ChatGPT这一现象级产品的热度在国内一路狂飙,不仅在技术界和商业界引起广泛讨论,还拉高了整个社会对AI的期待。不仅如此,这种大模型(LLM)所展现出的能力,给一些现有的技术和业务形态带来一种要被“降维打击”的焦虑,比如辅助写作工具、机器翻译、智能客服、语音助手等。如果说上述这些领域有的还只是潜在挑战的话,对搜索引擎而言则是战火已至,特别微软官宣了ChatGPT增强的New Bing之后,这一态势更为明朗。
一、ChatGPT对通搜和垂搜的价值
ChatGPT对搜索有哪些影响?
在去年ChatGPT刚出来的时候,一度有人乐观的认为会是井水不犯河水,毕竟它暂时无法做到信息的实时更新。差不多同时,有拥趸由于推崇ChatGPT的体验认为必然是取代关系。
而之后的发展逐渐清晰:大模型擅长信息的抽取、整合和流畅语言的生成,而搜索引擎擅长对整个网络的索引和最新信息的获取,因此让他俩发挥各自优势,互相外挂的思路成为主流。也就是说,原始信息仍然来自于搜索引擎,但大模型会负责整合不同网页的信息,并可以从特定网页中抽取细粒度的信息,生成答案给到用户。这也是New Bing[1]的思路。
而在技术研究侧,最为接近的一路研究是以WebGPT[2]为代表的让大模型学会上网的工作和用检索来增强的大模型(Retrieval augmented language model)的工作如REALM[3]和Altlas[4]. 当然除了技术层面带来的革新,ChatGPT这类大模型,给搜索引擎的商业模式带来的冲击可能更为巨大和根本,本文不做讨论,有兴趣的读者可以参考[5]和[6].
为什么ChatGPT对(通用)搜索有价值?
笔者浅见,在通搜中的一大部分流量里,用户打开搜索引擎的核心需求是:为了找到解决一个问题的答案(例如:“暑假带娃去哪里旅游”)。值得注意的是,答案可能在不同文档的某个细节处,而传统搜索引擎多数情况下只能给出文档列表,而这对于用户的需求来说,顶多只完成了50%。
因为对着一堆搜索结果,用户仍然需要(人肉)抽取对单个文档的关键信息,很多时候还需要对多个文档的知识整合后才能拿到答案。把这些环节交给ChatGPT为代表的大模型去做所,显然创造了实实在在的用户价值。
为了一探究竟,让我们简单回顾下ChatGPT这类对话式大模型的能力,进而分析为什么ChatGPT可以在这里创造价值。ChatGPT的能力,可以简单分为两层,一是GPT模型家族在InstructGPT[7]之前就有的能力,主要有:
通用的语言理解和生成能力:理解能力体现在可以完成包括信息抽取、文本分类在内的各类NLU任务,生成体现在完成常见的摘要、改写甚至直接生成流畅的文章。
相当程度世界知识和 一定的知识关联能力(包括简单推理)
在此基础上再通过指令学习(instruction tuning, [8][9])和带人类反馈的强化学习(reinforcement learning from human feedback, RLHF [10]),获得了遵循人类指令的能力(就是理解你要的是什么,并按要求来生成),于是就有了InstructGPT。再围绕对话数据做些调优,模型就获得了强大的连续对话能力和智能交互修正能力,也就得到了ChatGPT. 当然最后一步并没有公开文献,只是业内的一种合理猜测。
