博主原文链接:http://www.yourmetaverse.cn/nlp/128/

超越语言界限,ChatGPT进化之路
微软德国公司的首席技术官Andreas Braun在一场名为“AI in Focus - Digital Kickoff”的活动中活动中透露了这一消息,并表示下周将展示GPT的下一次迭代,它将是一个多模态模型,会提供完全不同的可能性——例如视频,这将允许用户创建新型的AI生成内容。他还表示,这项技术已经发展到基本上“适用于所有语言”,因此用户可以用一种语言提问,然后用另一种语言得到答案。这个消息迅速引起了全球科技界、投资者和普通用户的关注,他们都迫不及待地想知道新的GPT有多强大。
当前版本的ChatGPT仅限于基于文本的答案,并使用GPT-3.5。然而,在下一次迭代中,这个限制将被消除。据称,GPT-4将是一项重大更新,具备多模态模型能力,这将显着提升其能力,支持AI生成的视频和其他内容。
此外,就在昨天微软官方在Github开源了一个重量级的ChatGPT AI交互应用Visual ChatGPT。该应用短短一天在Github就达到了7000星。Visual ChatGPT调用ChatGPT以及一系列视觉基础模型来以实现在聊天过程中发送和接收图像,以及动态对图像进行处理。下面让我们一起来看看Visual ChatGPT有多强大吧。
1. Visual ChatGPT 原理(内容还在整理,后续更新中…)
具体内容参见:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models https://arxiv.org/abs/2303.04671
下面是本人的一些理解:
