词法分析器
- 实验目的
- 单词分类表
- 单词结构描述
- 单词状态转换图
- 算法描述
- 程序结构
- 源代码
- 实验结果
实验目的
- 对C语言的一个子集设计并实现一个简单的词法分析器,掌握利用状态转换图设计词法分析器的基本方法。利用该词法分析器完成对源程序字符串的词法分析。
- 培养团队合作精神,体会协同工作在解决问题中的作用。
单词分类表
| 单词符号 | 种类 | 种别码 | 单词符号 | 种类 | 种别码 |
|---|---|---|---|---|---|
| 未定义符号 | 未定义符号 | 0 | == | 运算符 | 17 |
| void | 关键字 | 1 | < | 运算符 | 18 |
| main | 关键字 | 2 | <= | 运算符 | 19 |
| int | 关键字 | 3 | > | 运算符 | 20 |
| double | 关键字 | 4 | >= | 运算符 | 21 |
| for | 关键字 | 5 | ( | 分界符 | 22 |
| while | 关键字 | 6 | ) | 分界符 | 23 |
| switch | 关键字 | 7 | [ | 分界符 | 24 |
| case | 关键字 | 8 | ] | 分界符 | 25 |
| if | 关键字 | 9 | { | 分界符 | 26 |
| else | 关键字 | 10 | } | 分界符 | 27 |
| return | 关键字 | 11 | , | 分界符 | 28 |
| + | 运算符 | 12 | ; | 分界符 | 29 |
| - | 运算符 | 13 | 整型常量 | 整型常量 | 30 |
| * | 运算符 | 14 | 浮点型常量 | 浮点型常量 | 31 |
| / | 运算符 | 15 | 标识符 | 标识符 | 32 |
| = | 运算符 | 16 |
单词结构描述
正规文法G[S]:
- S→关键字|运算符|分界符|整型常量|浮点型常量|标识符
- 关键字→ void|main|int|float|for|while|switch|case|if|else|return
- 运算符 → +|-|*|/|=|==|<|<=|>|>=
- 分界符 → (|)|[|]|{|}|,|;
- 整型常量 → digit(digit)*
- 浮点型常量 → digit(digit).digit(digit)
- digit→ 0|1|2|3|4|5|6|7|8|9
- letter→ a|b|…|z|A|B|…|Z
- 标识符 → letter(letter|digit)*
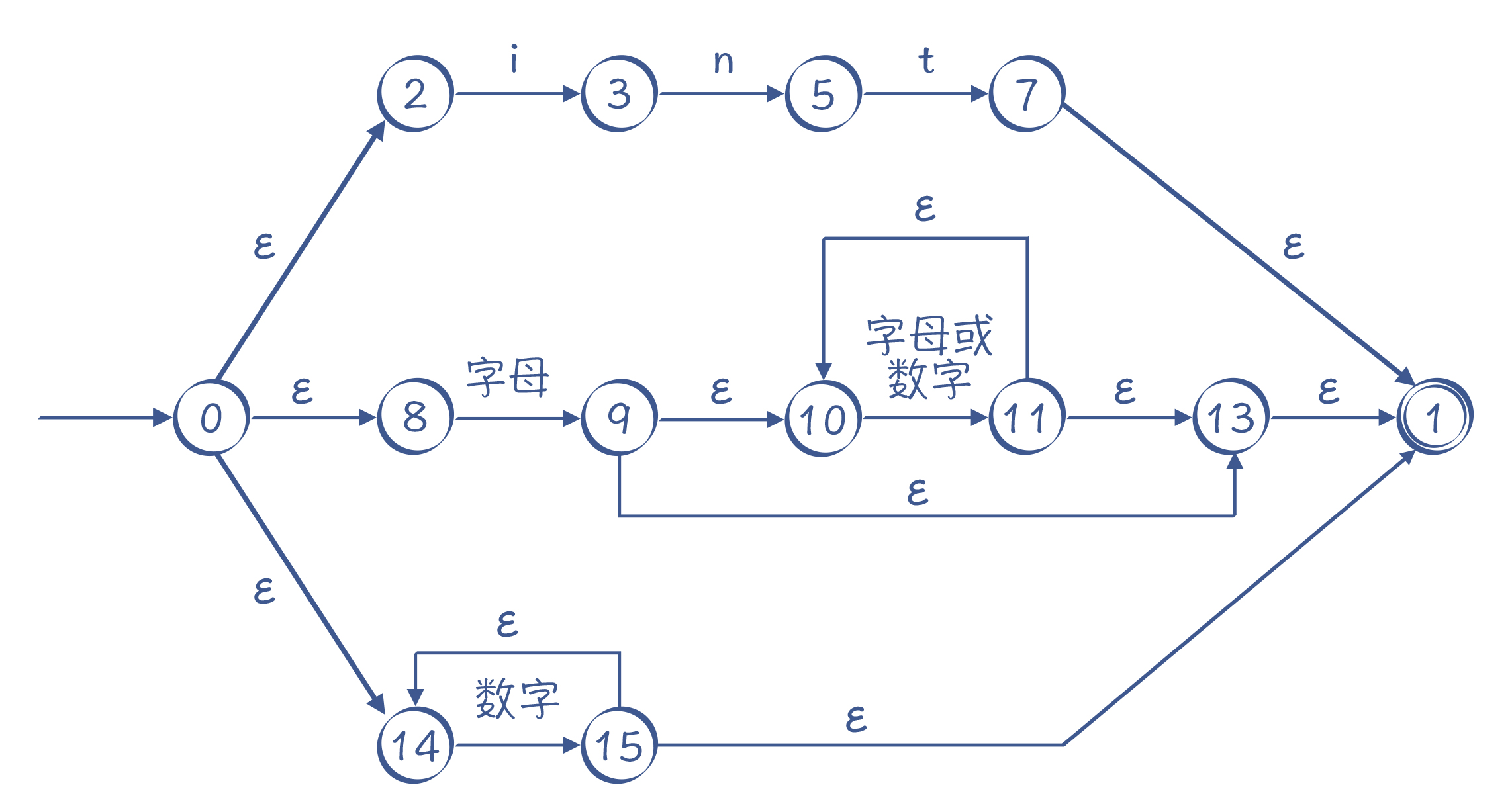
单词状态转换图

算法描述
- 读取文件到内存,逐个字符分析,若是空白符则跳过,为字母时将连续的字母使用超前搜索组合成为变量或关键字;若是数字,则要判断是否为浮点数,即使用超前搜索的时候,判断扫描到的字符是否为小数点;若是分隔符或者操作符,利用switch语句判断并输出,若是其他字符,输出为未定义的字符。
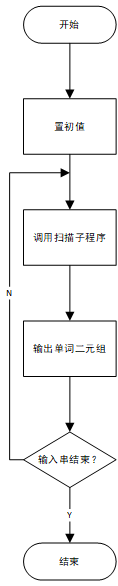
程序结构
TokenCode code = TK_UNDEF; //记录单词的种别码
int row = 1; //记录字符所在的行数
string token = “”; //用于存储单词符号构成的字符串
