什么是bulk操作
bulk是批量的意思,也就是把原来单个的操作打包好,通过批量的api提交到ES集群。下面是个示例:
单个操作:
PUT my-index-000001/_doc/1
{"@timestamp": "2099-11-15T13:12:00","message": "GET /search HTTP/1.1 200 1070000","user": {"id": "kimchy"}
}
bulk操作:
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
另外,ES还提供了相关的API支持bulk操作,
BulkRequest bulkRequest = new BulkRequest();entityWrapperList.forEach(item -> {IndexRequest request = new IndexRequest(item.getIndexName());request.id(item.getId());if (item.getVersion() > 0) {request.version(item.getVersion());request.versionType(VersionType.EXTERNAL_GTE);}request.source(JSON.toJSONString(item.getData()), XContentType.JSON);bulkRequest.add(request);});try {BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);


可以看到,我们可以把多个不同的命令打包好通过bulk提交。不过我个人的经验实际场景中多是相同的命令(比如批量index)。
bulk操作的顺序问题
一提到批量操作,有经验的人马上就会提出一个问题:一堆命令提交到ES,那么ES执行的顺序和我们提交的顺序是一致的吗?毕竟有些业务场景会对执行命令的顺序有要求。
答案是不一定。

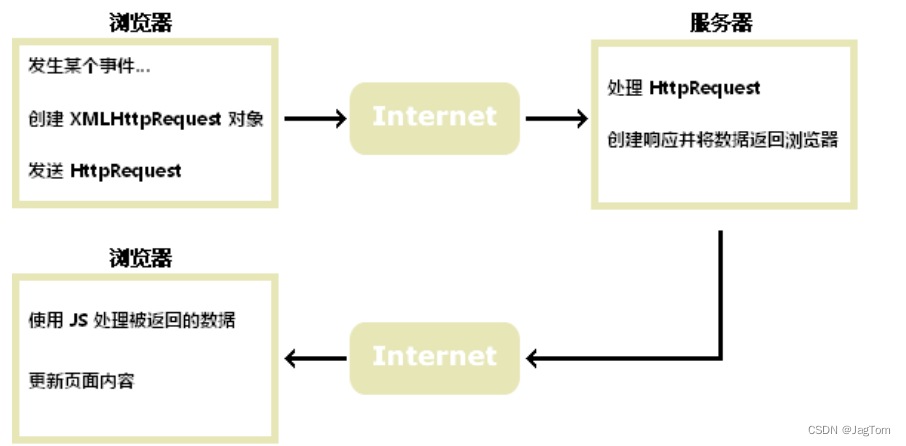
根源在于ES的分布式架构。如上图所示,客户端的命令首先是请求到coordinating node(协调节点),然后协调节点根据命令提供的的路由字段(没有的话默认使用文档id),经过路由算法,找到对应的主shard(分片)。所以真正执行的节点就是shard所在的节点,而每条命令发送到节点上到底哪个先执行是没有保障的,取决于很多因素。比如发送到节点的时间,节点本身的空闲资源情况等。
不过从上面这段解释,我们也可以得出另外一个结论,就是对于同一个文档的操作是有序的。了解这点在一些业务场景下很重要。
虽然处理的顺序不能保证,但是ES会保证响应结果和提交的顺序是一致的。
{"took": 30,"errors": false,"items": [{"index": {"_index": "test","_id": "1","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"status": 201,"_seq_no" : 0,"_primary_term": 1}},{"delete": {"_index": "test","_id": "2","_version": 1,"result": "not_found","_shards": {"total": 2,"successful": 1,"failed": 0},"status": 404,"_seq_no" : 1,"_primary_term" : 2}},{"create": {"_index": "test","_id": "3","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"status": 201,"_seq_no" : 2,"_primary_term" : 3}},{"update": {"_index": "test","_id": "1","_version": 2,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"status": 200,"_seq_no" : 3,"_primary_term" : 4}}]
}
这个返回的结果顺序,跟提交的顺序是一致的,标注每条命令执行的结果。
bulk操作的性能如何
ES官方是建议在业务场景允许的情况下,尽量使用bulk操作来提高index的性能,官方文档是这么说的。
Bulk requests will yield much better performance than single-document index requests. In order to know the optimal size of a bulk request, you should run a benchmark on a single node with a single shard. First try to index 100 documents at once, then 200, then 400, etc. doubling the number of documents in a bulk request in every benchmark run. When the indexing speed starts to plateau then you know you reached the optimal size of a bulk request for your data. In case of tie, it is better to err in the direction of too few rather than too many documents. Beware that too large bulk requests might put the cluster under memory pressure when many of them are sent concurrently, so it is advisable to avoid going beyond a couple tens of megabytes per request even if larger requests seem to perform better.
这句话的大概意思是,bulk的index操作性能是高于单文档的index操作的。至于bulk每个批次多少个文档是最优的,需要根据自己的实际环境进行压力测试,以实际的结果为准。
bulk性能高是自然的,因为它大大降低了业务和ES集群之间的IO。
bulk批量更新重复id的性能问题
之前在ES中文社区看到过一篇关于bulk更新重复id的文档情况下,性能低的问题。后来有时间专门去研究了一下源码,觉得这个问题很好这里分享下。
在ES 5.x的版本中,如果bulk update文档里面含有大量重复文档(文档id一样)的情况,实际项目环境中发现bulk性能非常低。
要理解其中的缘由,首先必须了解ES的update操作,是先get出来最新的文档,然后在内存里更新,最后再写回去。get操作的源码长这样:

从源码可以看出,在realtime=true(默认情况)的情况下,会先执行一个
refresh("realtime_get");
然后从searcher里获取文档(getFromSearcher)。
这个refresh的方法,会检查GET的文档是否都是可以被搜索到。如果已经写入了但无法搜索到,也就是刚刚写入到buffer里还未refresh这种情况,会强制执行一次refresh操作,保证getFromSearcher可以搜索到文档。
所以在大量重复id的情况下,会大量触发refresh操作,(不重复的情况就不会)产生很多小的segments,然后又触发很多segment merge操作。
这个问题在6.3的版本之后已经接近了,pull request的链接如下:
https://github.com/elastic/elasticsearch/pull/29264
其实接近方案就是在实时的情况下,从translog拿文档,而不是refresh后通过搜索拿。我本地的代码是7.10版本,就用这个版本的代码来看下。


可以看到,当readFromTranslog为true时,get操作是从translog读取数据,而初始化的时候这个值和realtime取的是同一个值。也就是实时情况下(realtime=true),会从translog读取文档。这样就解决了前面抛出来的问题。
参考:
- https://www.elastic.co/guide/en/elasticsearch/reference/master/docs-bulk.html
- https://github.com/elastic/elasticsearch/pull/20102/commits/2738e00e15470f566aa33adcbaa39c4dba1d1828