可以看到,ChatGPT的能力和通搜用户的痛点问题,也就是用户拿到文档后要(人肉)解决的那50%问题(单篇文档信息抽取和整合多个文档的知识等)是非常匹配的。
将ChatGPT集成进入搜索工作流,特别是以对话这种自然交互形式来解决这些问题,对用户帮助很大。因此不难理解,微软为什么采用外挂ChatGPT的方式将其整合进他家搜索。
内测一个月之后,这个外挂已经把Bing的DAU提升到了1亿,值得关注的是有1/3的内测用户是Bing的新用户[11],虽然长期效应还有待观察,但ChatGPT至少目前是个合格的拉新利器。
ChatGPT与垂直搜索
很多人包括笔者,都关心垂直搜索面临的挑战和机遇是否和通搜一样。垂搜个很泛的概念,本文主要讨论这类垂搜:商品搜索(如京东)、视频搜索(如腾讯视频)、音乐搜索(QQ音乐)等。
这类垂搜最明显的特点是:用户从某些特征维度(“完美世界”,“香港动作片”)或者某类需求(“适合情人节听的音乐”,“徒步装备”)出发,找到对应的资源。找到资源后就可以消费,这里的消费可以是加购/下单或者是播放等。可以看到垂搜和通搜有几点区别(表1):
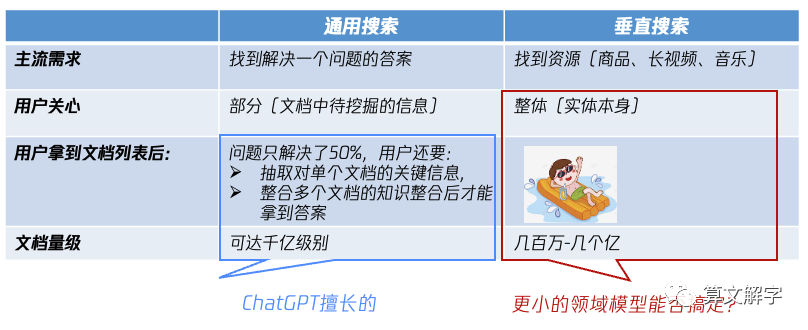
表1:通用搜索和垂直搜索的区别
正如先前的讨论,通搜里有一大块的需求是求答案,对用户有用的不是文档本身,而是其中待挖掘的信息;垂搜的主流需求是求资源,对用户有用的就是“文档”本身(广义的文档,指在网页和APP呈现的商品SKU、视频或音乐等,也可以称之为实体)。
因此就有下一条:通搜:展现出文档列表,往往只是解决问题的开始;垂搜:展现出搜索结果,解决搜索和信息获取的问题已经结束。当然还有众所周知的一点,就是两者要处理的文档量级不同,通搜可达千亿级别;垂搜的规模从百万到亿级的比较常见。
通过对比我们看到,垂搜中一大类需求是相对明确和集中的,就是找资源(商品、剧集、音乐等),拿到候选列表之后,并不像通搜中那样需要在去从单个资源中寻找信息点,以及整合多个资源的信息。换句话说,通搜中+ChatGPT外挂的方案所解决的问题并不是垂搜中的核心痛点,因此直接套用通搜的方案并不见得是好的选择。
ChatGPT技术可以为垂搜做什么?
那是不是说ChatGPT类的技术对垂搜就没有价值了呢?显然不是。大模型所带来的震撼体验,除了语言能力超强外,最亮眼的可能是两个:世界知识(包括知识关联)以及理解自然语言指令后输出合适的结果。那么,对于垂搜的核心需求“搜的准”,很自然就有问题A:是否可利用大模型的技术,享受到类似ChatGPT的红利呢,具体来说包括:
将垂直领域的知识内化在模型中,用户向模型提问,模型能直接给出准确的资源
同一个模型能理解用户不同场景中的需求,例如对精确搜索、按特征的泛意图查找、相关内容的推荐的请求,并给出合适的回答。
从最抽象的层面讲,享受类似ChatGPT的红利意味着从传统搜索转变为生成式搜索(generative IR),有时也被称之为端到端(end-to-end)搜索,如图2所示。端到端解决搜索的概念可能并不是这两年才有的,但基于transformer的大模型在互联网级别的语料上体现出来的记忆和泛化能力,开始让这件事变得可行。
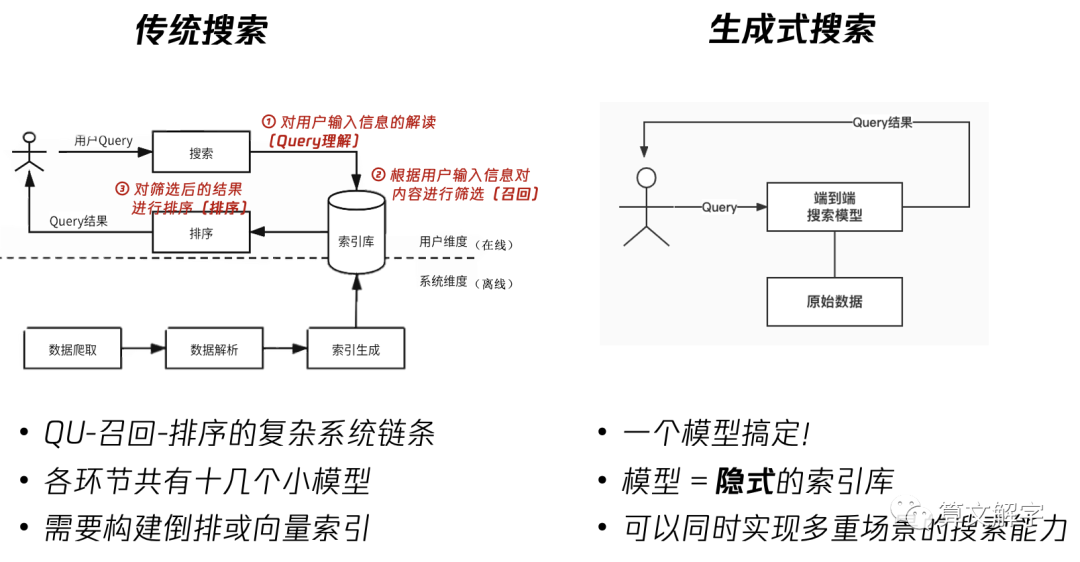
图2 传统搜索和生成式搜索