TokenCode枚举类型中定义了单词的种别码,keyWord中存储了关键字,分隔符、操作符利用switch语句判断。lexicalAnalysis函数用于词法分析,print函数用于打印输出结果。

源代码
- 目前在VS2017上测试通过,其他编译器可能不成功,代码是次要的,只要理解了思想,代码很容易写出来的
/***********************************************
* 词法分析器
* 编译环境:Visual Studio 2017
***********************************************/
#include <iostream>
#include <string>
#include <Windows.h>
using namespace std;/* 单词编码 */
enum TokenCode
{/*未定义*/TK_UNDEF = 0,/* 关键字 */KW_VOID, //void关键字KW_MAIN, //main关键字KW_INT, //int关键字KW_DOUBLE, //double关键字KW_FOR, //for关键字KW_WHILE, //while关键字KW_SWITCH, //switch关键字KW_CASE, //case关键字KW_IF, //if关键字KW_ELSE, //else关键字KW_RETURN, //return关键字/* 运算符 */TK_PLUS, //+加号TK_MINUS, //-减号TK_STAR, //*乘号TK_DIVIDE, ///除号TK_ASSIGN, //=赋值运算符TK_EQ, //==等于号TK_LT, //<小于号TK_LEQ, //<=小于等于号TK_GT, //>大于号TK_GEQ, //>=大于等于号/* 分隔符 */TK_OPENPA, //(左圆括号TK_CLOSEPA, //)右圆括号TK_OPENBR, //[左中括号TK_CLOSEBR, //]右中括号TK_BEGIN, //{左大括号TK_END, //}右大括号TK_COMMA, //,逗号TK_SEMOCOLOM, //;分号/* 常量 */TK_INT, //整型常量TK_DOUBLE, //浮点型常量/* 标识符 */TK_IDENT
};/******************************************全局变量*****************************************************/
TokenCode code = TK_UNDEF; //记录单词的种别码
const int MAX = 11; //关键字数量
int row = 1; //记录字符所在的行数
string token = ""; //用于存储单词
char keyWord[][10] = { "void","main","int","double","for","while","switch","case","if","else","return" }; //存储关键词/**********************************************函数*****************************************************//********************************************
* 功能:打印词法分析的结果
