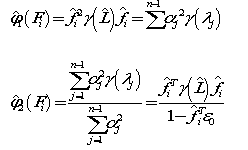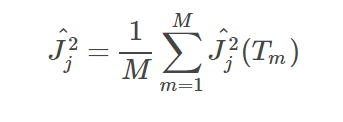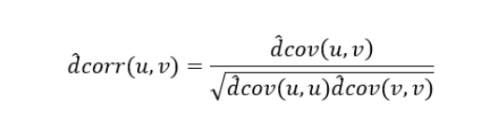特征选择
1、简述特征选择的目的。
-
减轻维数灾难问题:特征个数越多,模型也会越复杂,其泛化能力会下降。
-
降低学习任务的难度: 特征个数越多,分析特征、训练模型所需的时间就越长。
特征选择能够明显的改善学习器的精度,减少模型训练时间,有效的避免维灾难问题。
维度灾难:当特征维度超过一定界限后,分类器的性能随着特征维度的增加反而下降(而且维度越高训练模型的时间开销也会越大)。导致分类器下降的原因往往是因为这些高纬度特征中含有无关特征和冗余特征,因此特征选择的主要目的是去除特征中的无关特征和冗余特征:


无关特征:是指与当前学习任务无关的特征(该特征所提供的信息对于当前学习任务无用),如对于学生成绩而言,学号则是无关特征。
冗余特征:是指该特征所包含的信息能从其他特征推演出来,如对于“面积”这个特征而言,从能从“长”和“宽”得出,则它是冗余特征。
2、试比较特征选择与第十章介绍的降维方法的异同。
相同点:
- 相似的动机:为了减轻维数灾难问题,两者是处理高维数据的两大主流技术;
不同点:
- 降维本质上是从一个维度空间映射到另一个维度空间,特征的多少并没有减少,当然在映射的过程中特征值也会相应的变化。
例如:现在的特征是1000维,我们想要把它降到500维。降维的过程就是找个一个从1000维映射到500维的映射关系。原始数据中的1000个特征,每一个都对应着降维后的500维空间中的一个值。假设原始特征中有个特征的值是9,那么降维后对应的值可能是3。
- 特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只选择了其中的一部分特征。
例如:现在的特征是1000维,现在我们要从这1000个特征中选择500个,那个这500个特征的值就跟对应的原始特征中那500个特征值是完全一样的。对于另个500个没有被选择到的特征就直接抛弃了。假设原始特征中有个特征的值是9,那么特征选择选到这个特征后它的值还是9,并没有改变。
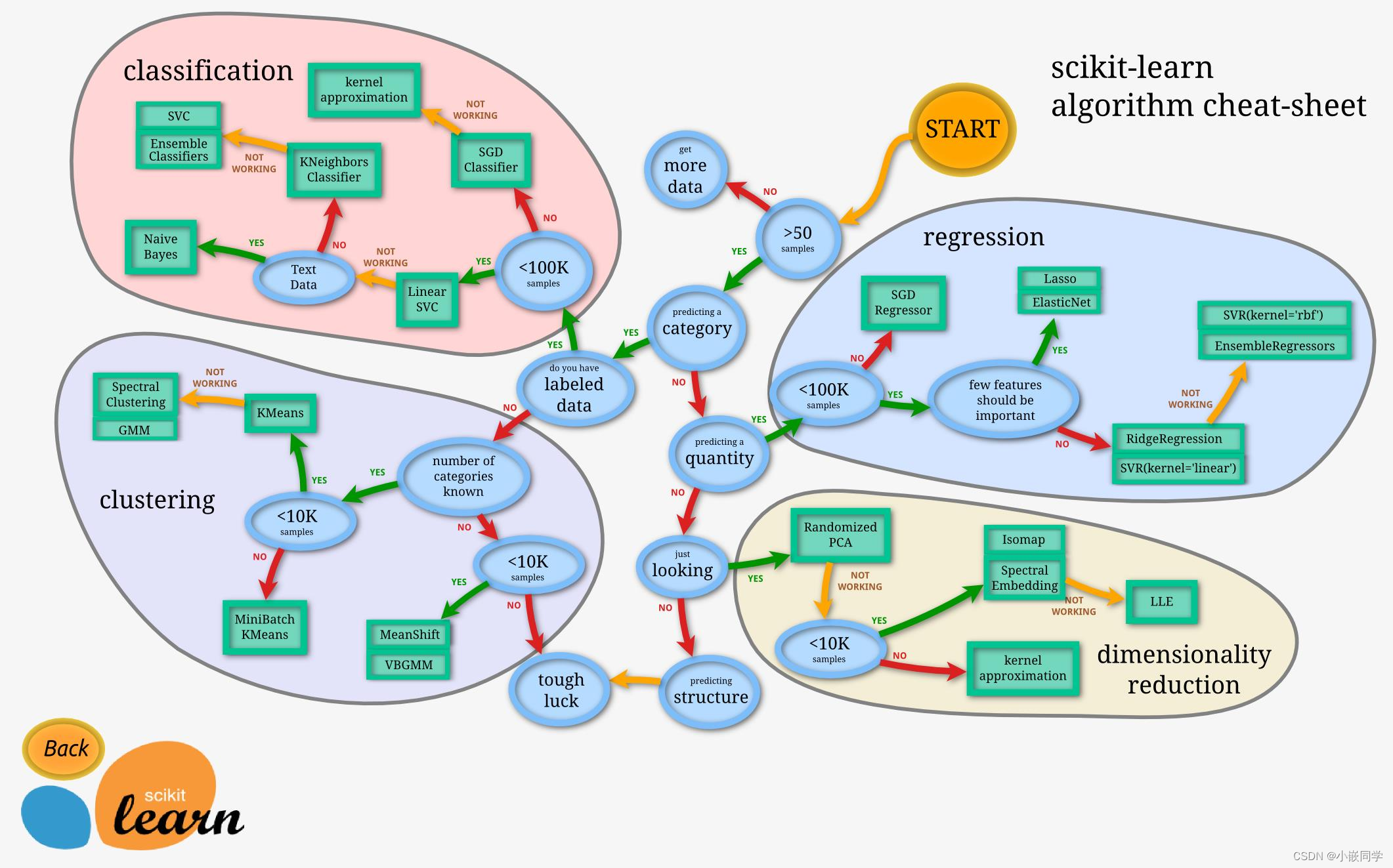
3、特征选择根据选择策略可以分为哪几类,分别说明其特点。
过滤式方法先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关。
Relief就是著名的过滤式特征选择方法。
与过滤式选择不考虑后续学习器不同,包裹式选择直接把最终将要使用的学习器的性能作为特征子集的评价依据,也就是说,包裹式特征选择是为给定的学习器选择最有利的特征子集。与过滤式选择相比,包裹式选择的效果一般会更好,但由于在特征选择过程中需要多长训练学习器,因此包裹式选择的计算开销要大很多。
LVW是一种典型的包裹式特征选择方法
在过滤式选择与包裹式选择方法中,特征选择过程与学习器训练过程有明显区别,与它们不同的是,嵌入式选择是将特征选择过程与学习器训练过程融合为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择。
基于 L1正则化的学习方法就是一种嵌入式的特征选择方法
4、试写出Relief-F的算法描述。
ReliefF算法是Relief算法的扩展, Relief算法只适用于两类样本的问题, ReliefF算法可以应用到多个样本上。
ReliefF算法步骤如下:
现有不同类别的样本若干, 对每类样本称作 Xn。
1. 从所有样本中,随机取出一个样本a。
2. 在与样本a相同分类的样本组内,取出k个最近邻样本。
3. 在所有其他与样本a不同分类的样本组内, 也分别取出k个最近邻样本。
4. 计算每个特征的权重。
5. 根据权重排序,得到合适的特征
其中,对于每个特征的权重有:
权重意义在于, 减去相同分类的该特征差值, 加上不同分类的该特征的差值。(若该特征与分类有关,则相同分类的该特征的值应该相似, 而不同分类的值应该不相似)

