一、Hadoop简介及其应用现状
1、Hadoop简介
Hadoop(是大数据技术的集合体,一整套解决方案的统称)是由Java开发的,支持多种编程语言。
2、Hadoop的理论基础
(1)Hadoop的两大核心
①分布式文件系统(HDFS);
②分布式并行编程框架(MapReduce);
(2)Hadoop的特性
①高可靠性;
②高效性;
③高可扩展性;
④高容错性;
⑤成本低;
⑥运行在Linux上;
⑦支持多种编程语言;
3、Hadoop的应用现状
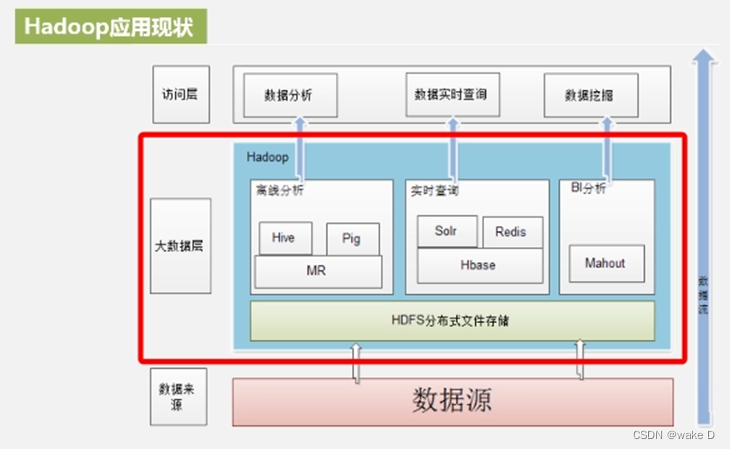
(1)Hadoop应用现状图
(2)hadoop的各种版本评价
①评价图:
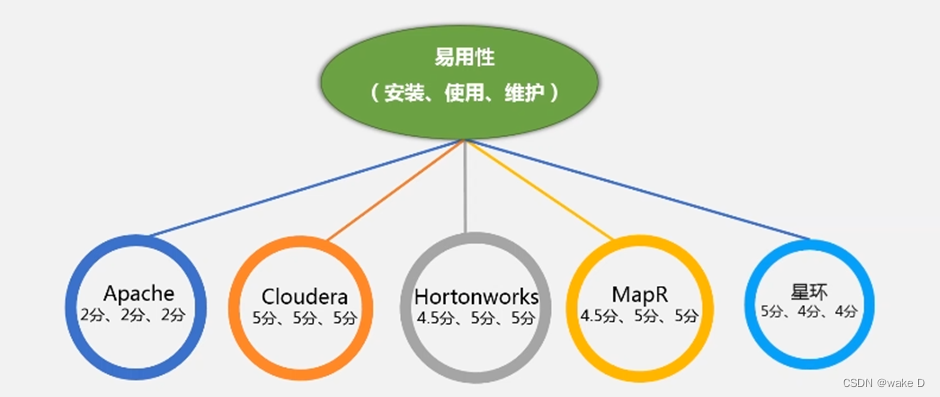
开源的Apache应用性很差,性能也是最差的。其他的都是商业化版本(做了后期优化)。
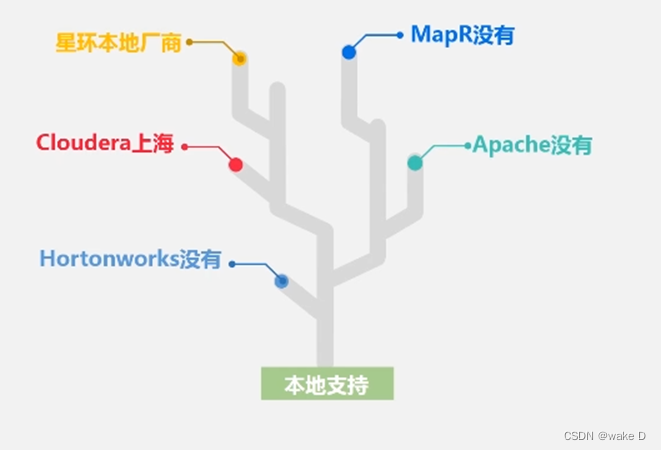
②获取本地支持的版本:
二、Hadoop的项目结构
1、基本项目结构介绍
(1)HDFS:分布式文件存储;
(2)YARN:底层的资源调度管理;
(3)MapReduce:离线计算,基于磁盘(一般不用于实时计算);
(4)Tez:用于把MapReduce的很多作业优化构建一个有向无环图,保证获得最好的处理;
(5)Spark:基于内存计算,性能比MapReduce高一个等级;
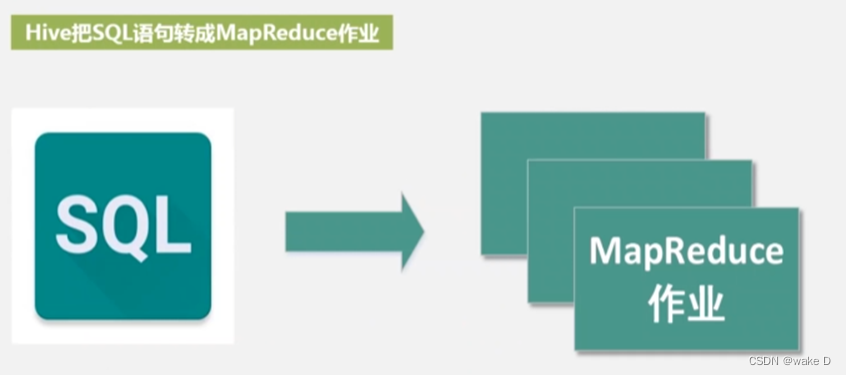
(6)Hive:数据仓库,提供企业决策依据,用于企业数据分析;
(7)Pig:轻量级分析,流数据处理;

