“我们预计从长远来看,无监督学习将变得更加重要。人类和动物的学习在很大程度上是不受监督的:我们通过观察来发现世界的结构,而不是通过被告知每个物体的名称。”——LeCun, Bengio, Hinton, Nature (2015)。
Semi-Supervised Learning
半监督学习(Semi-supervised learning)使用未标记的数据来获得对总体结构的更多理解。以 Kaggle 上的农场挑战赛为例,来说明半监督学习的重要性。数据集中,测试集有80000张图像,但训练集中只有20000张图像。换句话说,我们只从一个小的训练集中学习特征,因为它是有标签的,我们没有利用包含大量有价值信息的测试集,因为它的图像是没有标签的。因此,我们应该找到一种方法来从大量的未标记数据中学习。现实世界的数据往往就是这样。由于人工标注很昂贵,尤其是在大多数数据集存在的规模上,大型数据集,尤其是企业级数据,可能只有几个标签。
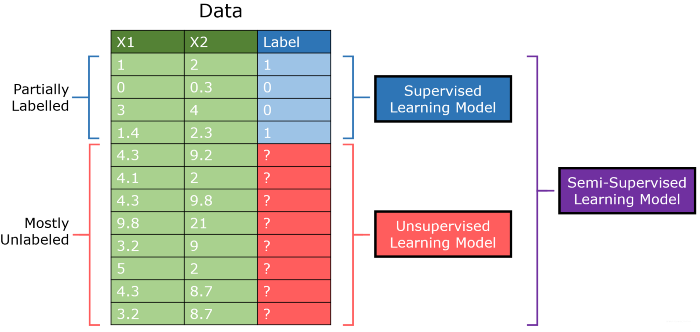
通常,半监督学习算法在以下框架上运行:
- 一个半监督的机器学习算法使用一组有限的标记样本数据来训练自己,产生一个“部分训练”的模型。
- 部分训练的模型标记未标记的数据。因为样本标记的数据集有许多严重的限制,例如,现实世界数据中的选择偏差,所以标记的结果被认为是“伪标记(pseudo-labelled)”数据。
- 标记数据集和伪标记数据集相结合,创建了一个独特的算法,结合了监督和无监督学习的描述性和预测性。
半监督学习使用分类过程来识别数据,并使用聚类过程将其分组为不同的部分。
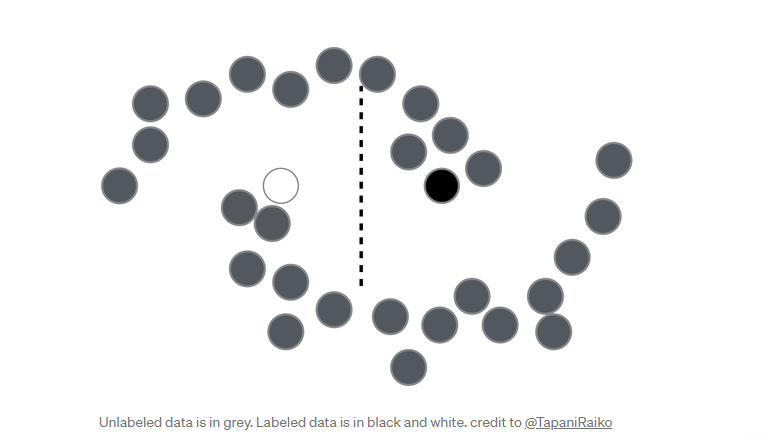
下图,白点和黑点是标注数据,灰点是未标注的。从图片中可以看出,未标记的点以某种方式能够给我们一些有价值的信息,这将帮助我们更多地了解数据的结构。
Pseudo Labeling
伪标签(Pseudo Labeling)是一种简单有效的半监督学习方法。它可以结合几乎所有的神经网络模型和训练方法(伪标签)。如果想从未标记的数据中学习,这里有一个示例:
- 采用与训练集相同的模型,它会带来良好的效果。
- 现在将它与未标记的测试集一起使用,以预测输出或伪标签。我们不知道这些预测是否正确,但现在有了相当准确的标签,这就是在这一步的目标。
- 将训练标签与测试集伪标签连接(Concatenate)起来。
- 将训练集的特征与测试集的特征连接起来。
- 最后,用与之前训练集相同的方式训练模型。
这种方法将使误差减小,并通过更好地学习常规结构来改进模型。
怎么知道每批中真标签和假标签的比例呢?一般的经验法则是让 1 / 4 − 1 / 3 1/4-1/3 1/4−1/3 的批次为伪标签。
Algorithm: Semi-Supervised GAN
半监督网络(Semi-Supervised GAN,SGAN)是生成对抗网络( Generative Adversarial Network ,GAN)的变体,用于解决半监督学习问题。
