问题
在数据处理中经常会遇到特征太多造成的计算负担和一些其他的影响,如过拟合等,不但使得预测结果不准确,还消耗计算时间。所以特征选择就显得非常重要了。
特征选择:从给定的特征集合中选取出相关特征子集的过程成为“特征选择”。
通过这一操作,不仅能够减少特征的维度,也能得到更能体现目标值的几个特征。在周志华的《机器学习》中第十一章对于特征选择也是有所提到。在文章中大佬对于特征选择的方法分为三类:过滤式(filter),包裹式(wrapper),和嵌入式(embedding).
过滤式(filter)
过滤式:主要是在数据处理过程就对特征进行筛选了,也就是说和机器学习算法无关。该方法本质就是利用数据的数理统计中的某些指标数值来进行筛选。例如卡方,还有信息增益。对于每一个不同的统计量,我们都需要一个阈值来确定那些特征是我们想要的,而这个统计量我们称为“相关统计量”。
方差筛选:
计算每一个特征的方差值,默认情况是删除所有方差为0的特征,很显然,特征为零的数据意味着数据变化为零,这对结果预测的帮助非常小。同样可以通过设定一个阈值,来筛选特征。
例子代码:
from sklearn.feature_selection import VarianceThreshold # 导入python的相关模块X = [[7, 4, 1], [5, 9, 6], [1, 2, 8], [4, 1, 5]] #样本情况
select_Feature = VarianceThreshold(threshold=(6)) # 筛选特征的方差大于阈值的特征
select_Feature.fit_transform(X) # 返回的结果为选择的特征print(select_Feature.fit_transform(X))结果:
[[4 1][9 6][2 8][1 5]]
除了这个简单易懂的方差筛选法外,还有卡方,信息增益等
卡方检验 筛选
其实卡方的本质和误差计算类似,也是实际值与期望值的差经过一些运算得到的一个统计量,
对于这个统计量来说

目的是验两个变量独立性的方法,其中
这里写图片描述为实际值,E是期望值,所以当两者越接近的话,意味着差异越小,从实际意义上来讲就是特征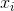



举例说明:
| 是否化妆 | 男 | 女 | 总计 |
|---|---|---|---|
| 化妆 | 15(55) | 95(55) | 110 |
| 不化妆 | 85(45) | 5(45) | 90 |
| 100 | 100 | 200 |
原假设:化妆与性别没有关系。
将表中数据带入到公式去,计算可以得出:
我们得到的结果是129.3,通过查表可以得出推理论犯错的概率p>0.999,也就是存在99.9的可能性是错的。

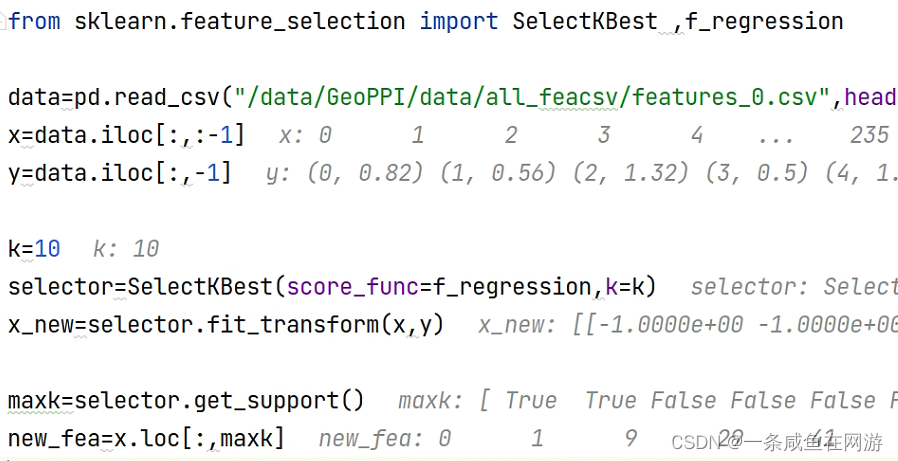
而该方法在Sklearn中都可以直接调用,如下:
from sklearn.feature_selection import chi2
from sklearn.feature_selection import SelectKBest
import pandas as pd
import numpy as np#利用卡方计量来筛选7个满足条件的特征
x_data = SelectKBest(chi2, k=7).fit_transform(x_data, y_data)
信息增益(information gain)
信息增益主要是通过计算信息熵(entropy)与条件熵的差值的大小排序,这个要对熵进行解释一下,这个概念主要是在物理学中对系统状态混乱程度的量化,如果一个系统不确定的程度越大,那么其熵就越大。所得出的一种特征选择的方法,计算方法如下:
这个计算得出的信息熵E(X),这个比较容易理解。
其次我们需要计算条件熵,