* code:单词对应的种别码
* token:用于存储单词
* row:单词所在的行数
*********************************************/
void print(TokenCode code)
{switch (code){/*未识别的符号*/case TK_UNDEF:SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_RED); //未识别的符号为红色cout << '(' << code << ',' << token << ")" << "未识别的符号在第" << row << "行。" << endl;return;break;/*关键字*/case KW_VOID: //void关键字case KW_MAIN: //main关键字case KW_INT: //int关键字case KW_DOUBLE: //double关键字case KW_FOR: //for关键字case KW_WHILE: //while关键字case KW_SWITCH: //switch关键字case KW_CASE: //case关键字case KW_IF: //if关键字case KW_ELSE: //else关键字case KW_RETURN: //return关键字SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_BLUE); //关键字为蓝色break;/* 运算符 */case TK_PLUS: //+加号case TK_MINUS: //-减号case TK_STAR: //*乘号case TK_DIVIDE: ///除号case TK_ASSIGN: //=赋值运算符case TK_EQ: //==等于号case TK_LT: //<小于号case TK_LEQ: //<=小于等于号case TK_GT: //>大于号case TK_GEQ: //>=大于等于号/* 分隔符 */case TK_OPENPA: //(左圆括号case TK_CLOSEPA: //)右圆括号case TK_OPENBR: //[左中括号case TK_CLOSEBR: //]右中括号case TK_BEGIN: //{左大括号case TK_END: //}右大括号case TK_COMMA: //,逗号case TK_SEMOCOLOM: //;分号SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_GREEN); //运算符和分隔符为绿色break;/* 常量 */case TK_INT: //整型常量case TK_DOUBLE: //浮点型常量SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_RED | FOREGROUND_GREEN); //常量为黄色if(token.find('.')==token.npos)cout << '(' << code << ',' << atoi(token.c_str()) << ")" << endl; //单词为整型elsecout << '(' << code << ',' << atof(token.c_str()) << ")" << endl; //单词为浮点型return;break;/* 标识符 */case TK_IDENT:SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY); //关键字为灰色break;default:break;}cout << '(' << code << ',' << token << ")" << endl;