一个关键的考量是模型大小。由于垂直领域的文档规模和领域知识跟整个互联网相比仍然相当有限,那么自然会有问题B:有没有可能用一个较小的模型就来满足垂直领域的需求?
毕竟,一来大模型的成本,抛开训练成本不说,在互联网场景下的海量调用时的推断成本,目前还是很高的(感兴趣的读者可以套用GPT3.5 turbo API[20]的价格来计算一下);二来最近的研究也表明,现在的大模型参数相对于其训练数据规模可能是过量的,也就是说完全可以用更小的模型达到相同效果[12]。
以上问题A和B的答案都是肯定的。也就是说,针对垂搜的核心需求,笔者的提议是一种基于较小模型的生成式检索方案。这个方案与ChatGPT是一种技术上关联和取舍的关系(详见第二部分)。但是并不排斥有其他的方案,包括显式应用ChatGPT的垂搜方案,欢迎大家一起讨论。另外,本文只讨论垂搜,至于如何利用ChatGPT做垂直领域的创新应用,需要另文讨论。
生成式垂搜对业务的影响
在介绍具体做法之前,让我们先简单讨论这种方案对业务可能带来哪些影响。我们认为,生成式搜索有望解决传统搜索系统中三方面的问题:
模型分散:搜索是个复杂系的系统,预训练模型甚至是大模型其实在多数搜索引擎中已经有了广泛的应用。但是标准的架构中,模型都是来解决IR的子问题的:以纵向链条的角度,从QU中的纠错、改写、NER到召回,再到相关性等,系统少则有10+个模型在解决各种IR子问题;以横向产品模块的角度,不同的场景往往是通过设计不同的产品模块来满足,这进一步加剧了模型分散的现状。
数据割裂:场景层面,众所周知,垂搜也有很多场景,不同场景中的模块经常是独立迭代的,这导致搜索中的数据是割裂的,并未充分地统一利用;数据形式层面,结构化和非结构化数据(如知识图谱),缺乏有效的统一利用手段;再具体到一类特定的数据例子,标签体系,不同标签往往互不相通,无法兼容使用。
链路复杂:模型分散和数据割裂意味着链路是较为复杂,构建、维护的成本较高,而且多个模型运行,推断成本也相对较高。
如果能充分利用预训练语言的理解和知识整合能力,用一个模型来整体解决IR问题,则能统一融合各种场景数据来提升效果,同时单个模型替代若干模型,则能降低工程和推断成本。当然,生成式搜索由于技术较新,仍有文档更新机制不成熟、系统较为黑盒难debug等不足,这需要进一步的技术演进来解决,这在下节也有涉及。
二、生成式垂搜的技术实现
核心想法
既然生成式搜索有诸多优势,我们应该如何实现它的呢?如前文讨论这个问题其实分两个方面:
何实现生成式的检索?简单来说,就是从如何根据用户query生成doc的ID
如何实现多场景统一建模?就是让同一个模型能更“通才”,能同时解决不同场景的搜索问题(如精确搜索、按特征的泛意图查找、相关内容的推荐),这相应的也涉及如何整合多个场景中不同的结构化和非结构化的知识数据,让模型来统一来学习。
针对这两个问题,我们在腾讯视频搜索的实践中分别借鉴了IR和NLP领域的两个工作的思想,如图3所示。针对1,我们参考了可微分索引 (differentiable search index, DSI [13])思路,也就是将长视频索引内化为transformer模型的参数,并在预训练好的基座模型基础上,进一步训练,让模型学习到query的语义指向的是哪些doc ID.