近年来,大型语言模型(LLM)的发展取得了惊人的进展,如T5,BLOOM和GPT-3。其中最重要的突破之一是ChatGPT,它建立在Instruct-GPT的基础上,专门训练用于与用户进行真正对话,从而使其能够维持当前对话的上下文,处理后续问题,并纠正其自身产生的答案。
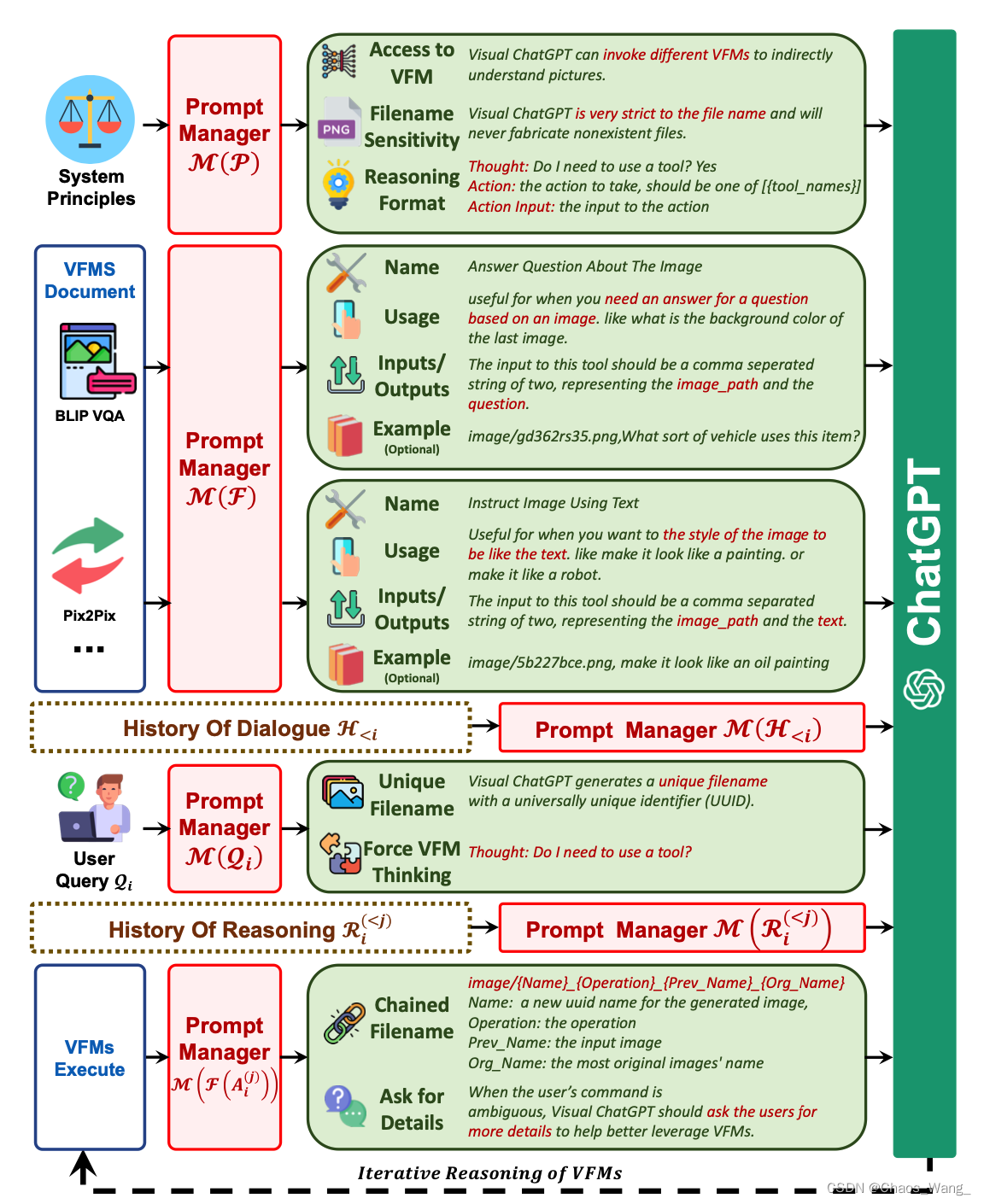
然而,由于ChatGPT是单一语言模态训练的,因此在处理视觉信息方面存在局限性,而视觉基础模型(VFMs)在计算机视觉方面具有巨大的潜力,具有理解和生成复杂图像的能力。因此,该文章提出了一个名为Visual ChatGPT的系统,通过将ChatGPT与不同的VFMs集成,使用户能够通过除了语言格式之外的其他方式与ChatGPT进行交互,以解决复杂的视觉问题。Prompt Manager是该系统的关键组成部分,用于协调ChatGPT和VFMs之间的交互,并支持不同视觉格式之间的转换。
通过大量的实验和案例,文章证明了Visual ChatGPT在不同任务中的巨大潜力和能力。同时,该系统也存在一些局限性和问题,如VFMs的不稳定性和自我纠正模块对推理时间的影响,但作者表示将在未来解决这些问题。
虽然ChatGPT在处理自然语言上具有出色的对话能力和推理能力,但它无法处理或生成来自视觉世界的图像。同时,Visual Foundation Models(例如Visual Transformers或Stable Diffusion)虽然在视觉理解和生成方面表现出色,但它们只是特定任务的专家,并且只能接受一次固定输入和输出。