文章目录
- 一、NoSQL 简介
- 1.1 NoSQL的优点
- 1.2 NoSQL的缺点
- 1.3 NoSQL的分类
- 二、MongoDB
- 2.0 demo示例
- 2.1 install and connect mongoose
- 2.2 基本指令
一、NoSQL 简介
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL",是非关系型的数据库。
NoSQL用于超大规模数据的存储。
(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)
这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
1.1 NoSQL的优点
- 高可扩展性
- 分布式计算
- 低成本
- 架构的灵活性,半结构化数据
- 没有复杂的关系
1.2 NoSQL的缺点
- 没有标准化
- 有限的查询功能(到目前为止)
- 最终一致是不直观的程序
1.3 NoSQL的分类

接下来重点讲解 文档存储类型的MongoDB
(文档存储一般用类似json的格式存储)
二、MongoDB
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
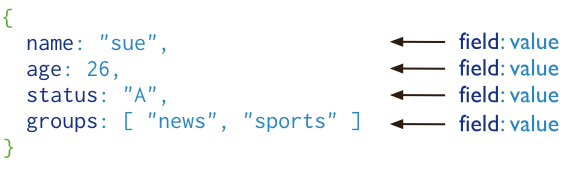

-
Schema: 相当于一个数据库的模板.
Model可以通过mongoose.model集成其基本属性内容. 当然也可以选择不继承. -
Model:基本文档数据的父类,通过集成Schema定义的基本方法和属性得到相关的内容.
-
instance: 真正的数据, 通过
new Model()初始化得到.
2.0 demo示例
const mongoose = require('mongoose');mongoose.connect('mongodb://localhost:27017/test');
const con = mongoose.connection;
con.on('error', console.error.bind(console, '连接数据库失败'));
con.once('open',()=>{//定义一个schemalet Schema = mongoose.Schema({category:String,name:String});Schema.methods.eat = function(){console.log("I've eatten one "+this.name);}//继承一个schemalet Model = mongoose.model("fruit",Schema);//生成一个documentlet apple = new Model({category:'apple',name:'apple'});//存放数据apple.save((err,apple)=>{if(err) return console.log(err);apple.eat();//查找数据Model.find({name:'apple'},(err,data)=>{console.log(data);})});
})
2.1 install and connect mongoose
使用mongoose前,需要电脑已有 nodeJS和mongodb数据库.
下载mongoose:
npm install mongoose --save
连接mongoose:
const mongoose = require('mongoose');mongoose.connect('mongodb://localhost:27017/test');
const con = mongoose.connection;
con.on('error', console.error.bind(console, '连接数据库失败'));
con.once('open',()=>{//成功连接
})
2.2 基本指令
-
show dbs显示数据库 -
show collections显示数据库中的集合
-
db.<collection>.insert(doc)插入文档 -
db <collection>.insertMany(doc插入多个
例如:
db.runoob.insert({"name":"erya"})db.collection.insertMany([ <document 1> , <document 2>, ... ],
db.<collection>.find()查看所有的文档db.<collection>.find({key:value})查看带有指定key value文档的集合db.<collection>.findOne({key:value}).name查看指定key value的第一个文档db.<collection>.find({key:value}).count()查看数量db.<collection>.find({key:value}).length()查看数量db.<collection>.find().limit(num)限制查询出的数量
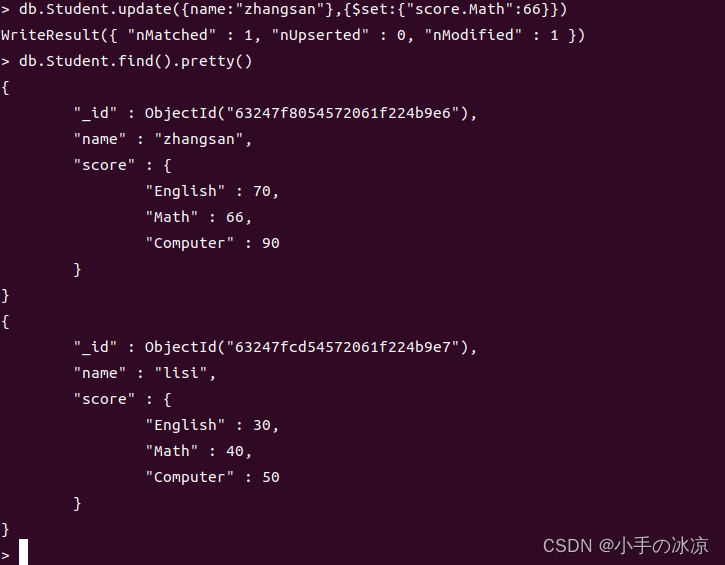
db.<collection>.update(doc1,doc2)把查询带有doc1的属性的文档用doc2替代db.student.update({age:1000},{$set:{strenth:10}})如何设置属性,没有属性可以增加属性db.student.update({age:1000},{$unset:{strenth:10}})删除strenth为key的条目db.student.remove(doc,isSingle)删除一个或者多个db.student.deleteOne(doc)删除一个db.student.deleteMany(doc)删除多个remove(doc,true)第二个参数传入true,则只删除一个remove({})全部删除
a. $ne不等于
例:查询x 的值不等于3 的数据
db.things.find( { x : { $ne : 3 } } );