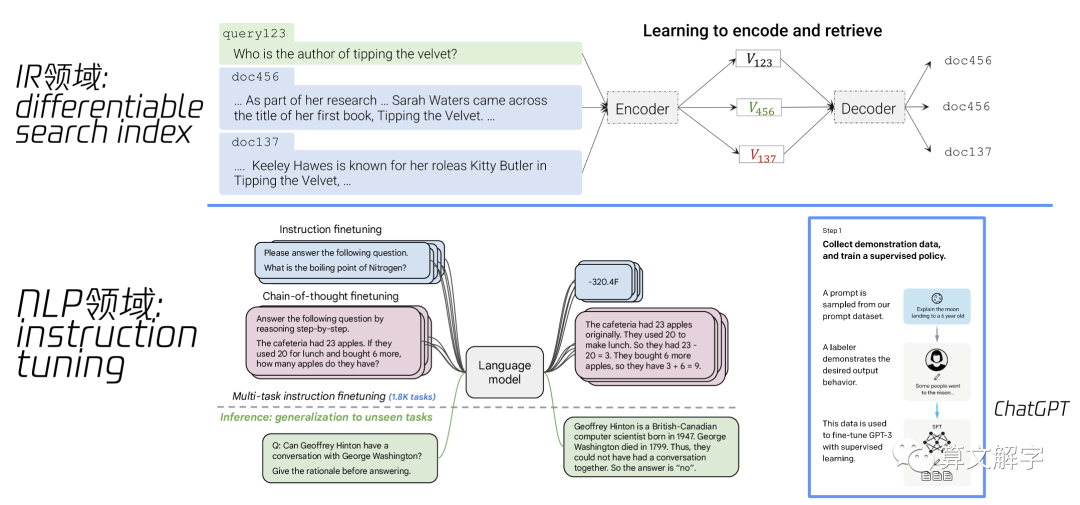
图3 可微分索引和指令微调
针对2,我们受到NLP领域中指令学习(instruction tuning, [8][9])的启发。原始的指令学习是把各种NLP的任务,包括文本分类、阅读理解、各种问答,甚至一些基于语言的符号推理、常识推理等若干任务和数据(细分任务数可达上千个),都转化为根据自然语言指令来生成文本的统一形式来精调预训练语言模型,让一个模型学会解决多种任务,并且可以get到自然语言指令中的用户意图,从而可以泛化到一些从未见过的新任务上。
与之类似,我们针对搜索场景,把精确搜索、按特征的泛意图搜索、相关内容推荐等大类的任务,以及主链路上的实体链接、纠错、相关性等搜索子任务都转化为自然语言指令下的生成任务来统一建模。
实际上,不仅是这种任务相关的数据(如搜索点击),知识图谱这类结构化的数据,也可以通过构造prompt来转化为自然指令-生成的任务。这种融合知识图谱数据到预训练模型的方法,跟传统的学习KG embedding再与预训练模型融合的方式如[14, 15]相比,更加简单也对预训练语言模型更友好。
结合以上两种思路,整体的方案如下面图4所示:
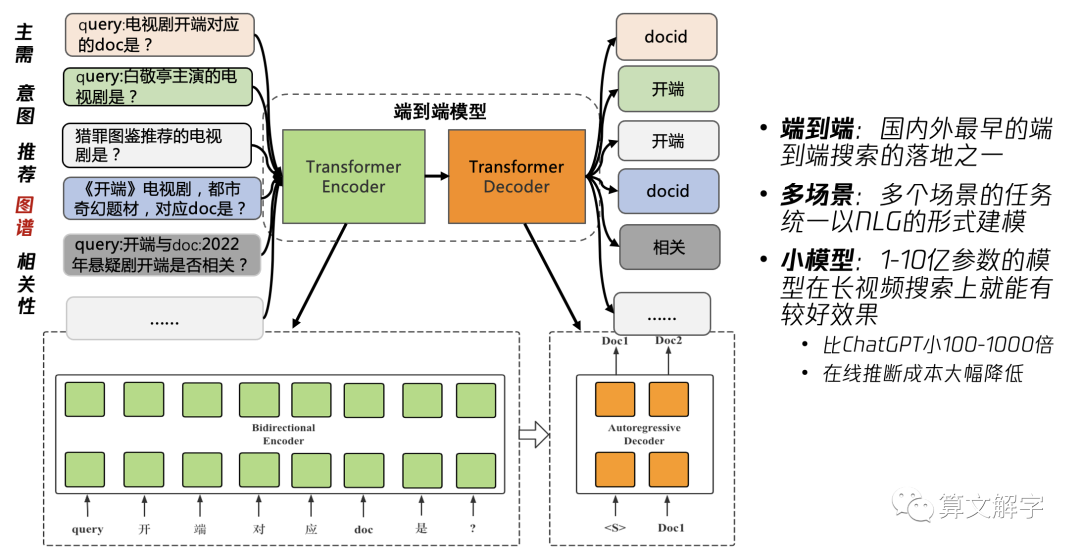
图4 腾讯视频的长视频生成式检索方案
Design Choice
当然,以上只是非常宏观的想法,在具体实现中,需要考虑的细节有很多,下面是笔者在项目开始的时候(2022年9月)思考过的一些技术细节的选择。在不影响阅读的前提下,笔者尽量原汁原味地呈现原始文档状态,欢迎大家来找茬。
