浅谈机器学习之数据集构建
正如大家现在知道的,深度学习模型(DL)和机器学习模型(ML)是数据驱动型任务,在近乎完美的数据集面前,模型间的细微差异可以忽略。但要获得覆盖目标场景所有特征的样本,不仅要耗费巨大的人力物力,而且往往也无法得到满意的效果。那么如何确定模型需要的最佳数据规模,就显得尤为重要。收集样本后,如何按比例构建数据集也是一个问题。
1 衡量数据集规模
无论是回归分析或计算机视觉任务,最优的做法都是,从已有开源数据集中提取相关数据,快速训练迭代出V1.0版本的模型,再利用V1.0模型进行测试,以此是否需要更多数据,需要什么类型的数据。
目前,根据前人的工作研究,总结的非数学统计意义上的规律,可按两种模型类型对样本量进行简单估计:
回归分析:根据 1/10 的经验规则,每个预测因子需要 10 个样例。
计算机视觉:以图像分类,经验法则是每一个分类需要 1000 幅图像,如果使用预训练的模型(导入ImageNet上的预训练参数),这个需求可以显著下降,具体样本量也要根据分类场景的目标特征复杂性决定。
明确任务指标,更好评估数据量
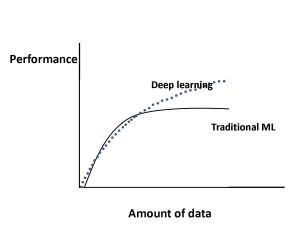
通常模型精度从70%提升到90%,需要的样本数量不多的,但精度要从90%再提高,需要的样本量成倍提高。这时候要放出下面这个图-模型性能与数据量的关系。从图中可以看出,对于传统的机器学习算法,性能是按照幂律增长的,一段时间后趋于平稳。 对于深度学习,随着数据量的增加性能如何变化。所以,只有当明确任务的指标-准确率、召回率、F1等,才能更好的衡量数据集的规模。
2 划分数据集
根据《结构化机器学习项目》中吴恩达老师的观点,在传统机器学习领域,模型参数较少,数据量在10,000左右,已经能得到较好的结果,所以可以采用train:dev:test = 6:2:2对数据进行划分。而对于深度学习任务,特别是基于深度学习的计算机视觉领域,模型参数动辄百万的参数量,数据集都达到百万样本级别,此时采用train:val:test=98:1:1对数据进行划分。简单总结如下:
样本量<10,000 时,train:val:test = 6:2:2
海量样本>1,000,000时,train:val:test=98:1:1
常用的机器学习中数据集划分的方法:留出法(Hold-out)、交叉验证法(cross validation)、自助法(bootstrap)
参考资料
[1]如何打造高质量的机器学习数据集? https://www.zhihu.com/question/333074061#!
[2]深度学习,怎么知道你的训练数据真的够了?https://easyai.tech/blog/how-do-you-know-you-have-enough-training-data/
[3]《结构化机器学习项目》- 吴恩达https://mooc.study.163.com/course/2001280004?tid=2403043000&trace_c_p_k2=626e816c55a344edbd74bcf0e8b0ae14#/info
ce_c_p_k2_=626e816c55a344edbd74bcf0e8b0ae14#/info



![虚拟机系统iso镜像下载_[原版镜像]macOS Mojave 10.14.1 原版 iso 镜像- 虚拟机专用](https://img-blog.csdnimg.cn/img_convert/7b7ffd819f295264c80e1a50d5872e2e.png)