(8)Oozie:作业调度系统;
(9)Zookeeper:分布式协调一致式服务;
(10)HBase:超大型数据库;随机读写;列族数据库,支持实时应用;
(11)Flume:日志收集;

(12)Sqoop:数据的导入和导出,用于在Hadoop与传统数据库(关系型数据库)之间进行数据传递。

(13)Ambari:

2、Linux以及Hadoop的安装配置
请参考我前面发布的这篇文章,里面有详细的手把手教程:
Linux和Hadoop安装配置教程
三、Hadoop集群的核心简介
1、核心组件及其作用以及内容
(1)核心组件
①HDFS;
②MapReduce;
(2)HDFS核心组件介绍
NameNode:类似于一个目录服务器,存放的是元数据(日志文件editsfile和镜像文件fsimage,edits文件记录hadoop所有写操作,fsimage保存文件所在目录和文件idnode的序列化信息,又称为元数据,每次重启hadoop集群,都会重新读入fsimage保证信息为最新的数据),负责接收客户端的请求信息,也负责接收DataNode上报的信息,给DN分配任务(维护副本的数量);
NameNode总结:
①接收客户端的读写请求;
②管理元数据信息;
③接收DataNode的心跳(信息)报告;
④使各个节点负载均衡;
⑤负责数据块的副本的存储结点的分配。
DataNode:存放的是块数据,不同结点的DataNode是平等的。
DataNode总结:
①处理客户端的读写请求;
②真正进行数据块的存储;
③向NameNode发送心跳(信息状态)报告;
④进行副本的复制;
SecondaryNameNode:
①帮助NameNode备份元数据信息(冷备份,即NameNode绷不住了,它并不能直接顶 上来),查看备份的元数据是否是最新的,有一定的数据延时,可能造成数据丢失;
②帮助NameNode进行元数据合并,减轻NameNode的压力;
(3)MapReduce核心组件介绍
JobTracker:负责资源管理(掌握各机器当前可用内存、可用CPU等情况),任务调度(根据可用资源,进行计算任务的分配,也就是向哪一个DataNode移动);
TaskTracker:管理被分到DataNode的计算任务、资源汇报(TaskTracker与JobTracker之间维持心跳,实时汇报当前DataNode资源所剩的情况);
JobTracker与TaskTracker之间也是主从结构,前者给后者布置任务。