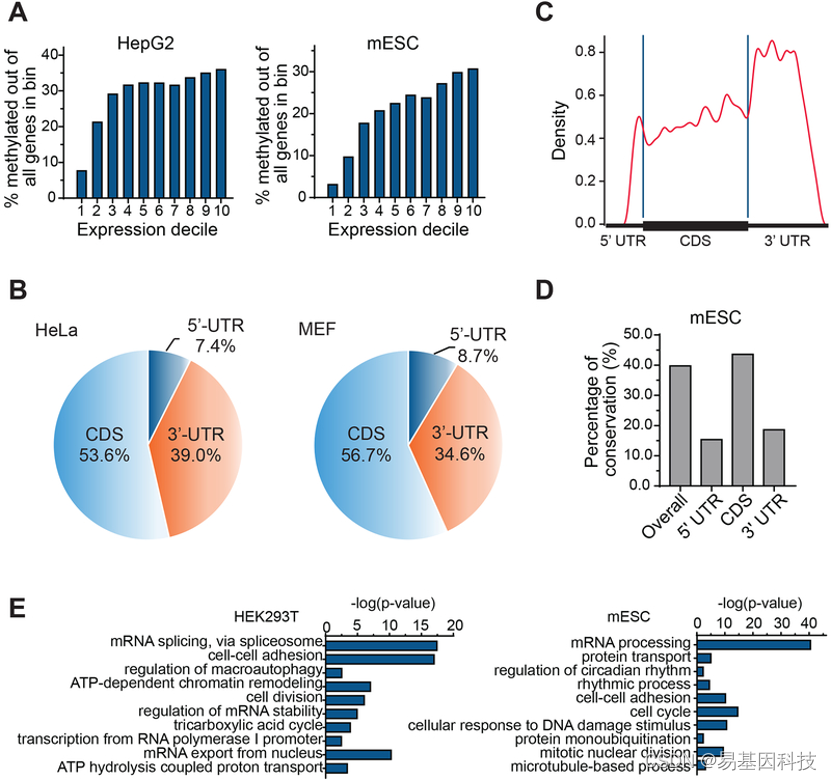
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- DISTINCT
- 语法:
- 关键词 distinct用于返回唯一不同的值。
- 表结构
- 案例
- SELECT DISTINCT age FROM emp1
- SELECT DISTINCT age ,NAME FROM emp1
- SELECT DISTINCT * FROM emp1
- COUNT统计
- SELECT COUNT(DISTINCT age) FROM emp1
- SELECT COUNT(DISTINCT NAME) FROM emp1
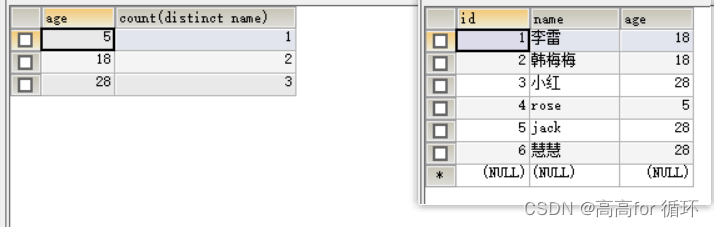
- SELECT age,COUNT(DISTINCT NAME) FROM emp1 GROUP BY age;
- group by 去重
- 用法:
- 表结构
- 案例:
- SELECT age, COUNT(age) FROM emp1 GROUP BY age;
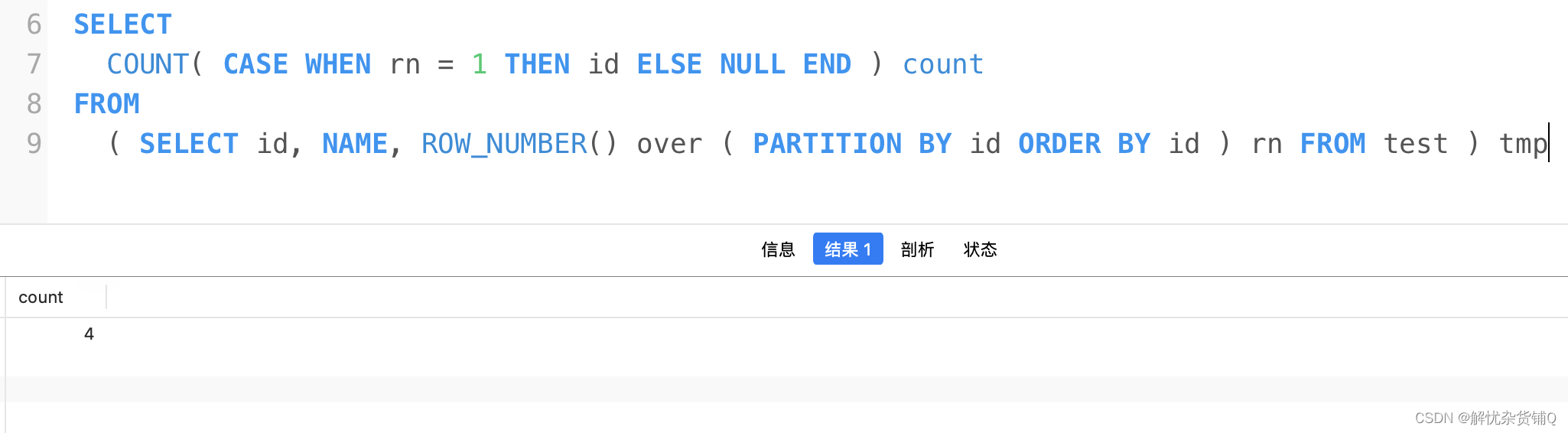
- 根据age去重 ,如果age重复,记录选id最小的
- 查找所有age重复的 记录
- SELECT age FROM emp1 GROUP BY age HAVING COUNT(*)>1
- 查找所有age不重复的 记录
- 删除重复的数据
- 1. age重复的数据,,,只保留id最小的,其余删除
- ==低版本 mysql 有可能报错==
