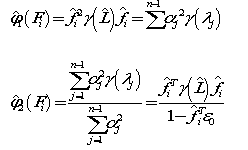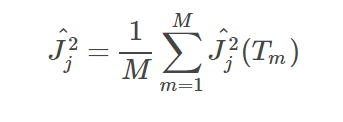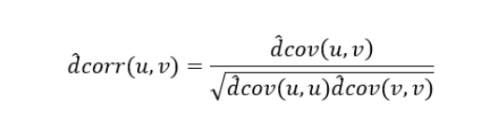文章目录
- 前言
- 特征选择
- 过滤法
- Pearson系数
- 卡方检验
- 互信息和最大信息系数
- 距离相关系数
- 方差选择法
- 包装法
- 嵌入法
- 总结
前言
最近在看吴恩达的深度学习机器学习课程。地址:deeplearningai。课程在机器学习特征工程的课程中提到特征选择。在机器学习项目生命周期里,特征工程占据很大的比重,特征工程关乎最终模型性能的好坏,正所谓“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。而特征选择是特征工程的一个重要问题,本文结合【机器学习】特征选择(Feature Selection)方法汇总一文,一起探讨特征工程里面的特征选择。
特征选择
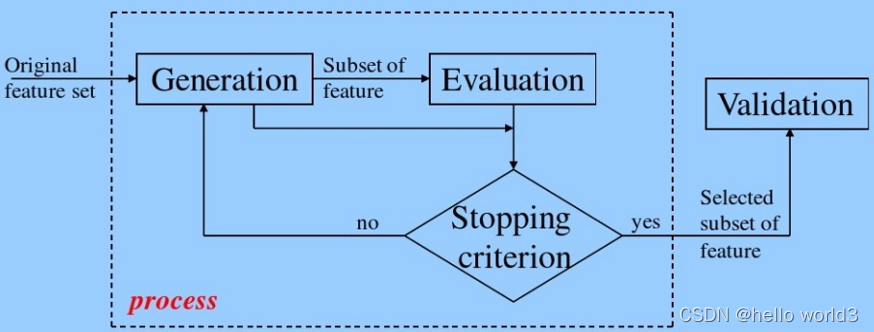
特征选择的目标是选择最优特征的子集,将一些不相关或者冗余的特征剔除,优化特征向量,避免不相关或冗余特征的干扰,提高模型的精度,提升模型的效率。另一方面在做特征选择过程中,能够协助理解数据产生的过程,理解特征的分布情况,有助于训练机器学习模型。特征选择的一般流程:
- 生成子集:搜索特征子集,为评价函数提供特征子集
- 评价函数:评价特征子集的好坏
- 停止准则:与评价函数相关,一般是阈值,评价函数达到一定标准后就可以停止搜索
- 验证过程:在验证数据集上验证选出来的特征子集的有效性
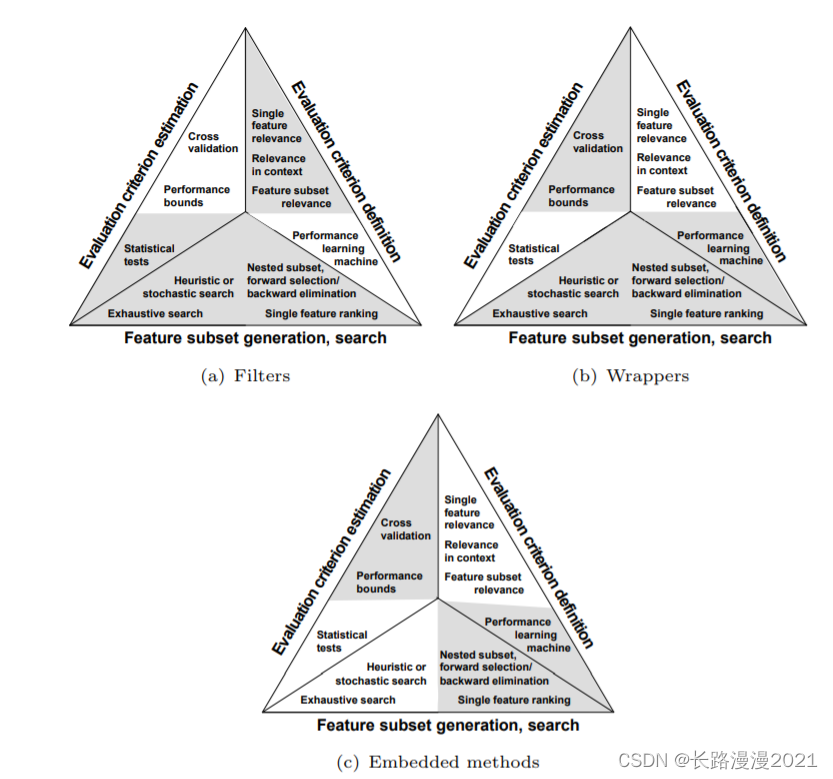
根据特征选择的形式,结合吴恩达的课程,将特征选择分为三大类:
- Filter(过滤法):按照
发散性或相关性对各个特征进行评分,设定阈值或者待选择特征的个数进行筛选。 - Wrapper(包装法):根据目标函数,每次选择若干特征,或者排除若干特征
- Embedded(嵌入法):先使用某些机器学习的模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征
过滤法
思想:分别对每个特征 x i x_i xi计算其相对于类别标签y的信息量 S i g n a l ( i ) Signal(i) Signal(i),得到n个结果。然后将n个 S i g n a l ( x ) Signal(x) Signal(x)按照从大到小排序,输出前k个特征。其中计算信息量的有以下方法:
- Pearson相关系数
- 卡方检验
- 互信息和最大信息系数
- 距离相关系数
- 方差选择法
Pearson系数
Pearson系数能够衡量特征和标签之间关系的方法,计算速度快,易于计算,但是有明显的缺点是,作为特征排序机制,只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应关系,Pearson相关性也可能接近0(如何理解Pearson系统?)。Pearson系数结果的取值区间为[-1,1] , -1 表示完全的负相关(这个变量下降,那个就会上升), +1 表示完全的正相关, 0 表示没有线性相关性。
import numpy as np
from scipy.stats import pearsonrnp.random.seed(0)
size = 300
x = np.random.normal(0, 1, size)
print("Lower noise:", pearsonr(x, x + np.random.normal(0, 1, size)))