}/********************************************
* 功能:判断是否是关键字
* MAX:关键字数量
* token:用于存储单词
*********************************************/
bool isKey(string token)
{for (int i = 0; i < MAX; i++){if (token.compare(keyWord[i]) == 0)return true;}return false;
}/********************************************
* 功能:返回关键字的内码值
* MAX:关键字数量
* token:用于存储单词
*********************************************/
int getKeyID(string token)
{for (int i = 0; i < MAX; i++){ //关键字的内码值为keyWord数组中对应的下标加1if (token.compare(keyWord[i]) == 0) return i+1;}return -1;
}/********************************************
* 功能:判断一个字符是否是字母
* letter:被判断的字符
*********************************************/
bool isLetter(char letter)
{if ((letter >= 'a'&&letter <= 'z') || (letter >= 'A' &&letter <= 'Z'))return true;return false;}/********************************************
* 功能:判断一个字符是否是数字
* digit:被判断的字符
*********************************************/
bool isDigit(char digit)
{if (digit >= '0'&&digit <= '9')return true;return false;
}/********************************************
* 功能:词法分析
* fp:文件指针
* code:单词对应的种别码
* token:用于存储单词
* row:单词所在的行数
*********************************************/
void lexicalAnalysis(FILE *fp)
{char ch; //用于存储从文件中获取的单个字符while ((ch = fgetc(fp)) != EOF) //未读取到文件尾,从文件中获取一个字符{token = ch; //将获取的字符存入token中if (ch == ' ' || ch == '\t' || ch == '\n') //忽略空格、Tab和回车{if (ch == '\n') //遇到换行符,记录行数的row加1row++;continue; //继续执行循环}else if (isLetter(ch)) //以字母开头,关键字或标识符{token = ""; //token初始化while (isLetter(ch) || isDigit(ch)) //非字母或数字时退出,将单词存储在token中{token.push_back(ch); //将读取的字符ch存入token中ch = fgetc(fp); //获取下一个字符}//文件指针后退一个字节,即重新读取上述单词后的第一个字符fseek(fp, -1L, SEEK_CUR);if (isKey(token)) //关键字code = TokenCode(getKeyID(token));else //标识符code = TK_IDENT; //单词为标识符}else if (isDigit(ch)) //无符号常数以数字开头{int isdouble = 0; //标记是否为浮点数token = ""; //token初始化while (isDigit(ch)) //当前获取到的字符为数字{token.push_back(ch); //读取数字,将其存入token中ch = fgetc(fp); //从文件中获取下一个字符//该单词中第一次出现小数点if (ch == '.'&& isdouble == 0){//小数点下一位是数字if (isDigit(fgetc(fp))){isdouble = 1; //标记该常数中已经出现过小数点fseek(fp, -1L, SEEK_CUR); //将超前读取的小数点后一位重新读取 token.push_back(ch); //将小数点入token中ch = fgetc(fp); //读取小数点后的下一位数字}}}if (isdouble == 1)code = TK_DOUBLE; //单词为浮点型elsecode = TK_INT; //单词为整型//文件指针后退一个字节,即重新读取常数后的第一个字符fseek(fp, -1L, SEEK_CUR);}else switch (ch){ /*运算符*/case '+': code = TK_PLUS; //+加号 break;case '-': code = TK_MINUS; //-减号break;case '*': code = TK_STAR; //*乘号 break;case '/': code = TK_DIVIDE; //除号break;case '=':{ch = fgetc(fp); //超前读取'='后面的字符if (ch == '=') //==等于号{token.push_back(ch); //将'='后面的'='存入token中code = TK_EQ; //单词为"=="} else { //=赋值运算符code = TK_ASSIGN; //单词为"="fseek(fp, -1L, SEEK_CUR); //将超前读取的字符重新读取}}break;case '<': {ch = fgetc(fp); //超前读取'<'后面的字符if (ch == '=') //<=小于等于号{token.push_back(ch); //将'<'后面的'='存入token中code = TK_LEQ; //单词为"<="} else { //<小于号code = TK_LT; //单词为"<"fseek(fp, -1L, SEEK_CUR); //将超前读取的字符重新读取}}break;case '>':{ch = fgetc(fp); //超前读取'>'后面的字符if (ch == '=') //>=大于等于号{token.push_back(ch); //将'>'后面的'='存入token中code = TK_GEQ; //单词为">="} else { //>大于号code = TK_GT; //单词为">"fseek(fp, -1L, SEEK_CUR); //将超前读取的字符重新读取}}break;/*分界符*/case '(': code = TK_OPENPA; //(左圆括号break;case ')': code = TK_CLOSEPA; //)右圆括号break;case '[': code = TK_OPENBR; //[左中括号break;case ']': code = TK_CLOSEBR; //]右中括号break;case '{': code = TK_BEGIN; //{左大括号break;case '}': code = TK_END; //}右大括号break;case ',': code = TK_COMMA; //,逗号break;case ';': code = TK_SEMOCOLOM; //;分号break;//未识别符号default: code = TK_UNDEF;}print(code); //打印词法分析结果}
}int main()
{string filename; //文件路径FILE* fp; //文件指针cout << "请输入源文件名:" << endl;while (true) {cin >> filename; //读取文件路径if ((fopen_s(&fp,filename.c_str(), "r"))==0) //打开文件break;elsecout << "路径输入错误!" << endl; //读取失败}cout << "/=***************************词法分析结果***************************=/" << endl;lexicalAnalysis(fp); //词法分析fclose(fp); //关闭文件SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_INTENSITY | FOREGROUND_RED | FOREGROUND_GREEN | FOREGROUND_BLUE); //字体恢复原来的颜色return 0;
}
- 测试数据
double add(double x, double y)
{double a = 3.456;return x + y;
}
$
int sum = 0;
for(int i = 1; i< 10; i = i + 1)
{sum = sum + i;
}
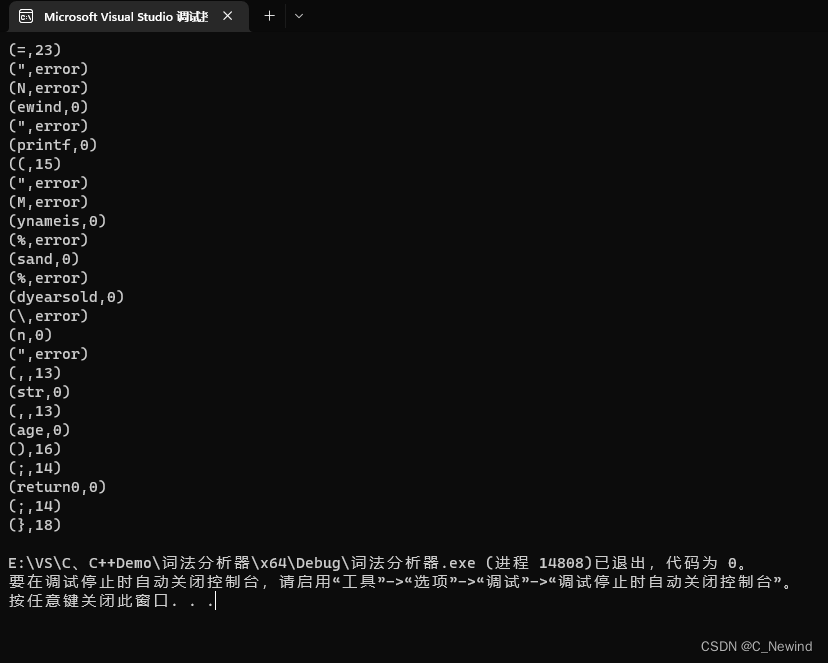
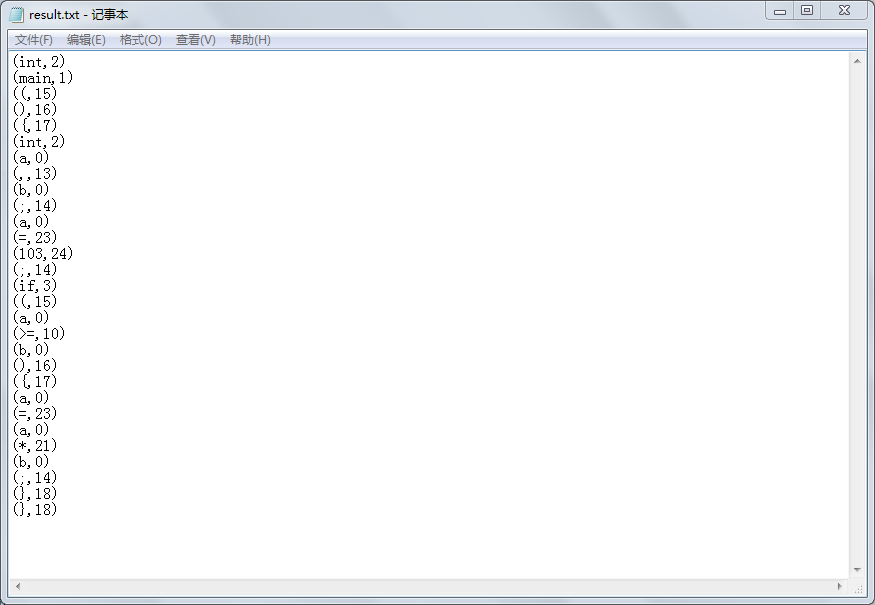
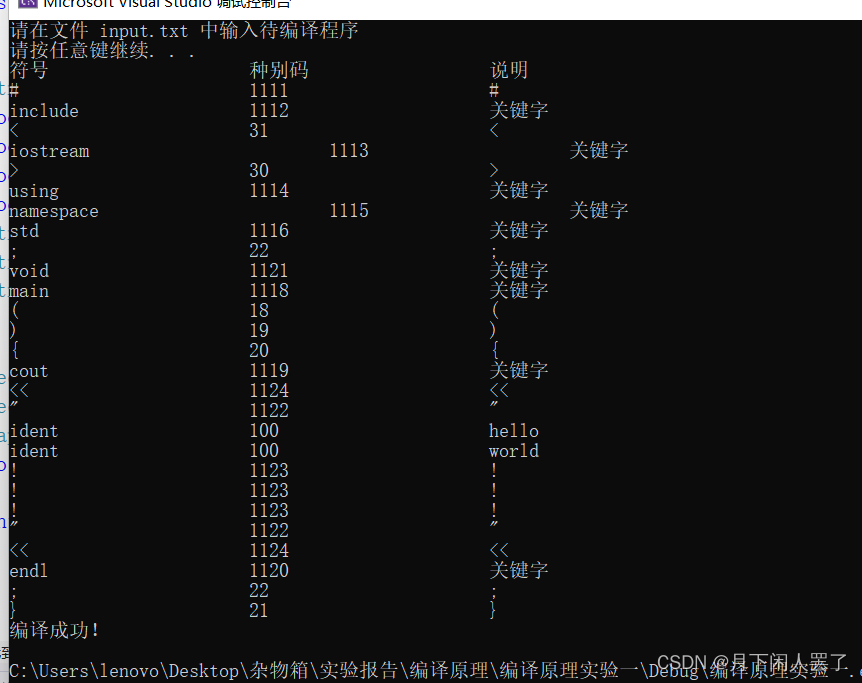
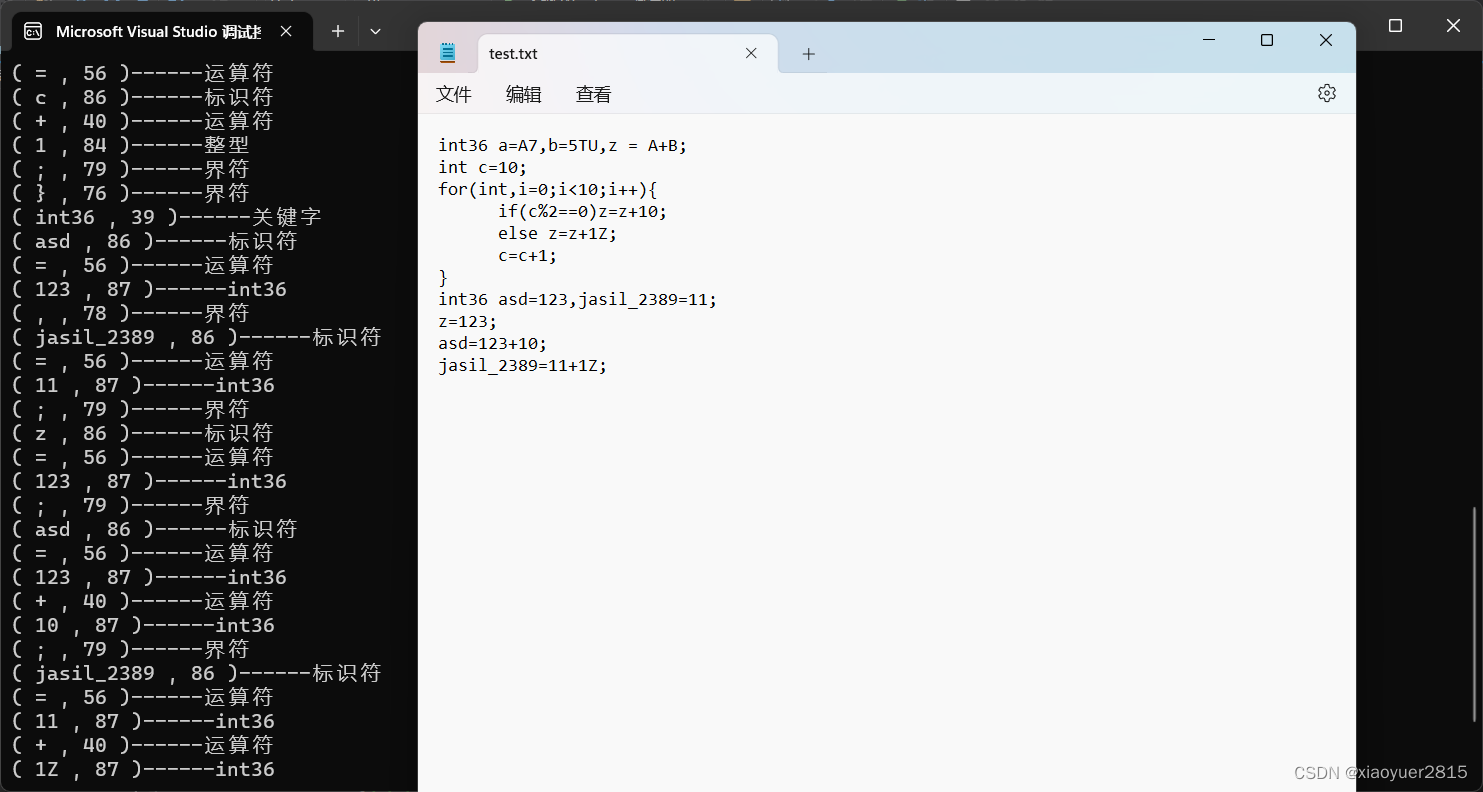
实验结果