目录
第一题 求分区累加值
第二题 UV和每个店铺访问量top3信息
Hive sql解答
第一题 求分区累加值
我们有如下的用户访问数据
userId visitDate visitCount
u01 2017/1/21 5
u02 2017/1/23 6
u03 2017/1/22 8
u04 2017/1/20 3
u01 2017/1/23 6
u01 2017/2/21 8
U02 2017/1/23 6
U01 2017/2/22 4
要求使用SQL统计出每个用户的累积访问次数,如下表所示:
用户id 月份 小计 累积
u01 2017-01 11 11
u01 2017-02 12 23
u02 2017-01 12 12
u03 2017-01 8 8
u04 2017-01 3 3
创建表,准备数据,使用mysql8.0
CREATE TABLE `user_visit` (`userId` varchar(255) NOT NULL,`visitDate` varchar(255) NOT NULL,`visitCount` tinyint DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO user_visit (userId,visitDate,visitCount)VALUES("u01","2017/1/21",5);
INSERT INTO user_visit (userId,visitDate,visitCount)VALUES("u02","2017/1/23",6);
INSERT INTO user_visit (userId,visitDate,visitCount)VALUES("u03","2017/1/22",8);
INSERT INTO user_visit (userId,visitDate,visitCount)VALUES("u04","2017/1/20",3);
INSERT INTO user_visit (userId,visitDate,visitCount)VALUES("u01","2017/1/23",6);
INSERT INTO user_visit (userId,visitDate,visitCount)VALUES("u01","2017/2/21",8);
INSERT INTO user_visit (userId,visitDate,visitCount)VALUES("U02","2017/1/23",6);
INSERT INTO user_visit (userId,visitDate,visitCount)VALUES("U01","2017/2/22",4);解法:
SELECT t.userId as 用户id,t.month as 月份,t.subtotal as 小计,
sum(subtotal) over (PARTITION BY t.userId ORDER BY userId,month) as 累积
FROM
(
select userId,DATE_FORMAT(visitDate,'%Y-%m') as month,sum(visitCount) as subtotal
FROM user_visit GROUP BY userId,month
) t;第二题 UV和每个店铺访问量top3信息
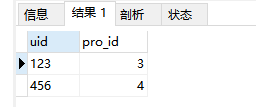
有50W个京东店铺,每个顾客访客访问任何一个店铺的任何一个商品时都会产生一条访问日志, 访问日志存储的表名为Visit,访客的用户id为user_id,被访问的店铺名称为shop,数据如下: u1 au2 bu1 bu1 au3 cu4 bu1 au2 cu5 bu4 bu6 cu2 cu1 bu2 au2 au3 au5 au5 au5 a 请统计: (1)每个店铺的UV(访客数)(2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数
创建表,准备数据,使用mysql8.0
CREATE TABLE `Visit` (`user_id` varchar(255) NOT NULL,`shop` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO Visit (user_id,shop)VALUES
("u1","a"),("u2","b"),("u1","b"),("u1","a"),("u3","c"),
("u4","b"),("u1","a"),("u2","c"),("u5","b"),("u4","b"),
("u6","c"),("u2","c"),("u1","b"),("u2","a"),("u2","a"),
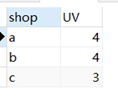
("u3","a"),("u5","a"),("u5","a"),("u5","a");(1)
-- DISTINCT去重
SELECT shop,count(DISTINCT(user_id)) UV FROM Visit GROUP BY shop;
-- GROUP BY去重
SELECT t.shop,count(t.user_id) UV FROM
(
SELECT shop,user_id FROM Visit GROUP BY shop,user_id
) t
GROUP BY t.shop;结果:
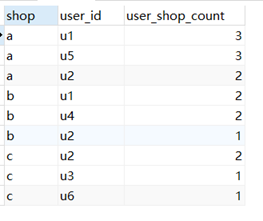
(2)
SELECT t1.shop,t1.user_id,t1.user_shop_count FROM
(
SELECT t.*,row_number()over(PARTITION BY t.shop ORDER BY t.user_shop_count DESC) shop_top FROM
(
SELECT shop,user_id,COUNT(*) user_shop_count FROM Visit GROUP BY shop,user_id
) t
)t1
WHERE
t1.shop_top <=3;结果:
Hive sql解答
-- 第1题
CREATE TABLE user_visit (
userId string,
visitDate string ,
visitCount INT )
ROW format delimited FIELDS TERMINATED BY "\t";INSERT INTO TABLE user_visit VALUES
( 'u01', '2017/1/21', 5 ),( 'u02', '2017/1/23', 6 ),
( 'u03', '2017/1/22', 8 ),( 'u04', '2017/1/20', 3 ),
( 'u01', '2017/1/23', 6 ),( 'u01', '2017/2/21', 8 ),
( 'u02', '2017/1/23', 6 ),( 'u01', '2017/2/22', 4 );select DATE_FORMAT(regexp_replace(visitDate,'/','-'),'YYYY-MM') from user_visit;select userId,
DATE_FORMAT(regexp_replace(visitDate,'/','-'),'YYYY-MM') as visitMonth,
visitCount
FROM user_visit;select userId,visitMonth,sum(visitCount) as subtotal
FROM
(
select userId,
DATE_FORMAT(regexp_replace(visitDate,'/','-'),'YYYY-MM') as visitMonth,
visitCount
FROM user_visit
)t1
GROUP BY userId,visitMonth;
-- 最终答案
SELECT t.userId as userid,t.visitMonth,t.subtotal,sum(t.subtotal) over (PARTITION BY t.userId ORDER BY t.userId,t.visitMonth) as totals
FROM
(
select userId,visitMonth,sum(visitCount) as subtotal
FROM
(
select userId,
DATE_FORMAT(regexp_replace(visitDate,'/','-'),'YYYY-MM') as visitMonth,
visitCount
FROM user_visit
)t1
GROUP BY userId,visitMonth
) t;-- 第2题
CREATE TABLE Visit (
user_id string, shop string )
ROW format delimited FIELDS TERMINATED BY '\t'; INSERT INTO TABLE Visit VALUES
( 'u1', 'a' ),( 'u2', 'b' ),( 'u1', 'b' ),( 'u1', 'a' ),( 'u3', 'c' ),
( 'u4', 'b' ),( 'u1', 'a' ),( 'u2', 'c' ),( 'u5', 'b' ),( 'u4', 'b' ),
( 'u6', 'c' ),( 'u2', 'c' ),( 'u1', 'b' ),( 'u2', 'a' ),( 'u2', 'a' ),
( 'u3', 'a' ),( 'u5', 'a' ),( 'u5', 'a' ),( 'u5', 'a' );(1)
-- DISTINCT去重
SELECT shop,count(DISTINCT(user_id)) UV FROM Visit GROUP BY shop;
-- GROUP BY去重
SELECT t.shop,count(t.user_id) UV FROM
(
SELECT shop,user_id FROM Visit GROUP BY shop,user_id
) t
GROUP BY t.shop;(2)
SELECT t1.shop,t1.user_id,t1.user_shop_count FROM
(
SELECT t.*,row_number()over(PARTITION BY t.shop ORDER BY t.user_shop_count DESC) shop_top FROM
(
SELECT shop,user_id,COUNT(*) user_shop_count FROM Visit GROUP BY shop,user_id
) t
)t1
WHERE
t1.shop_top <=3;
参考博客:经典Hive-SQL面试题
参考博客:[hive] 经典sql题及答案(一)