为此,作者们创建了一个名为Visual ChatGPT的系统,结合了不同的Visual Foundation Models,使用户能够通过1)发送和接收语言和图像;2)提供需要多个AI模型协作多个步骤的复杂视觉问题或视觉编辑指令;3)提供反馈并要求纠正结果。作者们设计了一系列提示,将视觉模型信息注入ChatGPT,考虑到多个输入/输出模型和需要视觉反馈的模型。实验表明,Visual ChatGPT为研究ChatGPT在视觉角色方面的作用打开了大门。
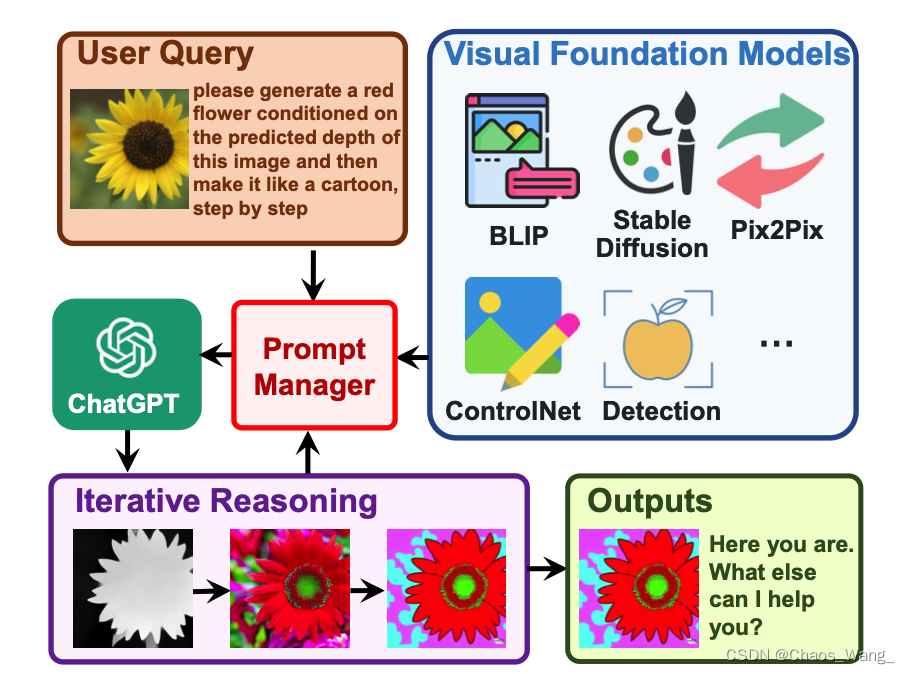
如图所示,用户上传了一张黄色花朵的图像,并输入了一个复杂的语言指令“请根据预测的深度生成一朵红色花朵,并将其变成卡通风格逐步完成”。在Prompt Manager的帮助下,Visual ChatGPT开始执行相关的Visual Foundation Models。在这种情况下,它首先应用深度估计模型来检测深度信息,然后利用深度到图像模型生成具有深度信息的红花图像,最后利用基于Stable Diffusion模型的风格转移VFM将该图像的样式改变为卡通形式。在上述管道过程中,Prompt Manager通过提供视觉格式的类型并记录信息转换的过程,作为ChatGPT的调度程序。最后,当Visual ChatGPT从Prompt Manager获得“卡通”提示时,它将结束执行管道并显示最终结果。
这篇文章的贡献如下:
- 提出了Visual ChatGPT,打开了将ChatGPT和视觉基础模型相结合的大门,使ChatGPT能够处理复杂的视觉任务;
- 设计了Prompt Manager,在其中涉及了22个不同的VFMs,并定义了它们之间的内部相关性,以更好地进行交互和组合;
- 进行了大量的零样本实验,并展示了Visual ChatGPT的理解和生成能力。