- 2.只要age重复的数据 都删除,不保留
DISTINCT
语法:
关键词 distinct用于返回唯一不同的值。
- distinct必须放在开头
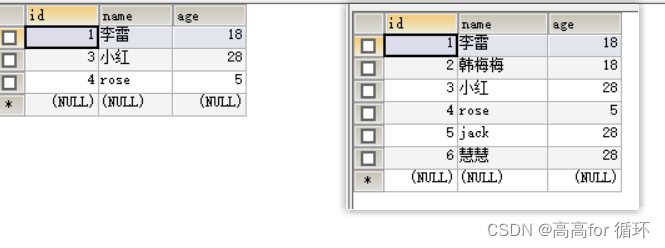
表结构
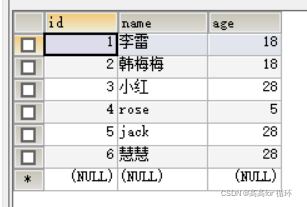
案例
SELECT DISTINCT age FROM emp1
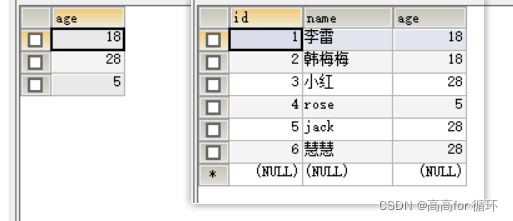
SELECT DISTINCT age ,NAME FROM emp1
实际上是根据age 和 NAME 两个字段来去重的
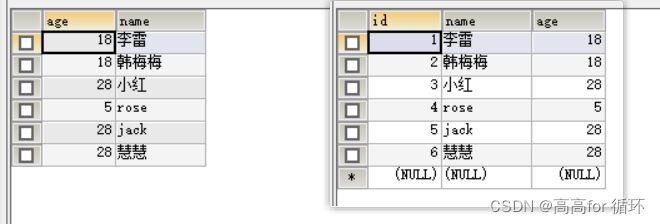
SELECT DISTINCT * FROM emp1
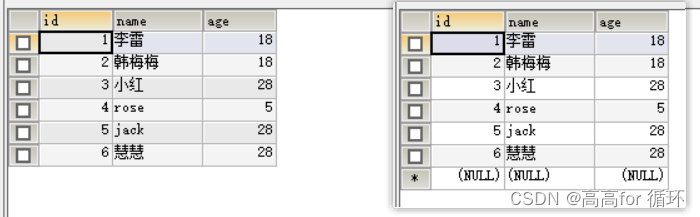
COUNT统计
- 统计字段列重复的个数
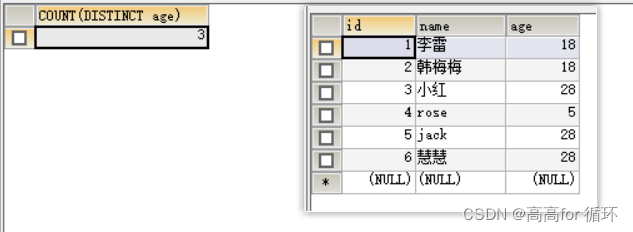
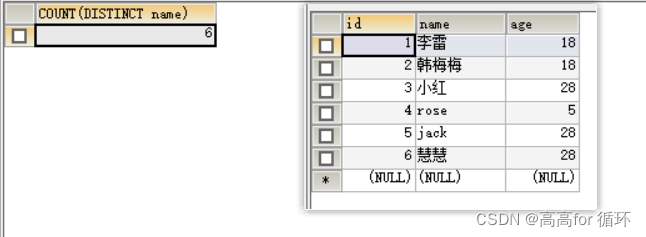
SELECT COUNT(DISTINCT age) FROM emp1
SELECT COUNT(DISTINCT NAME) FROM emp1
SELECT age,COUNT(DISTINCT NAME) FROM emp1 GROUP BY age;
group by 去重
用法:
表结构
案例:
SELECT age, COUNT(age) FROM emp1 GROUP BY age;
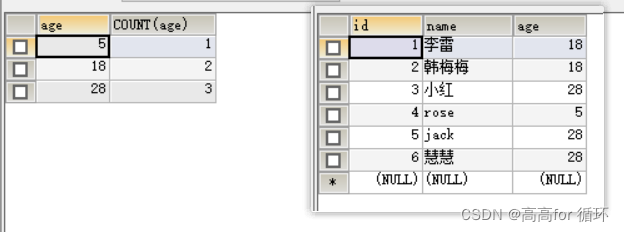