在传统的GAN中,训练鉴别器(discriminator)从数据集预测图像是真实的还是由生成器模型(generator model)生成的假的,从而允许它从图像中学习鉴别特征,即使没有标签。虽然大多数人通常使用GANs中的生成器来生成真实生成的图像,GANs中的生成器已经过训练,可以生成与数据集相似的图像,但也可以通过迁移学习作为起点来使用鉴别器,在同一数据集上开发分类器,从而使受监督的任务受益于无监督的训练。由于已经学习了大多数图像特征,所以执行分类的训练时间和精度将会好得多。
然而,在SGAN中,鉴别器同时以无监督和有监督两种模式训练:
- 在无监督的情况下,鉴别器需要区分真实图像和生成的图像,就像在传统的GAN中一样。
- 在有监督的情况下,鉴别器需要将图像分类到预测问题中的几个类别中,就像标准的神经网络分类器一样。
为了同时训练这两种模式,鉴别器必须输出 1 + n 1 + n 1+n 个节点的值,其中 1 1 1 代表“真或假”节点, n n n 是预测任务中的类数。
在半监督GAN中,更新鉴别器模型来预测 K + 1 K+1 K+1 个类,其中 K K K 是预测问题中的类数,并为新的“伪”类添加额外的类标签。它包括同时为无监督的GAN任务和有监督的分类任务直接训练鉴别器模型。整个数据集可以通过SGAN传递——当训练示例有标签时,鉴别器的权重被调整,否则,分类任务被忽略,鉴别器调整其权重以更好地区分真实图像和生成的图像。
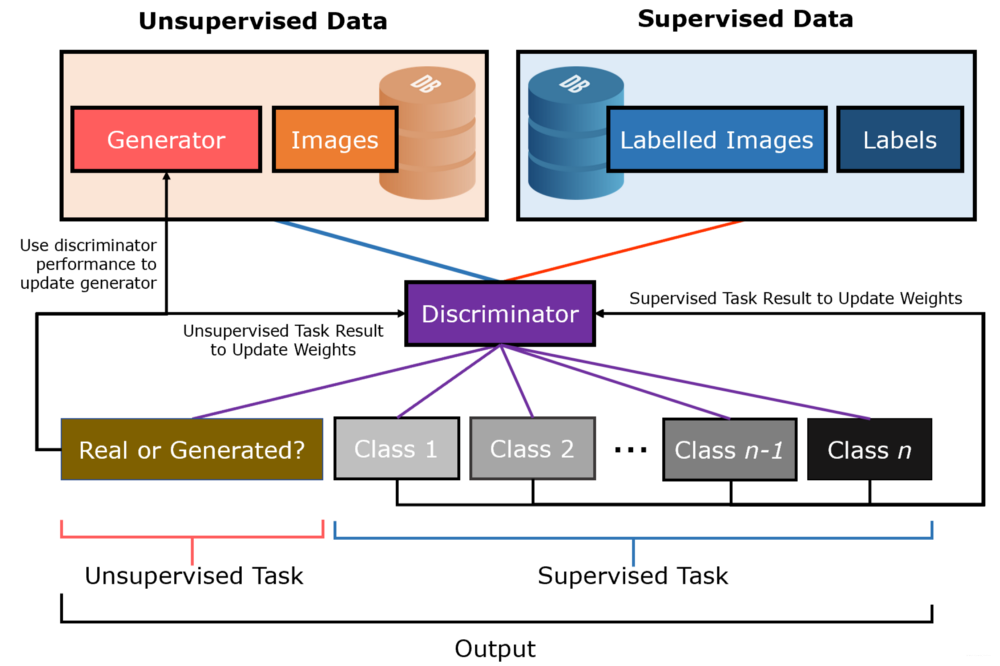
SGAN 允许无监督训练允许模型从非常大的未标记数据集学习提取特征,有监督学习允许模型利用提取的特征并将其用于分类任务。其结果是一个分类器,它可以在标准问题上取得令人难以置信的结果,比如MNIST问题,即使是在非常非常少的标记样本(几十到几百个)上进行训练。
SGAN巧妙地将无监督和有监督学习的各个方面结合起来,相互加强,使之能够一起工作,用最少的标签产生令人难以置信的结果。
Use Cases and the Future of Machine Learning
在一个可用数据量不断呈指数级增长的时代,无标记的数据不能等待被标注,无数现实生活的数据场景都是这样出现的——例如,YouTube视频或网站内容。从引擎和内容聚合系统到图像和语音识别,半监督学习无处不在。
半监督学习将监督学习和无监督学习的“过拟合”和“欠拟合”趋势相结合的能力分别创建了一个模型,在给定最少量的标记数据和大量未标记数据的情况下,该模型可以出色地执行分类任务,同时进行归纳。除了分类任务之外,半监督算法还有许多其他用途,如增强聚类和异常检测。尽管该领域本身相对较新,但随着算法在当今的数字环境中找到巨大的需求,它们正在不断地被创造和完善。
参考:
Simple explanation of Semi-Supervised Learning and Pseudo Labeling
Supervised Learning, But A Lot Better: Semi-Supervised Learning