需求:MySQL去重查询只保留一条最新的记录
文章目录
- 易错的写法
- 正确的写法-1
- 正确的写法-2
- 正确的写法-3
易错的写法
表结构与初始数据如下SQL文件:
-- MySQL dump 10.13 Distrib 8.0.28, for Linux (x86_64)
--
-- Host: localhost Database: test01
-- ------------------------------------------------------
-- Server version 8.0.28-0ubuntu0.20.04.3/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!50503 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;--
-- Table structure for table `MyClass`
--DROP TABLE IF EXISTS `MyClass`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `MyClass` (`id` int NOT NULL AUTO_INCREMENT,`name` char(20) NOT NULL,`sex` int NOT NULL DEFAULT '0',`degree` double(16,2) DEFAULT NULL,`inserttime` text,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;--
-- Dumping data for table `MyClass`
--LOCK TABLES `MyClass` WRITE;
/*!40000 ALTER TABLE `MyClass` DISABLE KEYS */;
INSERT INTO `MyClass` VALUES (1,'Tom',0,96.45,'2022-02-19 18:00:00'),(2,'Joan',0,82.99,'2022-02-19 18:20:00'),(3,'Wang',0,96.59,'2022-02-19 18:30:00'),(4,'Tom',0,96.45,'2022-02-19 17:00:00'),(5,'Joan',0,82.99,'2022-02-19 18:25:00'),(6,'Wang',0,96.59,'2022-02-19 18:35:00');
/*!40000 ALTER TABLE `MyClass` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;-- Dump completed on 2022-02-20 4:35:15
SQL统计语句:
#全表扫描查询
SELECT * FROM test01.MyClass;
#根据'name'分组统计查询最新一条数据
SELECT * FROM test01.MyClass
WHERE name in (SELECT name FROM test01.MyClass GROUP BY name)AND inserttime in (SELECT max(inserttime) FROM test01.MyClass GROUP BY name);