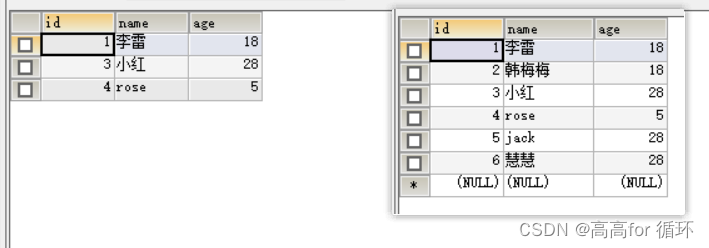
根据age去重 ,如果age重复,记录选id最小的
- 法1
SELECT * FROM emp1
WHERE id IN ( SELECT MIN(id) FROM emp1 GROUP BY age
)
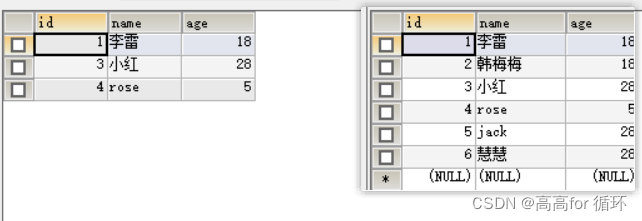
- 法2
SELECT t1.id ,t1.name ,t1.age
FROM (
SELECT id,NAME,age FROM emp1
) t1
INNER JOIN
( SELECT MIN(id) AS id FROM emp1 GROUP BY age
)t2 ON t1.id=t2.id
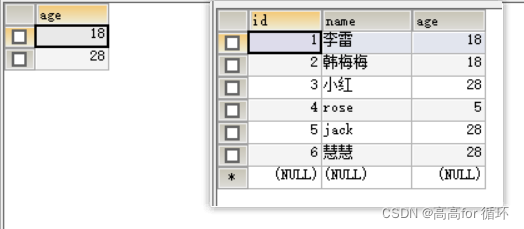
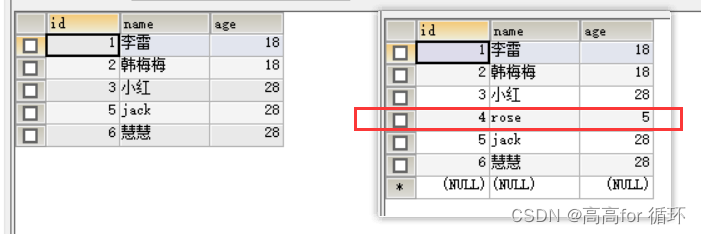
查找所有age重复的 记录
SELECT age FROM emp1 GROUP BY age HAVING COUNT(*)>1
- 方法1
SELECT * FROM emp1
WHERE age IN (SELECT age FROM emp1 GROUP BY age HAVING COUNT(*)>1
)
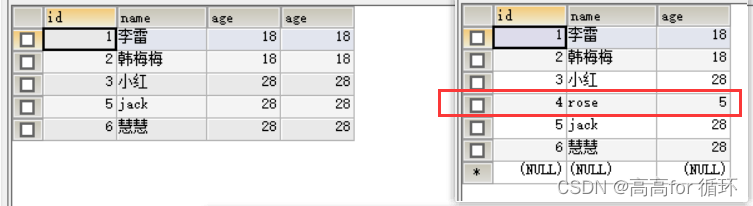
- 方法2
SELECT * FROM emp1 a
INNER JOIN (SELECT age FROM emp1 GROUP BY age HAVING COUNT(*)>1
)b ON a.age = b.age