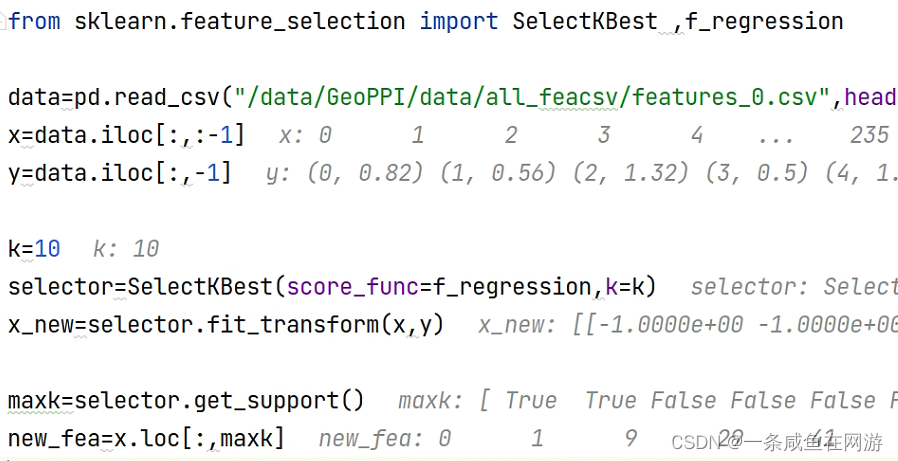
print("Higher noise:", pearsonr(x, x + np.random.normal(0, 10, size)))from sklearn.feature_selection import SelectKBest
# 选择K个最好的特征,返回选择特征后的数据
# 第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
# 参数k为选择的特征个数
SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
卡方检验
经典的卡方检验是检验类别型变量对类别型变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
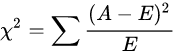
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris = load_iris()
X, y = iris.data, iris.target #iris数据集#选择K个最好的特征,返回选择特征后的数据
X_new = SelectKBest(chi2, k=2).fit_transform(X, y)
互信息和最大信息系数
经典的互信息也是评价类别型变量对类别型变量的相关性的,互信息公式如下:
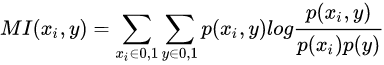
距离相关系数
距离相关系数是为了克服Pearson相关系数的弱点而生的。在 x x x和 x 2 x^2 x2 这个例子中,即便Pearson相关系数是 0 ,也不能断定这两个变量是独立的(有可能是非线性相关);但如果距离相关系数是 0 ,那么就可以说这两个变量是独立的。
from scipy.spatial.distance import pdist, squareform
import numpy as np
import copy
def distcorr(Xval, Yval, pval=True, nruns=500):""" Compute the distance correlation function, returning the p-value."""X = np.atleast_1d(Xval)Y = np.atleast_1d(Yval)if np.prod(X.shape) == len(X):X = X[:, None]if np.prod(Y.shape) == len(Y):Y = Y[:, None]X = np.atleast_2d(X)Y = np.atleast_2d(Y)n = X.shape[0]if Y.shape[0] != X.shape[0]:raise ValueError('Number of samples must match')a = squareform(pdist(X))b = squareform(pdist(Y))A = a - a.mean(axis=0)[None, :] - a.mean(axis=1)[:, None] + a.mean()B = b - b.mean(axis=0)[None, :] - b.mean(axis=1)[:, None] + b.mean()dcov2_xy = (A * B).sum() / float(n * n)dcov2_xx = (A * A).sum() / float(n * n)dcov2_yy = (B * B).sum() / float(n * n)dcor = np.sqrt(dcov2_xy) / np.sqrt(np.sqrt(dcov2_xx) * np.sqrt(dcov2_yy))if pval:greater = 0for i in range(nruns):Y_r = copy.copy(Yval)np.random.shuffle(Y_r)if distcorr(Xval, Y_r, pval=False) > dcor:greater += 1return (dcor, greater / float(nruns))else:return dcor
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import dcor
iris = load_iris()
iris_df = pd.DataFrame(data=np.c_[iris['data'], iris['target']],columns=iris['feature_names'] + ['target'])
print("dcor distance correlation = {:.3f}".format(dcor.distance_correlation(iris_df['sepal length (cm)'], iris_df['petal length (cm)'])))
方差选择法
过滤特征选择法还有一种方法不需要度量特征 x i x_i xi 和类别标签 y y y 的信息量。这种方法先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
from sklearn.feature_selection import VarianceThreshold
X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
# 方差选择法,返回值为特征选择后的数据
# 参数threshold为方差的阈值
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
print(sel.fit_transform(X))
方差选择的逻辑并不是很合理,这个是基于各特征分布较为接近的时候,才能以方差的逻辑来衡量信息量。但是如果是离散的或是仅集中在几个数值上,如果分布过于集中,其信息量则较小。而对于连续变量,由于阈值可以连续变化,所以信息量不随方差而变。 实际使用时,可以结合cross-validate进行检验。
包装法
基本思想:基于hold-out方法,对于每一个待选的特征子集,都在训练集上训练一遍模型,然后在测试集上根据误差大小选择出特征子集。需要先选定特定算法,通常选用普遍效果较好的算法, 例如Random Forest, SVM, KNN等等。常用的包装法包括了前向选择法,后向剔除法,迭代剔除法等。
- 前向选择法:这是一种基于循环的方法,开始时我们训练一个不包含任何特征的模型,而后的每一次循环我们都持续放入能最大限度提升模型的变量,直到任何变量都不能提升模型表现。
- 后向剔除法:该方法先用所有特征建模,再逐步剔除最不显著的特征来提升模型表现。同样重复该方法直至模型表现收敛。
- 迭代剔除法:这是一种搜索最优特征子集的贪心优化算法。它会反复地训练模型并剔除每次循环的最优或最劣特征。下一次循环,则使用剩余的特征建模直到所有特征都被剔除。之后,按照剔除的顺序给所有特征排序作为特征重要性的度量。
嵌入法
- 基于惩罚项的特征选择法 通过L1正则项来选择特征:L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性。