需要说明的是,这些选择或者设计是针特定的问题、数据和资源在特定的时间点里做出的,现在回头看不一定最优,当然也肯定不是适合所有业务场景的, 感兴趣的读者可以思考适合自己场景的设计,并欢迎一起讨论。
1. 生成式 还是 分类式(理解式)
倾向于生成式。考虑如下:
优劣:生成式可以用同一形式来统一各种任务,灵活性更高,但训练难度可能更大;分类式更为常见和成熟,但不同任务可能需要不同的classification head(如MT-DNN[21]的做法),灵活与迁移能力可能更受限。
参考先前工作:
End-to-end IR的工作:
DSI[13]是基于T5的生成式,NCI是[16]在其基础上改进的的生成式
其他相关工作WebGPT[2]等也是生成式的,利用了生成式预训练的灵活迁移能力。
2. 基于哪个预训练模型?
公开的中文预训练模型较少,对于(生成式,中文)预训练模型的选择,需要调研和踩坑。涉及两个维度的选择:
模型结构,如GPT,T5,BART等
所采用的预训练预料
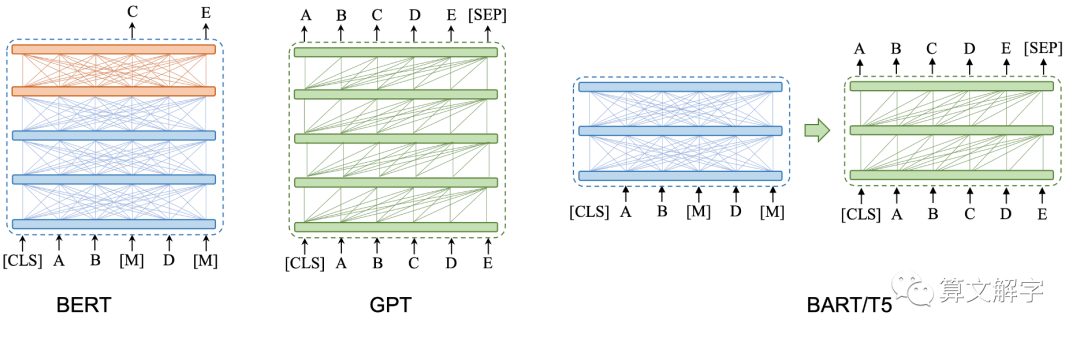
其中1是必须的,2是可选的,因为也可以在自有语料上从头pre-train模型(1-10亿参数)也是可行的。但对于已在大规模百科和网页语料上进行过预训练的模型,掌握一定的语言和世界知识,可能是一个捷径。当时考虑过的一些候选有:
CPT(BART Chinese)
T5(非官方)中文版
Chinese Transformer XL
Multilingual T5
......