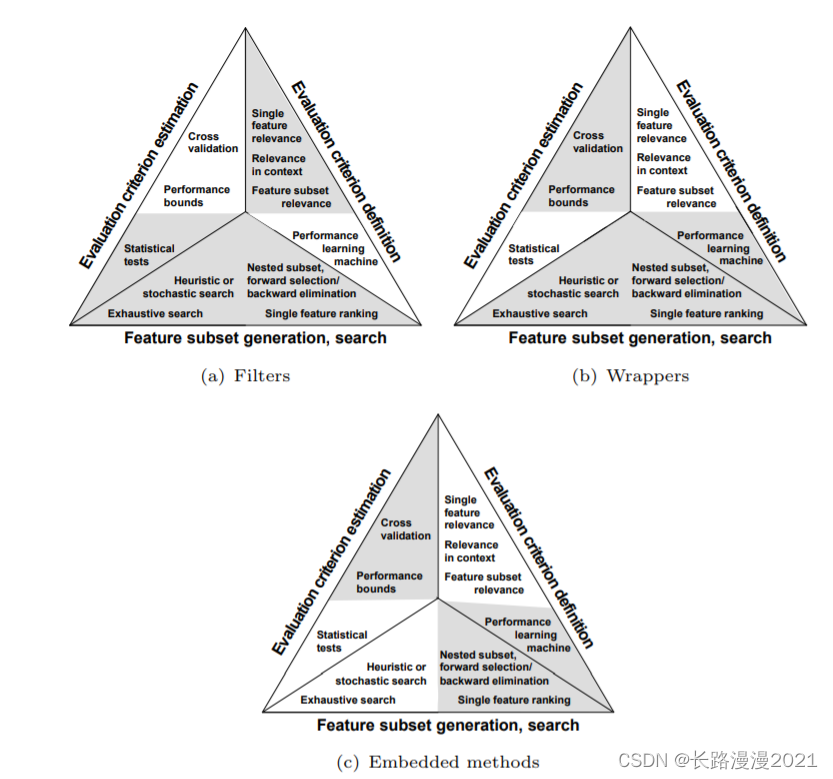
5、试描述过滤式和包裹式选择方法的基本框架。
过滤式先对数据集进行特征选择,使用选择出来的特征子集训练学习器,特征选择选择过程与后续的学习器无关。其基本原理如下图所示:

包装法特征选择方法 直接把最终将要使用的学习器的性能作为特征子集的评价准则,这是与过滤法特征选择方法最大的区别。

包装式特征选择直接将最终将要使用的学习器的性能作为评价函数,因此从模型性能的角度出发,能够发现包装式特征选择的性能要优于过滤式特征选择,但是包装式特征选择的时间开销较大。而过滤式特征选择由于和特定的学习器无关,所以计算开销小,泛化能力强于包装式特征选择。因此,在实际应用中由于数据集很大,特征维度高,过滤式特征选择应用的更广泛些。

参考文献:
[1] 维数灾难与框图: http://www.360doc.com/content/18/0417/14/54605916_746365854.shtml
[2] 周志华.机器学习[M].北京:清华大学出版社,2016:252-253.