目录
1. 安装pig大数据分析工具
1.1 pig介绍
1.1.1 Pig简介
1.1.2 Apache Pig 与 MapReduce
1.1.3 Apache Pig 与 SQL
1.1.4 Apache Pig 与 Hive
1.1.5 Apache Pig的应用
1.2 pig下载及安装
1.3 配置环境变量
1.4 pig启动
2. pig工具使用方法
2.1 pig工具简单解析
2.2 pig基本操作介绍
3. 实验6
3.1 启动
3.2 编辑
1. 安装pig大数据分析工具
1.1 pig介绍
1.1.1 Pig简介
Pig是一种数据流语言和运行环境,常用于检索和分析数据量较大的数据集。Pig包括两部分:一是用于描述数据流的语言,称为Pig Latin;二是用于运行Pig Latin程序的执行环境。
1.1.2 Apache Pig 与 MapReduce
| Pig | MapReduce |
| Apache Pig是一种数据流语言。 | MapReduce是一种数据处理范例。 |
| 这是一种高级语言。 | MapReduce是低级且严格的。 |
| 在Apache Pig中执行Join操作非常简单。 | 在MapReduce中,很难在数据集之间执行Join操作。 |
| 任何具有SQL基本知识的新手程序员都可以轻松地与Apache Pig一起工作。 | 使用MapReduce必须与Java接触。 |
| Apache Pig使用多查询方法,从而在很大程度上减少了代码长度。 | MapReduce将需要多近20倍的行数来执行同一任务。 |
| 无需编译。在执行时,每个Apache Pig运算符都会在内部转换为MapReduce作业。 | MapReduce作业的编译过程很长。 |
1.1.3 Apache Pig 与 SQL
| Pig | SQL |
| Pig Latin是一种程序语言。 | SQL是一种声明性语言。 |
| 在Apache Pig中,模式是可选的。我们可以存储数据而无需设计架构(值存储为$01,$02等)。 | 模式在SQL中是必需的。 |
| Apache Pig中的数据模型是嵌套关系型。 | SQL中使用的数据模型是扁平关系。 |
| Apache Pig为查询优化提供了有限的机会。 | SQL中查询优化的机会更多。 |
除了上述差异外,Apache Pig Latin-
·允许在管道中拆分。
·允许开发人员将数据存储在管道中的任何位置。
·宣布执行计划。
·提供操作员执行ETL(提取,转换和加载)功能。
1.1.4 Apache Pig 与 Hive
Apache Pig和Hive均用于创建MapReduce作业。在某些情况下,Hive以与Apache Pig相似的方式在HDFS上运行。在下表中,我们列出了一些使Apache Pig与Hive脱颖而出的重要方面。
| Pig | Hive |
| Apache Pig使用一种称为Pig Latin的语言。它最初是由Yahoo创建的。 | Hive使用一种称为HiveQL的语言。它最初是在Facebook上创建的。 |
| Pig Latin是一种数据流语言。 | HiveQL是查询处理语言。 |
| Pig Latin是一种过程语言,适合流水线范例。 | HiveQL是一种声明性语言。 |