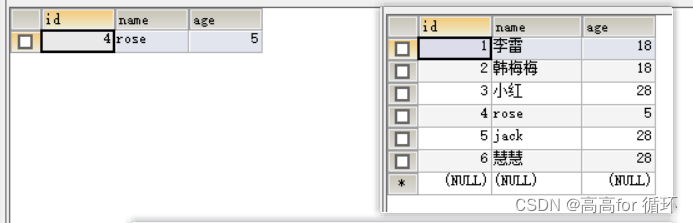
查找所有age不重复的 记录
- 方法1
SELECT * FROM emp1
WHERE age NOT IN (SELECT age FROM emp1 GROUP BY age HAVING COUNT(*)>1
)
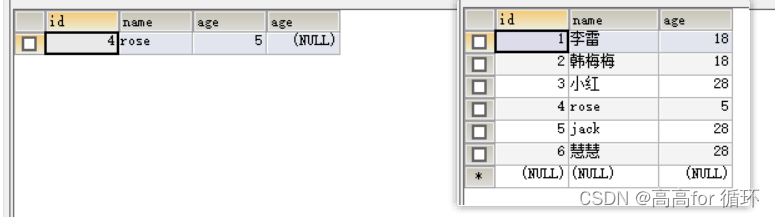
- 方法2
SELECT * FROM emp1 a
LEFT JOIN (SELECT age FROM emp1 GROUP BY age HAVING COUNT(*)>1
)b ON a.age = b.age
WHERE b.age IS null
删除重复的数据
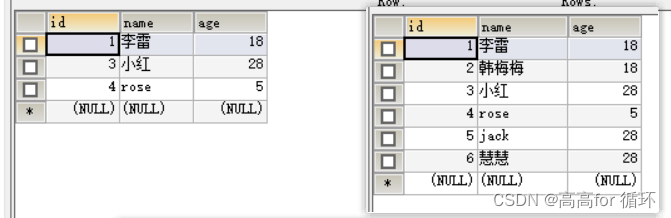
1. age重复的数据,只保留id最小的,其余删除
DELETE FROM emp1
WHERE id NOT IN(SELECT MIN(id) minid FROM emp1
GROUP BY age
)
低版本 mysql 有可能报错

解决方法是:需要先把查询处理的id结果,as 一张表,再做delete操作,调整如下:
DELETE FROM emp1
WHERE id NOT IN
(SELECT a.id FROM (SELECT MIN(id)AS id FROM emp1 GROUP BY age ) a
)
2.只要age重复的数据 都删除,不保留
DELETE FROM emp1
WHERE age IN
( SELECT age AS id FROM emp1 GROUP BY age HAVING COUNT(*)>1
)