全表扫描查询_结果:
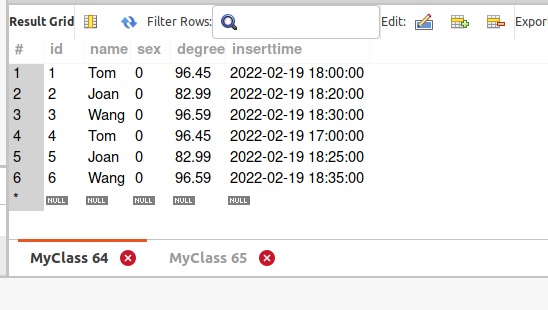
根据’name’字段去重统计查询最新数据_结果:
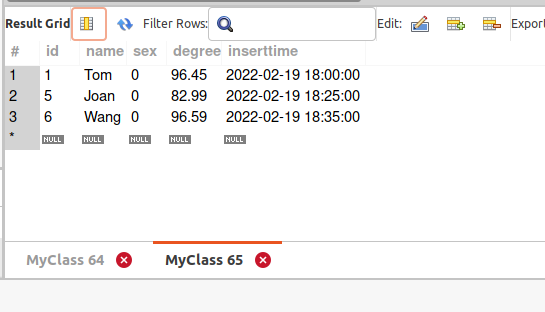
正确的写法-1
--------------------------------------------错误纠正UPDATE Sun May 1 00:28:18 CST 2022
初始数据如下:
[{"id":1, "name":"Tom", "sex":0, "degree":96.45, "inserttime":"2022-02-19 18:00:00"},{"id":2, "name":"Joan", "sex":0, "degree":82.99, "inserttime":"2022-02-19 18:20:00"},{"id":3, "name":"Wang", "sex":0, "degree":96.59, "inserttime":"2022-02-19 18:00:00"},{"id":4, "name":"Tom", "sex":0, "degree":96.45, "inserttime":"2022-02-19 17:00:00"},{"id":5, "name":"Joan", "sex":0, "degree":82.99, "inserttime":"2022-02-19 18:00:00"},{"id":6, "name":"Wang", "sex":0, "degree":96.59, "inserttime":"2022-02-19 18:35:00"},{"id":7, "name":"Wang", "sex":0, "degree":90.0, "inserttime":"2022-02-19 18:36:00"}]
#全表扫描查询
SELECT *
FROMtest01.MyClass
ORDER BY inserttime DESC;#根据'name'字段去重统计查询最新数据(错误的写法)
#SELECT * FROM test01.MyClass
#WHERE
# name in (SELECT name FROM test01.MyClass GROUP BY name)
# AND inserttime in (SELECT max(inserttime) FROM test01.MyClass GROUP BY name);#去重查询只保留一条最新的记录(正确的写法-1)
SELECT classtab.*
FROM(SELECT name, MAX(inserttime) inserttimeFROMtest01.MyClassGROUP BY name) tmpLEFT JOINtest01.MyClass classtab ON classtab.name = tmp.nameAND classtab.inserttime = tmp.inserttime;
#全表扫描查询_结果:
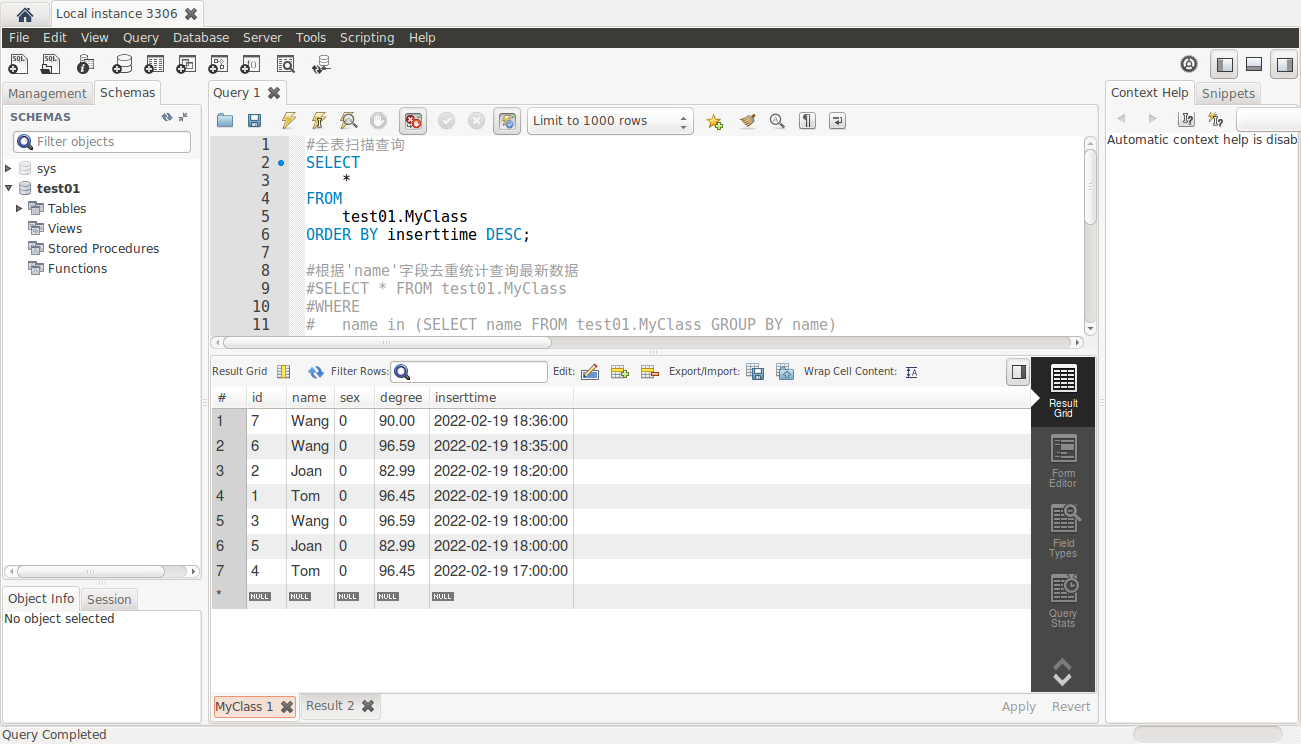
#去重查询只保留一条最新的记录(正确的写法-1)_结果:
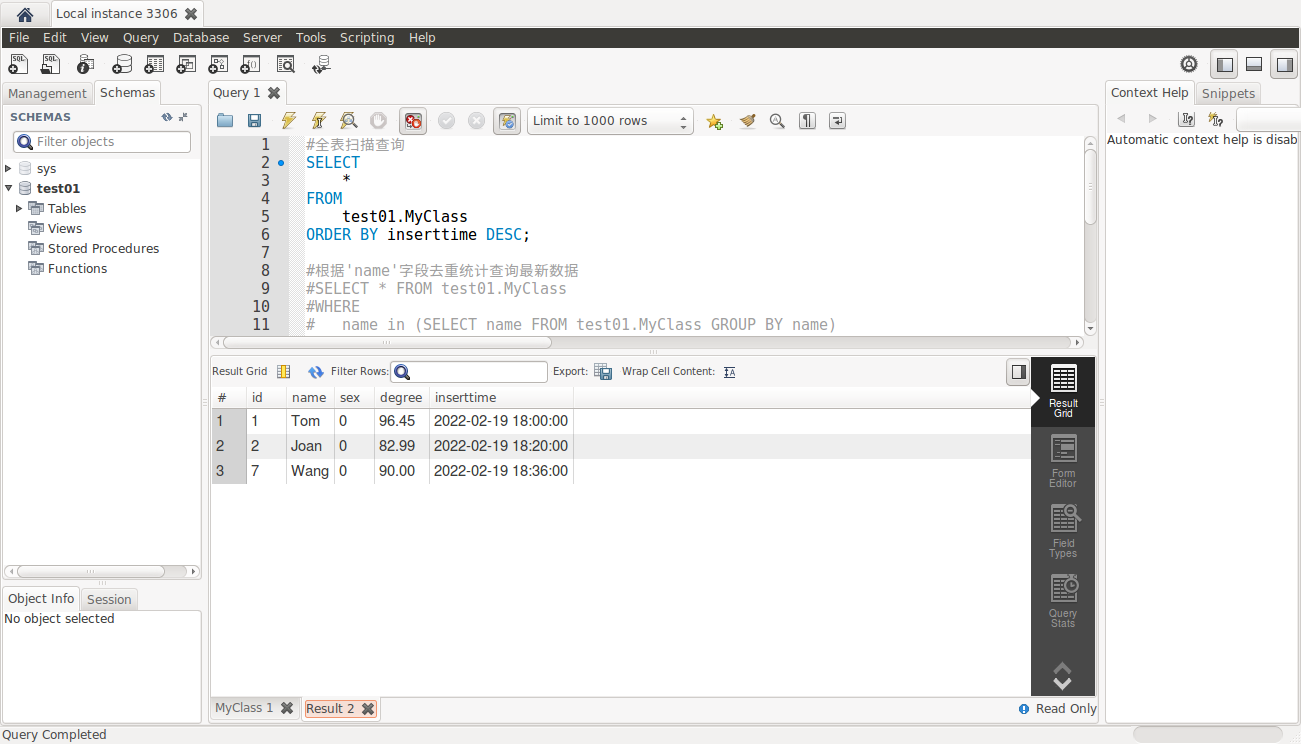
正确的写法-2
正确的写法-3
文末:若有错误请批评指正.