0x00 Background
为什么研究这个?
ChatGPT在国内外都受到了广泛关注,很多高校、研究机构和企业都计划推出类似的模型。然而,ChatGPT并没有开源,且复现难度非常大,即使到现在,没有任何单位或企业能够完全复现GPT3的能力。最近,OpenAI发布了GPT4模型,它支持图文多模态,相较于ChatGPT,其能力大幅提升,似乎预示着第四次工业革命以通用人工智能为主导的到来。
无论是国内还是国外,与OpenAI的差距越来越大。大家都在竭力追赶,在这场技术革新中竞争激烈,目前许多大型企业都采取了闭源的研发策略。ChatGPT和GPT4的细节非常少,也不像之前发布论文时那么详细。OpenAI的商业化时代已经到来。当然,也有一些组织或个人在开源平台上进行了探索。本文将对这些探索进行总结,并将持续跟踪和更新开源平台的情况。
0x01
一种平价的chatgpt实现方案
下面推荐一下我最近看的几个比较火的大模型
ChatGLM
https://github.com/THUDM/ChatGLM-6B
ChatGLM是一个对话模型,由清华技术成果转化的公司智谱AI开源的GLM系列推出。该模型支持中英两个语种,并开源了其62亿参数量的模型。它不仅继承了之前GLM模型的优势,还在模型架构上进行了优化,从而使得它的部署和应用门槛更低,可以在消费级显卡上实现大模型的推理应用。具体的技术细节可以参考其Github页面。
从技术路线上看,ChatGLM实现了ChatGPT的强化学习人类对齐策略,使得生成效果更加贴近人类的价值。目前它的能力包括自我认知、提纲写作、文案写作、邮件写作助手、信息抽取、角色扮演、评论比较、旅游建议等。此外,该模型还开发了一个正在内测的1300亿的超大模型,是目前开源平台中参数规模最大的对话大模型之一。
LLAMA
LLaMA模型是一种基于自然语言处理技术的大型语言模型。该模型的名称是“Language Model for the Martian”(火星人的语言模型)的缩写。该模型由Meta(Facebook旗下的人工智能研究机构)发布,是一个由超过700亿个参数组成的预训练模型。
https://github.com/facebookresearch/llama
LLaMA模型在自然语言生成、对话生成、文本摘要、数学定理证明和蛋白质结构预测等任务上表现出色。与其他类似的语言模型相比,LLaMA模型具有更好的通用性和适用性,支持超过20种语言,包括英语、西班牙语、阿拉伯语、俄语和德语等多种语言。此外,LLaMA模型还支持使用不同的字母和符号系统,如拉丁字母、希腊字母、西里尔字母等。
在自然语言生成方面,LLaMA模型可以自动生成包括段落、故事、诗歌和对话等不同类型的文本。在文本摘要方面,LLaMA模型可以根据给定的文章自动生成简短的摘要。在数学定理证明方面,LLaMA模型可以生成相应的证明步骤和解释。在蛋白质结构预测方面,LLaMA模型可以根据蛋白质序列信息预测其三维结构。
LLaMA模型的发布对人工智能领域产生了重大影响,为自然语言处理技术的发展提供了有力支持。此外,LLaMA模型也为其他类似的大型语言模型的开发和应用提供了重要参考。
值得一提的是,LLaMA模型曾在2021年发生泄露事件,导致模型的数据被公开。该事件对人工智能领域产生了巨大的影响,推动了类ChatGPT的开源发展。
Alpaca
由于目前LLama的授权比较有限,只能用作科研,不允许做商用。
Alpaca(全称:Stanford Alpaca)是斯坦福大学发布的一种自然语言处理模型。该模型是基于LLaMA模型微调得出的一种模型。Alpaca的基本思想是让OpenAI的text-davinci-003模型以self-instruct方式生成大量指令样本,然后使用这些样本对LLaMA模型进行微调。
只用了52K的数据集,就训练出来了非常好的效果 https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
Alpaca的训练过程十分有趣。在训练过程中,研究人员将text-davinci-003模型暴力训练,让它根据自己的判断和指令生成一系列的指令样本,包括对话、文字、代码等。这些指令样本随后被用于微调LLaMA模型,从而提高其在特定任务上的性能。这种自我训练的方式使得Alpaca的微调过程不需要人工干预,大大降低了训练成本和时间。
Alpaca的模型文件目前还未被开源,但其训练数据、生成训练数据的代码和超参数已经在GitHub上公开。由于成本低廉、数据易得等特点,Alpaca的项目在自然语言处理领域受到了广泛的关注和赞誉。
stanford-alpaca
https://github.com/tatsu-lab/stanford_alpaca
alpaca-lora
斯坦福大学发布了另一个重要项目:alpaca-lora。
该项目使用 LoRA 技术重新实现了 Alpaca 的结果,并采用更低成本的方法,仅使用一块 RTX 4090 显卡进行 5 小时的训练,就得到了一个与 Alpaca 相当的模型。而且,该模型可以在树莓派上运行。该项目使用 Hugging Face 的 PEFT 实现了廉价高效的微调。PEFT 是一个支持 LoRA 技术的库,可以使用各种基于 Transformer 的语言模型并使用 LoRA 进行微调,从而在一般的硬件上实现廉价而有效的模型微调。该项目的 GitHub 地址是:https://github.com/tloen/alpaca-lora。