这里需要关注的是,对比已有的支持中文的生成式语言模型及其源代码,重点考虑:(1)代码的易用性、可扩展性;(2)预训练模型的效果(可以先验性地考察它的训练数据,CS101 garbage in, garbage out,对预训练模型也不例外)。
3. 长视频表征
如何来表征长视频ID(cid)?两种极端的表示为:特殊token v.s. 纯文本。
特殊token是将每个cid作为一个新的、特殊token加入到预训练模型的词汇表中,通过预训练的过程学到这个token的表征。
优点:每个cid都有专有的token,表征学习充分;
缺点:cid的数量无法太大,否则训练和推断都太慢,冷启动较困难。
纯文本,就是将token作为普通的字符,走tokenizer,cid的表征就在普通的自然语言语义空间。
优点:不受cid数量级限制,冷启动总会有表征(质量另说);
缺点:ID类别很难有语言层面的语义,因此效果可能有折扣。
这里的一个现实考虑是,长视频IP数量一般也就百万量级,用特殊token似乎并无困难。在特殊token和纯文本之间还有其他状态,如DSI和NCI[13, 16]里采用的特殊数字编码,将新token数量降低到10个,利用token的组合来表示cid,每个doc的cid由一个基于层次聚类的编码过程得到。可以参考DSI工作中详细对比atomic docid(特殊token), native string docid(纯文本)和semantic string docid.
4. 搜索任务及其数据的instruction/prompt化
可以参考文献T0[17]的appendix G以及其最新版和工具。这里会跟业务及数据理解非常相关。构造instruction对效果的影响可能比模型调优更重要。关于如何混和不同任务里的数据,也可以参考[8, 9, 17]里的相关介绍。
不同任务的数据如何训练,考虑类似MT-DNN的方法,相同任务放到同一batch,然后相邻batch见任务交替进行训练。当然,图谱数据比较底层,一种可能性是图谱先finetune.
5. 预训练 v.s.精调
这里预训练和精调的界限有可能变的模糊。哪些数据/任务作为预训练,哪些作为精调?
一种极端是,拿一个现成的中文预训练模型为基础,之后的数据/任务都作为精调(可能依然要解决任务的依赖/时序关系)
另
一种极端,是用我们的数据(作为无标注的自监督语言模型数据,和有标注的task监督数据)从0开始预训练,类似ExT5[18]。
其实并不需要纠结pretraining, pre-finetuning[19]和fine-tuning的区别,这可能不是最重要的。这个工作要work的核心的想法是:多个任务都建模为NLG之后,不同任务的有监督数据,可以利用预训练模型来完成多任务学习。
所以一个好的起点是,直接用多任务构造的数据来统一做预训练(这里预训练和精调/prompt区分就模糊了),参考[17]中搞multi-task training的做法。
6. 其他问题
冷启动/doc增删改:一种思路是持续学习新的视频ID(cid)的表征,使用视频图谱的数据来持续训练。另外一个思路,是否可以考虑一种求冷启动不依赖学习新视频cid表征呢?doc的删除相对新增来说更容易实现。更新可能相对麻烦,当然也可以看做是先删除再更新。
生成cid列表:一些场景,如意图搜索和为你推荐均需要输出一个含有多个cid的有序列表,而不是仅仅一个最佳cid。第一版采用beam search或者sampling来搞这个,但后续肯定有更好的方式来改良。
instruction的生成:
是否可以学习promp(feature转化为文本)而不是用模版?
另外,之后是不是可以探索使用soft prompt?
......