Visual ChatGPT架构由用户查询部分(User Query)、交互管理部分(Prompt Manger)、视觉基础模型(Visual Foundation Models,VFM)、调用ChatGpt API和迭代交互部分(Iterative Reasoning),最后是用户输出(Outputs)部分。
整个系统流程是:
- 明确告诉 ChatGPT 每个 VFM 的能力并指定输入输出格式;
- 将不同的视觉信息,例如pngimages,深度图像和mask矩阵,转换为语言格式以帮助ChatGPT理解;
- 处理不同视觉基础模型的历史、优先级和冲突。
在交互管理器的帮助下,ChatGPT可以利用这些VFMs并以迭代的方式接收他们的反馈,直到它满足用户的要求或达到结束条件。
2. Visual ChatGPT部署流程(Ubuntu系统按照以下流程本人亲试没问题)
(1) 首先安装git
Ubuntu环境下运行以下命令下载安装git git简介及常用命令介绍
apt-get install git
(2) 然后clone官方开源的Visual ChatGPT源码
运行以下代码下载官方源码:
git clone -b v1 https://github.com/microsoft/visual-chatgpt.git
(3)按照源码说明安装运行环境
进入visual-chatgpt目录
cd visual-chatgpt
然后运行下面命令安装运行环境:
conda create -n visgpt python=3.8
conda activate visgpt
pip install -r requirement.txt
注意,安装运行环境的时候如果需要GPU的话需要手动安装PyTorch的GPU版本。