虽然 Alpaca 和 alpaca-lora 取得了较大的提升,但它们都是以英语作为种子任务,缺乏对中文的支持。为了解决这个问题,三位个人开发者从华中师范大学等机构开源了中文语言模型骆驼 (Luotuo)。该模型基于前人的工作,如 alpaca-lora,并可在单个显卡上进行训练和部署。该项目已经发布了两个模型:luotuo-lora-7b-0.1 和 luotuo-lora-7b-0.3,另一个模型也在计划中。该项目的 GitHub 地址是:https://github.com/LC1332/Chinese-alpaca-lora。
Vicuna和Chinese-Vicuna
斯坦福学者与CMU、UC伯克利等合作推出了一个全新模型,即130亿参数的Vicuna(俗称小羊驼、骆马)。这个模型可以通过在ShareGPT收集的用户共享对话上对LLaMA进行微调训练来得到。在测试过程中,使用GPT-4作为评判标准,结果显示Vicuna-13B在超过90%的情况下实现了与ChatGPT和Bard相匹敌的能力,而且仅需300美元就能实现ChatGPT 90%的性能。最近,UC伯克利LMSys org还发布了一个70亿参数的Vicuna,它不仅体积小、效率高、能力强,而且只需两行命令就能在M1/M2芯片的Mac上运行,还能开启GPU加速。这个项目的github开源地址为:https://github.com/lm-sys/FastChat/
另外,还有一个中文版的Vicuna被命名为Chinese-Vicuna,它也已经开源了,github地址为:https://github.com/Facico/Chinese-Vicuna
微调方案
模型微调的问题
这有几个微调的方案的结果对比:
也是

Abstract
Prompt turning通过在frozen language model上仅仅tuning 连续的 prompts可以減少前绪任务的
存储和训练中内存的消耗。然而,之前的工作揭示prompt tuning在正常大小的预训练模型的NLU
任务表现的并不好。本文也发现现有的prompt方法不能处理hard的序列标注问题,显示缺少通用
性。适当的优化prompt tuning可以有效的应用•在不同的模型scale和NLU任务上。文章提出的P-
Tuning V2不是一个新的方法是,是一个优化和改良的Pretix-tuning1版本。
Introduction
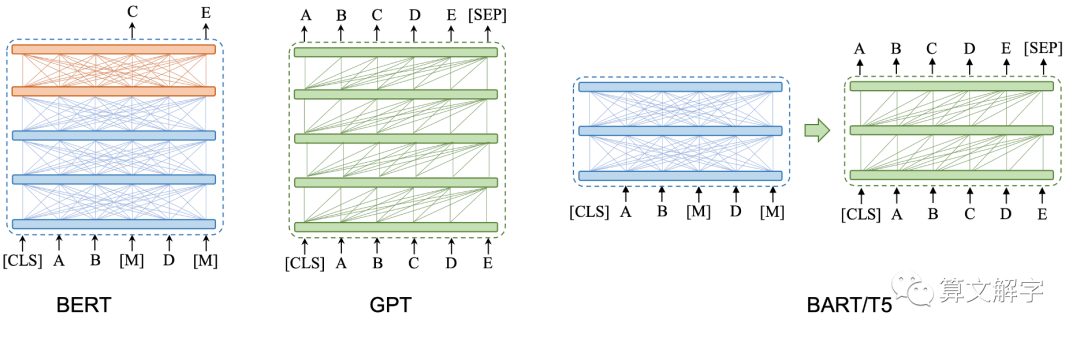
Finetune
在Fine-tuning中,我们会将预训练模型中的一部分或全部权重复制到新的任务中,然后使用新任务的数据对这些权重进行微调,使其适应新任务。微调通常需要在新任务上训练一些额外的层,这些层是预训练模型之外的新层,它们的主要作用是对预训练模型的输出进行适当的调整,使其适用于新任务。
现有的fineturjng模式可以获得不错的结果,但是同时也有很大的问题
尤其是在一个大数据的情况下,我们微调其实需要大量的数据才有一个好的效果
需要各种各样的数据,才能调整各种
lora
简单的说就是:
在模型外面在潜入一个层
用小模型去影响大模型
LORA(Layer-wise Relevance Analysis)是一种模型解释方法,用于解释深度神经网络的预测结果。它的基本思想是在模型的每一层之间插入一个解释层,通过计算每个输入特征对每个解释层的重要性来解释模型的预测过程。
具体而言,在LORA中,首先将一个小型的解释模型嵌入到原始模型的每个层之间。这个解释模型通常是一个简化的线性模型或者是一个浅层神经网络。然后,通过计算每个输入特征在解释模型中的权重,来评估该特征对模型预测结果的重要性。这样,就可以通过分析每个解释层的输出来解释原始模型的预测过程。
通过LORA方法,我们可以获得每个特征对模型预测的贡献程度,从而更好地理解模型的决策过程。这对于模型的可解释性和可信度评估非常有帮助。此外,LORA还可以用于模型的调试和改进,通过分析每个解释层的输出,我们可以发现模型中可能存在的问题,并采取相应的措施进行改进。
模型微调的问题
尤其是在一个大数据的情况下,我们微调其实需要大量的数据才有一个好的效果
在模型微调中,一个主要的问题是需要大量的数据才能获得良好的效果。特别是在面对大规模数据时,微调模型需要各种类型的数据来适应不同的任务。这使得微调变得困难和耗时。
另一个问题是微调过程中的过拟合。当微调模型时,可能会出现过拟合的情况,即模型在训练数据上表现良好,但在测试数据上表现较差。这可能是由于微调数据的数量有限,导致模型过度适应微调数据而无法泛化到新的数据。
此外,微调过程中的权衡也是一个挑战。在微调中,需要在保留预训练模型的知识的同时,对新任务进行适当的调整。这需要在保持模型的泛化能力和适应性之间找到平衡点。
综上所述,模型微调面临着数据需求大、过拟合和权衡的问题。解决这些问题需要采用合适的数据增强技术、正则化方法和模型架构设计,以及仔细调整微调过程中的超参数。