。该公式以例子来给大家解说一下

| 时间 | 效率 | 智商 | 成绩好坏 |
|---|---|---|---|
| 多 | 高 | 高 | 好 |
| 少 | 低 | 低 | 坏 |
| 少 | 高 | 高 | 好 |
| 多 | 低 | 高 | 好 |
| 多 | 低 | 低 | 坏 |
我们可以看出Y=好/坏的分别概率为3/5,2/5,而我们条件概率,就是在时间多/少确认的情况下(概率为3/5,2/5),效率是否高的概率,例如在已知时间多的情况下,成绩好的占2/3,坏的1/3,H(Y|X = 多)=-(2/3)log(2/3)-(1/3)log(1/3),p(x=多)的概率为3/5,所以将全部的情况计算相加就可以得到条件熵了。
随后我们将两者相减,按照差值排序就可以了。
代码:
import numpy as np
import pandas as pd
import mathclass IG():def __init__(self,X,y):X = np.array(X)n_feature = np.shape(X)[1]#取出x的特征数n_y = len(y)#类标的长度orig_H = 0 #信息熵for i in set(y):#orig_H += -(y.count(i)/n_y)*math.log(y.count(i)/n_y)#条件信息熵condi_H_list = []for i in range(n_feature):feature = X[:,i]sourted_feature = sorted(feature)threshold = [(sourted_feature[inde-1]+sourted_feature[inde])/2 for inde in range(len(feature)) if inde != 0 ]thre_set = set(threshold)if float(max(feature)) in thre_set:thre_set.remove(float(max(feature)))if min(feature) in thre_set:thre_set.remove(min(feature))pre_H = 0for thre in thre_set:lower = [y[s] for s in range(len(feature)) if feature[s] < thre]highter = [y[s] for s in range(len(feature)) if feature[s] > thre]H_l = 0for l in set(lower):H_l += -(lower.count(l) / len(lower))*math.log(lower.count(l) / len(lower))H_h = 0for h in set(highter):H_h += -(highter.count(h) / len(highter))*math.log(highter.count(h) / len(highter))temp_condi_H = len(lower)/n_y *H_l+ len(highter)/n_y * H_hcondi_H = orig_H - temp_condi_Hpre_H = max(pre_H,condi_H)condi_H_list.append(pre_H)#返回所需要的信息增益值self.IG = condi_H_listdef getIG(self):return self.IGif __name__ == "__main__":X = [[1, 0, 0, 1],[0, 1, 1, 1],[0, 0, 1, 0]]y = [0, 0, 1]print(IG(X,y).getIG())结果:
[0.17441604792151594, 0.17441604792151594, 0.17441604792151594, 0.6365141682948128]信息增益比
信息增益比,可以说是信息增益的进一步的指标,因为信息增益存在的缺点是它会倾向于分类较多的特征。
其主要的思想是,对于样本集合D来说,随即变量X是样本的类别,即假设有k个类别,每一个类别的概率为


基尼系数
基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。

基尼系数=样本选中的概率*样本选错的概率,
以上三种计量值都是决策树对于节点的选择依据,而基尼系数就是CART的标准,而信息增益是ID3算法的标准。他们的目的都是将分类的集合更加的纯净,这样在最优化的时候可以更快的达到最优解。
包裹式(wrapper)
与过滤式刚好相反,包裹式选择的特征是在机器学习的过程中,并不像过滤式那样在机器学习前就已经选择好了。也就是说通过机器学习得出的结果来判定那些特征更加适合,**就像特地给脚做一双鞋一样,选择效果最好的,最合适脚的鞋。**可能这就包裹式的由来吧(瞎猜的,小声bb)。
因为其使用机器学习性能来评价特征的好坏,也就是说必须通过多次计算从而对比得出最好的结果,这样的方法缺点也是很明显的,首先是计算量非常大,不像过滤式计算复杂度是常数级的,而它可能是次方级的。其次是其求出来的结果可能是一个局部最优解,类似贪心算法。
未完待续。。。