(4) 下载必要的模型文件
bash download.sh
(5)设置ChatGPT的密钥
然后运行下面命令设置密钥
export OPENAI_API_KEY=Your_Private_Openai_Key
把Your_Private_Openai_Key替换成你的OpenAI账号里面生成的密钥就可以。
可以在这个网址获取Api_key:https://platform.openai.com/account/api-keys
这块一定要注意,官方给的说明里面Your_Private_Openai_Key带有{},这个不要放到命令里面,只需要按照我的说明替换一下即可。
如果是Windows用户的话需要再系统的高级设置里面的环境变量设置里面添加一个名字为OPENAI_API_KEY的环境变量,变量的值为Your_Private_Openai_Key。
(6)运行程序
创建一个文件夹接收图像文件:
mkdir ./image
在visual_chatgpt.py文件中,修改以下内容:
GPU的序号:
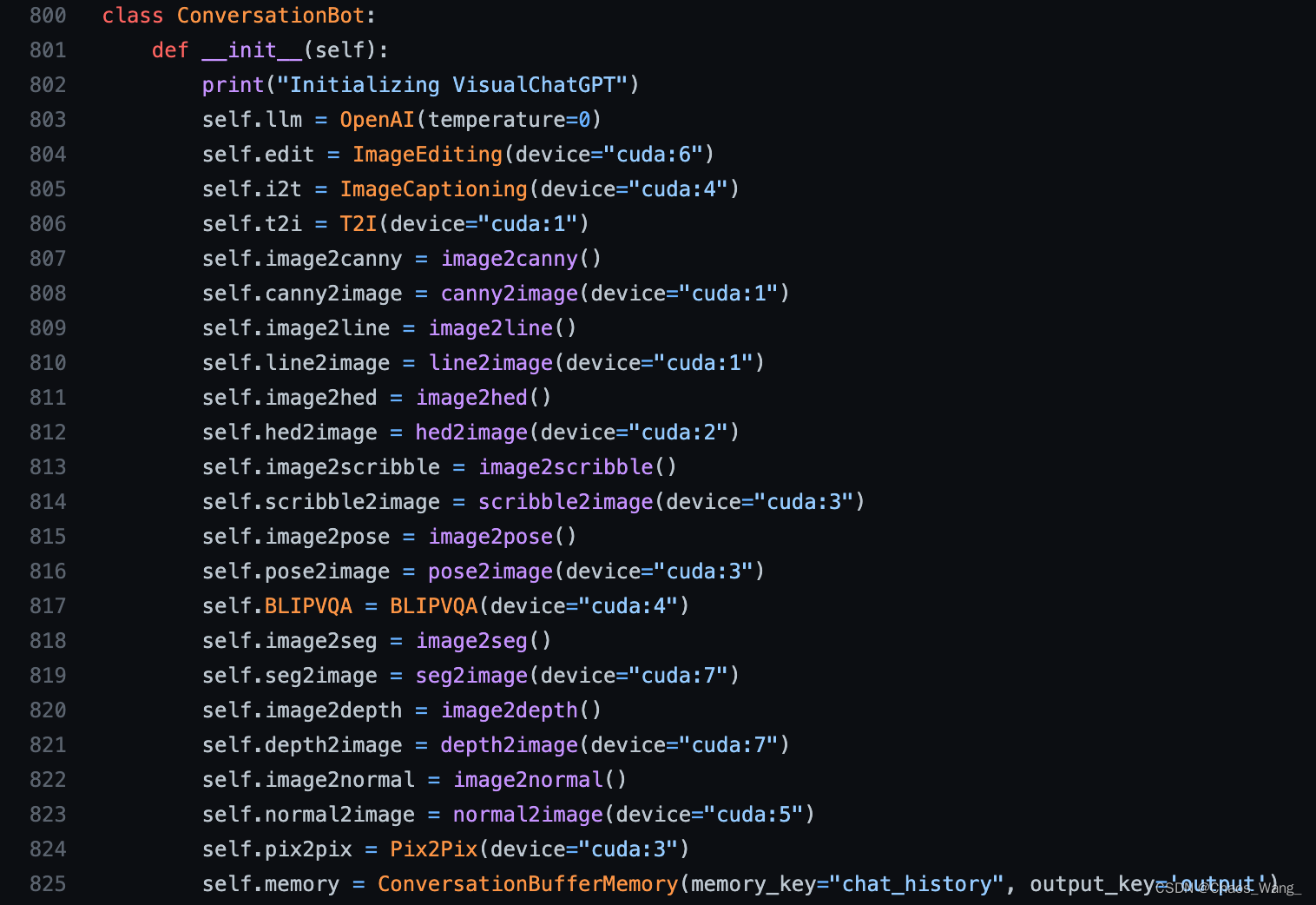
在visual_chatgpt.py中,用到了8个GPU,ID分别是0,1,2,3,4,5,6,7:
本人亲测并不需要这么多显卡,3个A100(40GB) GPU已经非常富裕了。
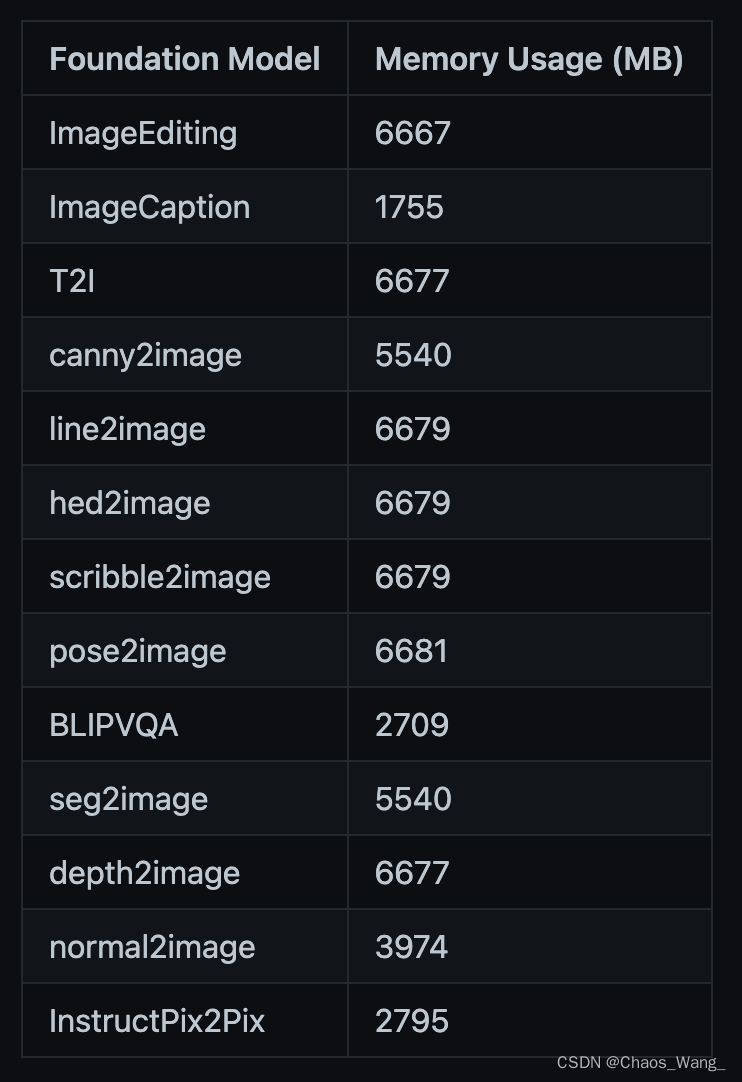
官方给的每个模型的GPU占用情况:
我按照顺序分别将GPU占用修改成0,1,2,这样只需要三个GPU就能完成部署。
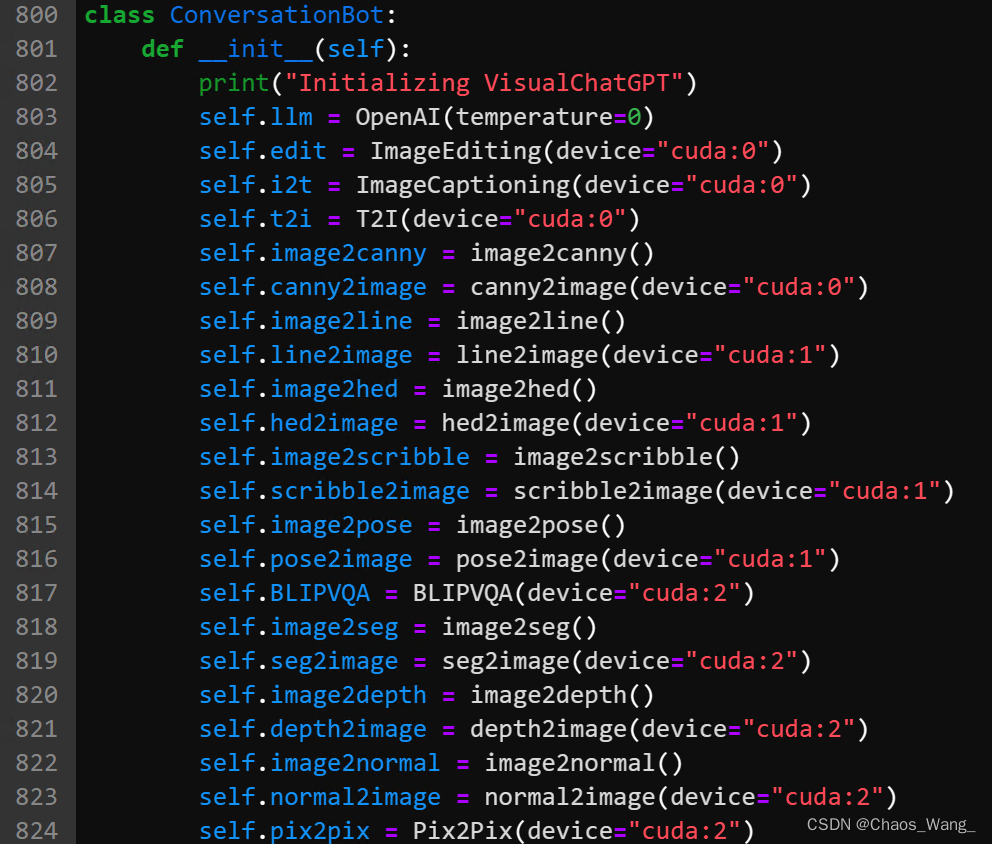