| Apache Pig可以处理结构化,非结构化和半结构化数据。 | Hive主要用于结构化数据。 |
1.1.5 Apache Pig的应用
数据科学家通常使用Apache Pig来执行涉及即时处理和快速原型制作的任务。使用Apache Pig-
处理大量数据源,例如Web日志。
对搜索平台执行数据处理。
处理时间敏感的数据加载。
1.2 pig下载及安装
官网下载:Index of /apache/pig/pig-0.16.0
 解压安装
解压安装
![]()
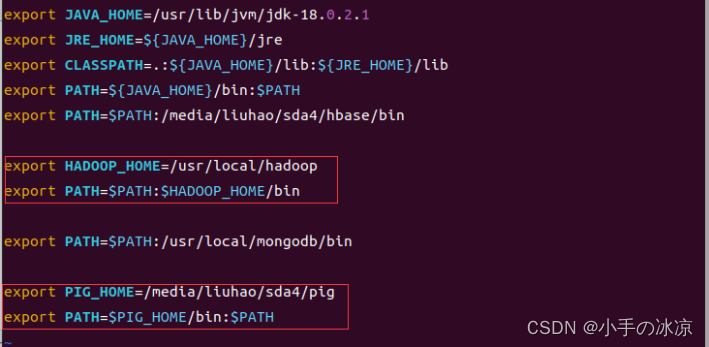
1.3 配置环境变量
vi ~/.bashrc
添加pig环境配置(根据实际安装位置)
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
Export PATH=$PATH:/usr/local/mongodb/bin
Export PIG_HOME=/media/liuhao/sda4/pig
Export PATH=$PIG_HOME/bin:$PATH

1.4 pig启动
启动Hadoop集群(略)
启动pig:./bin/pig
退出quit
2. pig工具使用方法
2.1 pig工具简单解析
Apache Pig具有以下功能:
·丰富的运算符集 - 它提供许多运算符来执行诸如 join, sort, filer等操作。
·易于编程 - Pig Latin与SQL相似,如果您擅长SQL,则很容易编写Pig脚本。
·自动优化 - Apache Pig中的任务会自动优化其执行,因此程序员只需要专注于语言的语义。
·可扩展性 – 使用现有的运算符,用户可以开发自己的函数来读取,处理和写入数据。
·UDF的 – Pig提供了使用其他编程语言(例如Java)创建用户定义函数并将其调用或嵌入Pig脚本的功能。
·处理各种数据 - Apache Pig分析所有结构化和非结构化数据。它将结果存储在HDFS中。
2.2 pig基本操作介绍
(后续补充)
3. 实验6
3.1 启动
启动Hadoop

创建文件file6.txt,并上传到Hadoop集群
启动pig
3.2 编辑
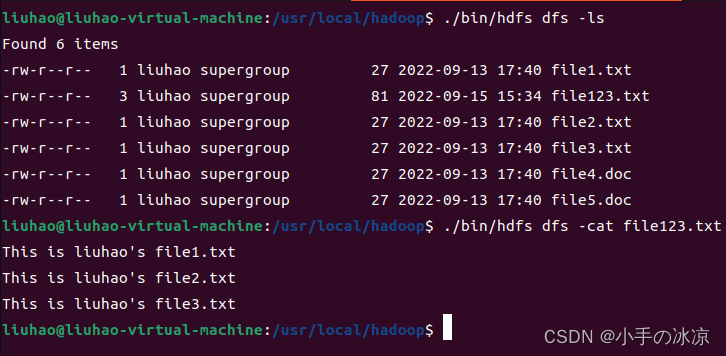
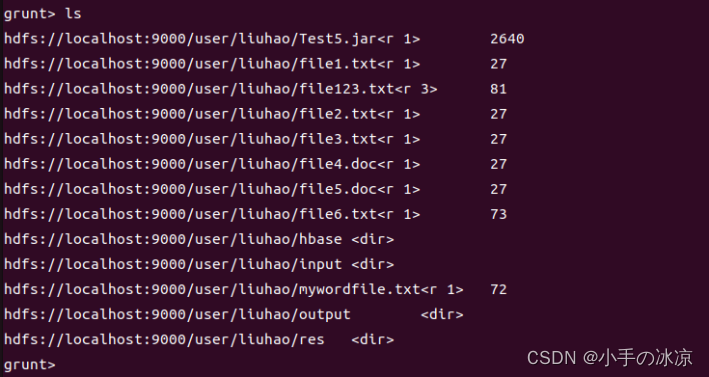
Pig使用ls命令查看文件
--load文本的txt数据,并把每行作为一个文本;
--将每行数据,按指定的分隔符(这里使用的是空格)进行分割,并转为扁平结构
--对单词分组
--统计每个单词出现的次数
--存储结果数据
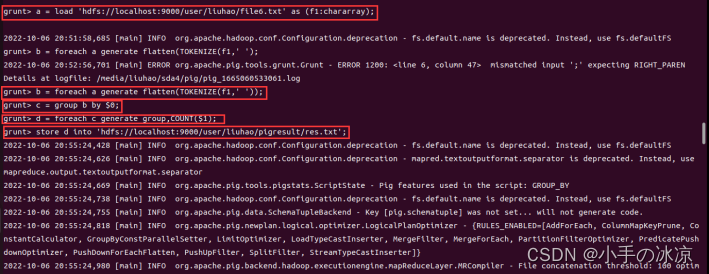
(存储结果直接到目录里,即res.txt是一个目录)
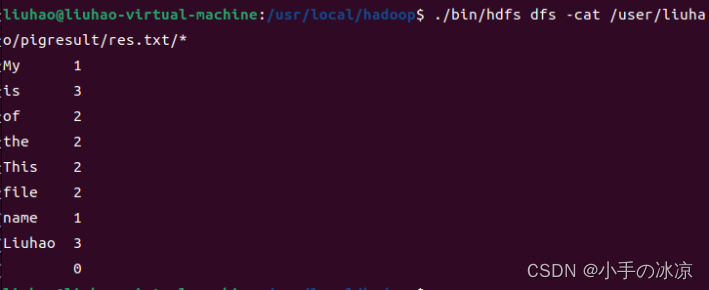
进入到存储的路径下,使用cat命令查看词频统计结果
【参考资料】
大数据篇-Pig简介及安装使用_第七行代码-商业新知
大数据分析工具Pig详细介绍_yz930618的博客-CSDN博客_大数据pig
Ubuntu安装pig-0.17.0 - 灰信网(软件开发博客聚合)
Pig的搭建和配置_不懂开发的程序猿的博客-CSDN博客_pig系统环境搭建