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression#带L1惩罚项的逻辑回归作为基模型的特征选择
SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target)
- 基于学习模型的特征排序 这种方法的思路是直接使用你要用的机器学习算法,针对每个单独的特征和响应变量建立预测模型。假如某个特征和响应变量之间的关系是非线性的,可以用基于树的方法(决策树、随机森林)、或者扩展的线性模型等。基于树的方法比较易于使用,因为他们对非线性关系的建模比较好,并且不需要太多的调试。但要注意过拟合问题,因此树的深度最好不要太大,再就是运用交叉验证。通过这种训练对特征进行打分获得相关性后再训练最终模型。
总结
特征选择算法可以被视为搜索技术和评价指标的结合。前者提供候选的新特征子集,后者为不同的特征子集打分。 最简单的算法是测试每个特征子集,找到究竟哪个子集的错误率最低。这种算法需要穷举搜索空间,难以算完所有的特征集,只能涵盖很少一部分特征子集。 选择何种评价指标很大程度上影响了算法。而且,通过选择不同的评价指标,可以把特征选择算法分为三类:包装类、过滤类和嵌入类方法。
- 过滤类方法采用代理指标,而不根据特征子集的错误率计分。所选的指标算得快,但仍然能估算出特征集好不好用。常用指标包括互信息、逐点互信息、皮尔逊积矩相关系数、每种分类/特征的组合的帧间/帧内类距离或显著性测试评分。过滤类方法计算量一般比包装类小,但这类方法找到的特征子集不能为特定类型的预测模型调校。由于缺少调校,过滤类方法所选取的特征集会比包装类选取的特征集更为通用,往往会导致比包装类的预测性能更为低下。不过,由于特征集不包含对预测模型的假设,更有利于暴露特征之间的关系。许多过滤类方法提供特征排名,而非显式提供特征子集。要从特征列表的哪个点切掉特征,得靠交叉验证来决定。过滤类方法也常常用于包装方法的预处理步骤,以便在问题太复杂时依然可以用包装方法。
- 包装类方法使用预测模型给特征子集打分。每个新子集都被用来训练一个模型,然后用验证数据集来测试。通过计算验证数据集上的错误次数(即模型的错误率)给特征子集评分。由于包装类方法为每个特征子集训练一个新模型,所以计算量很大。不过,这类方法往往能为特定类型的模型找到性能最好的特征集。
- 嵌入类方法包括了所有构建模型过程中用到的特征选择技术。这类方法的典范是构建线性模型的LASSO方法。该方法给回归系数加入了L1惩罚,导致其中的许多参数趋于零。任何回归系数不为零的特征都会被LASSO算法“选中”。LASSO的改良算法有Bolasso和FeaLect。Bolasso改进了样本的初始过程。FeaLect根据回归系数组合分析给所有特征打分。 另外一个流行的做法是递归特征消除(Recursive Feature Elimination)算法,通常用于支持向量机,通过反复构建同一个模型移除低权重的特征。这些方法的计算复杂度往往在过滤类和包装类之间。
- 特征选择在很多机器学习和数据挖掘场景中都是非常有用的。在使用的时候要弄清楚自己的目标是什么,然后找到哪种方法适用于自己的任务;当选择最优特征以提升模型性能的时候,可以采用交叉验证的方法来验证某种方法是否比其他方法要好;当用特征选择的方法来理解数据的时候要留心,特征选择模型的稳定性非常重要,稳定性差的模型很容易就会导致错误的结论;数据进行二次采样然后在子集上运行特征选择算法能够有所帮助,如果在各个子集上的结果是一致的,那就可以说在这个数据集上得出来的结论是可信的,可以用这种特征选择模型的结果来理解数据。