业务效果
这个工作还在不断迭代中,截至本文撰写时,该模型在线上AB中已经多次取得核心指标的显著提升,已在腾讯视频搜索的两个场景中推全多次,其中最近一次推全对搜索整体观看时长有百分位的提升。
后记
文章写好后没多久GPT4就出来了,一周后还是决定分享出来,毕竟写作初衷也还是为了抛砖引玉:垂搜技术如何演进是一个开放性的话题,欢迎一起讨论。
参考文献和链接
[1] Reinventing search with a new AI-powered Microsoft Bing and Edge, your copilot for the web https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/
[2] Nakano, R. et al. (2021). WebGPT: Browser-assisted question-answering with human feedback. ArXiv, abs/2112.09332.
[3] Guu, K., Lee, K., Tung, Z., Pasupat, P., & Chang, M. (2020). REALM: Retrieval-Augmented Language Model Pre-Training. ArXiv, abs/2002.08909.
[4] Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., Schick, T., Yu, J.A., Joulin, A., Riedel, S., & Grave, E. (2022). Few-shot Learning with Retrieval Augmented Language Models. ArXiv, abs/2208.03299.
[5] 无人搜索,还是无人搜索 https://mp.weixin.qq.com/s/T1TovDnynoVvWwnR6_Onhw
[6] Microsoft targets Google’s search dominance with AI-powered Binghttps://www.ft.com/content/2d48d982-80b2-49f3-8a83-f5afef98e8eb
[7] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L.E., Simens, M., Askell, A., Welinder, P., Christiano, P.F., Leike, J., & Lowe, R.J. (2022). Training language models to follow instructions with human feedback. ArXiv, abs/2203.02155.
[8] Wei, J. et al. (2021). Finetuned Language Models Are Zero-Shot Learners. ArXiv, abs/2109.01652.
[9] Chung, H.W. et al. (2022). Scaling Instruction-Finetuned Language Models. ArXiv, abs/2210.11416.
[10] Stiennon, N., Ouyang, L., Wu, J., Ziegler, D.M., Lowe, R.J., Voss, C., Radford, A., Amodei, D., & Christiano, P. (2020). Learning to summarize from human feedback. ArXiv, abs/2009.01325.
[11] Microsoft's Bing Tops 100 Million Users With ChatGPT Integrationhttps://www.pcmag.com/news/microsofts-bing-tops-100-million-users-with-chatgpt-integration
[12] Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D.D., Hendricks, L.A., Welbl, J., Clark, A., Hennigan, T., Noland, E., Millican, K., Driessche, G.V., Damoc, B., Guy, A., Osindero, S., Simonyan, K., Elsen, E., Rae, J.W., Vinyals, O., & Sifre, L. (2022). Training Compute-Optimal Large Language Models. ArXiv, abs/2203.15556.
[13] Tay, Y., Tran, V.Q., Dehghani, M., Ni, J., Bahri, D., Mehta, H., Qin, Z., Hui, K., Zhao, Z., Gupta, J., Schuster, T., Cohen, W.W., & Metzler, D. (2022). Transformer Memory as a Differentiable Search Index. ArXiv, abs/2202.06991.
[14] Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., & Liu, Q. (2019). ERNIE: Enhanced Language Representation with Informative Entities. Annual Meeting of the Association for Computational Linguistics.
[15] Wang, X., Gao, T., Zhu, Z., Liu, Z., Li, J., & Tang, J. (2019). KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. Transactions of the Association for Computational Linguistics, 9, 176-19
[16] Wang, Y., et al. (2022). A Neural Corpus Indexer for Document Retrieval. ArXiv, abs/2206.02743.
[17] Sanh, V. et al. (2022). Multitask Prompted Training Enables Zero-Shot Task Generalization. ArXiv, abs/2110.08207.
[18] Aribandi, V., et al. (2022). ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning. ArXiv, abs/2111.10952.
[19] Aghajanyan, A. et al. (2021). Muppet: Massive Multi-task Representations with Pre-Finetuning. ArXiv, abs/2101.11038.
[20] Introducing ChatGPT and Whisper APIshttps://openai.com/blog/introducing-chatgpt-and-whisper-apis
[21] Liu, X., He, P., Chen, W., & Gao, J. (2019). Multi-Task Deep Neural Networks for Natural Language Understanding. Annual Meeting of the Association for Computational Linguistics.