endl;cout << "+" << '\t' << "22" << '\t' << "<=" << '\t' << "38" << endl;cout << "-" << '\t' << "23" << '\t' << "==" << '\t' << "39" << endl;cout << "*" << '\t' << "24" << '\t' << "!=" << '\t' << "40" << endl;cout << "---------------------------------------" << endl;cout << "@author(Gassing)" << endl;
}bool IsLetter(char ch) //判断是否为字母
{if ((ch >= 'a'&&ch <= 'z') || (ch >= 'A'&&ch <= 'Z'))return true;elsereturn false;}bool IsDigit(char ch) //判断是否为数字
{if (ch >= '0'&&ch <= '9')return true;elsereturn false;}void scan(string s) //扫描
{if (s[i] == ' '){syn = -2;i++;}else{token = ""; //清空当前字符串// 1.判断字符是否为数字if (IsDigit(s[i])){token = ""; //清空当前字符串sum = 0;while (IsDigit(s[i])) {sum = sum * 10 + (s[i] - '0');i++; //字符位置++syn = 20; //INT种别码为20}token += to_string(sum); //骚操作,直接转化字符串}// 2.字符为字符串,表现为字母开头衔接任意个数字或字母else if (IsLetter(s[i])){token = ""; //清空当前字符串while (IsDigit(s[i]) || IsLetter(s[i])) {token += s[i]; //加入token字符串i++;}//s[i] = '\0'; //刚刚上面最后i++了所以补充syn = 10; // 如果是标识符,种别码为10//如果是关键字,则用for循环将token与keyword比较找对应的种别码for (int j = 0; j < 12; j++){if (token == KeyWord[j]) //如果都是string类型,可以直接=相比较,若相等则返回1,否则为0{syn = j + 1; //种别码从1开始所以要加1break;}}}//3. 判断为符号else {token = ""; //清空当前字符串switch (s[i]) {case'=':syn = 21;i++;token = "=";if (s[i] == '=') {syn = 39;i++;token = "==";}break;case'+':syn = 22;i++;token = "+";break;case'-':syn = 23;i++;token = "-";break;case'*':syn = 24;i++;token = "*";break;case'/':syn = 25;i++;token = "/";break;case'(':syn = 26;i++;token = "(";break;case')':syn = 27;i++;token = ")";break;case'[':syn = 28;i++;token = "[";break;case']':syn = 29;i++;token = "]";break;case'{':syn = 30;i++;token = "{";break;case'}':syn = 31;i++;token = "}";break;case',':syn = 32;i++;token = ",";break;case':':syn = 33;i++;token = ":";break;case';':syn = 34;i++;token = ";";break;case'>':syn = 35;i++;token = ">";if (s[i] == '='){syn = 37;i++;token = ">=";}break;case'<':syn = 36;i++;token = "<";if (s[i] == '='){syn = 38;i++;token = "<=";}break;case'!':syn = -1;i++;if (s[i] == '='){syn = 40;i++;token = "!=";}break;case '"':syn = -1;token += s[i];i++;while (s[i] != '"'){if (s[i] == '#'){tag = 0;break;}else{token += s[i];i++;}}if (tag){token += s[i];i++;syn = 50;break;}else{syn = -1;cout << "双引号只存在一个,非法输入 " << endl;break;}case '#': //结束syn = 0;cout << "\n#结束" << endl;break;default:syn = -1;break;}}}}
@如果这篇文章能帮到你的话,可以点个赞给作者一个支持哦!也可以关注我~
希望大家少CV,多思考!





![[编译原理]词法分析器的分析与实现](https://img-blog.csdn.net/20150616134813310)