如果GPU不是特别富裕的话,极限情况下两个GPU(A100-40GB)也是完全可以的,只需要将前7个放到第一张显卡,后6个放到第二张显卡就可以。
部署的IP
修改最后一行的server_name和server_port为自己想要设定的即可,本地部署的话可以将server_name设定为127.0.0.1。
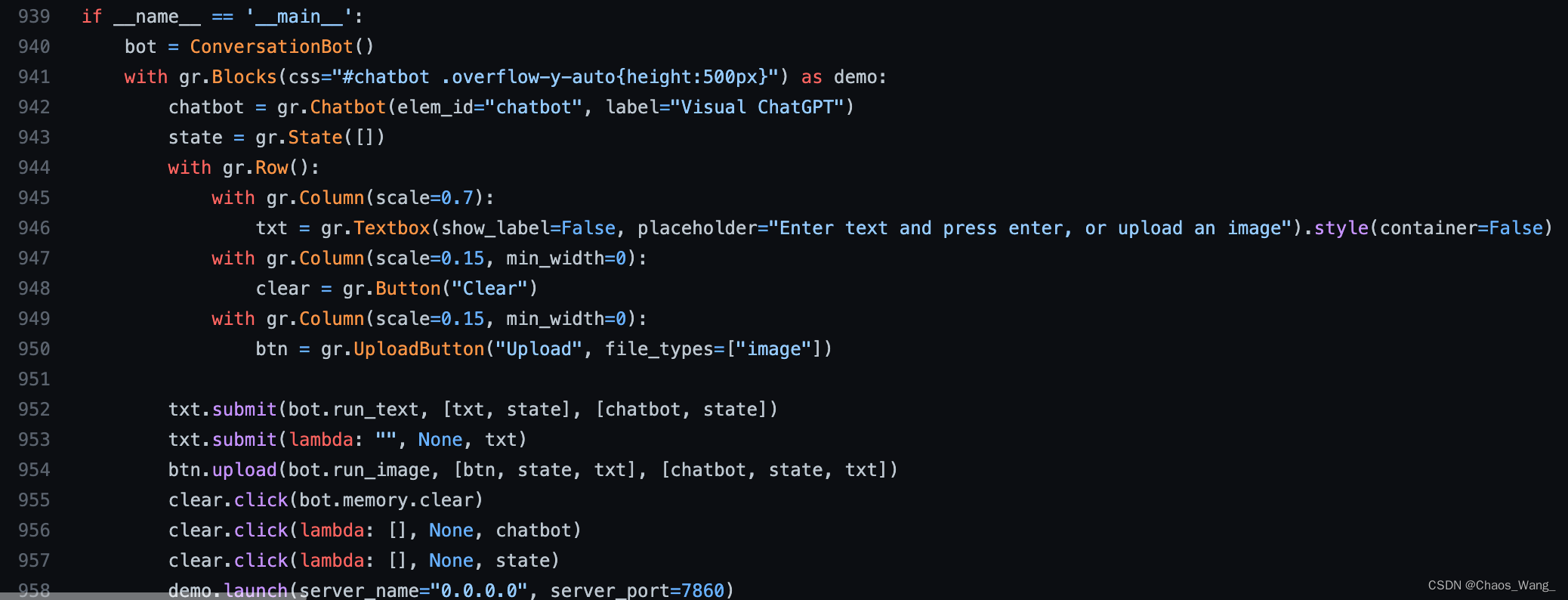
最后,运行下面的脚本运行程序
python visual_chatgpt.py
常见运行报错
如果出现:
ImportError: libSM.so.6: cannot open shared object file: No such file or directory
则运行下面脚本解决:
apt-get install build-essential libglib2.0-0 libsm6 libxext6 libxrender-dev
如果在docker环境中部署,在import cv2的时候会出现如下错误:
Importerror: libgl.so.1: cannot open shared object file: no such file or directory
使用下面命令解决:
apt-get install ffmpeg libsm6 libxext6 -y
参考文献
[1] Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models https://arxiv.org/abs/2303.04671
[2] visual-chatgpt https://github.com/microsoft/visual-chatgpt