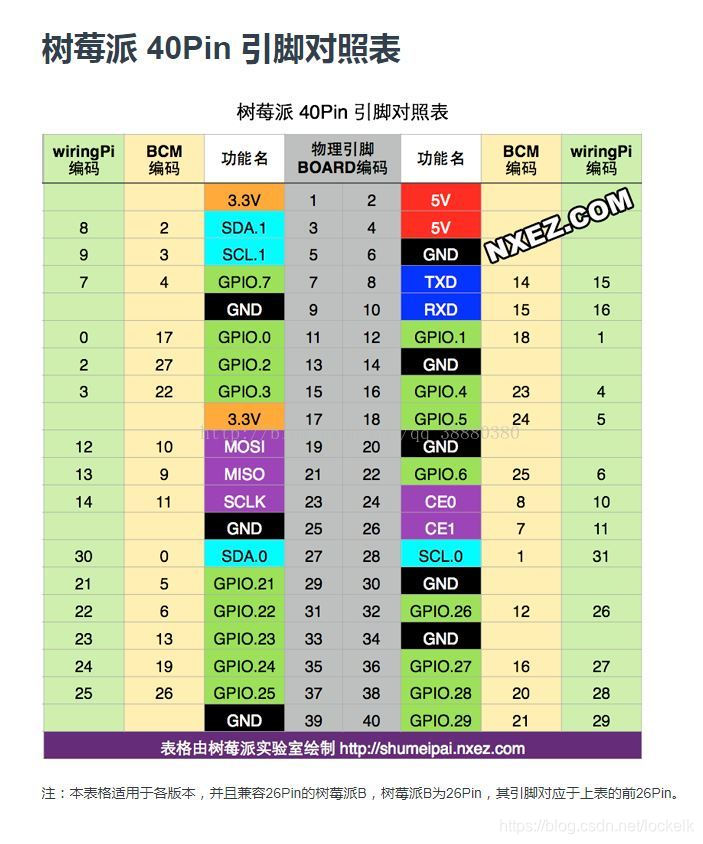
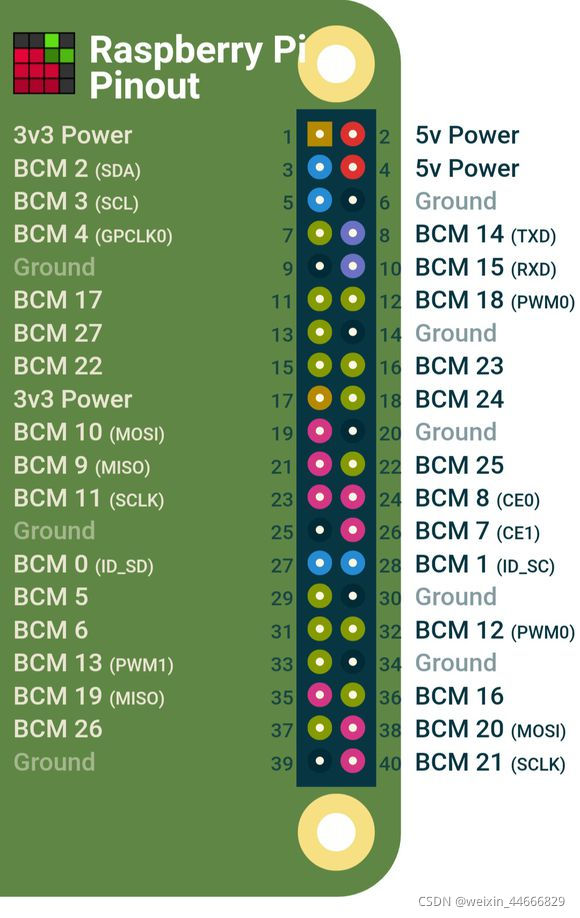
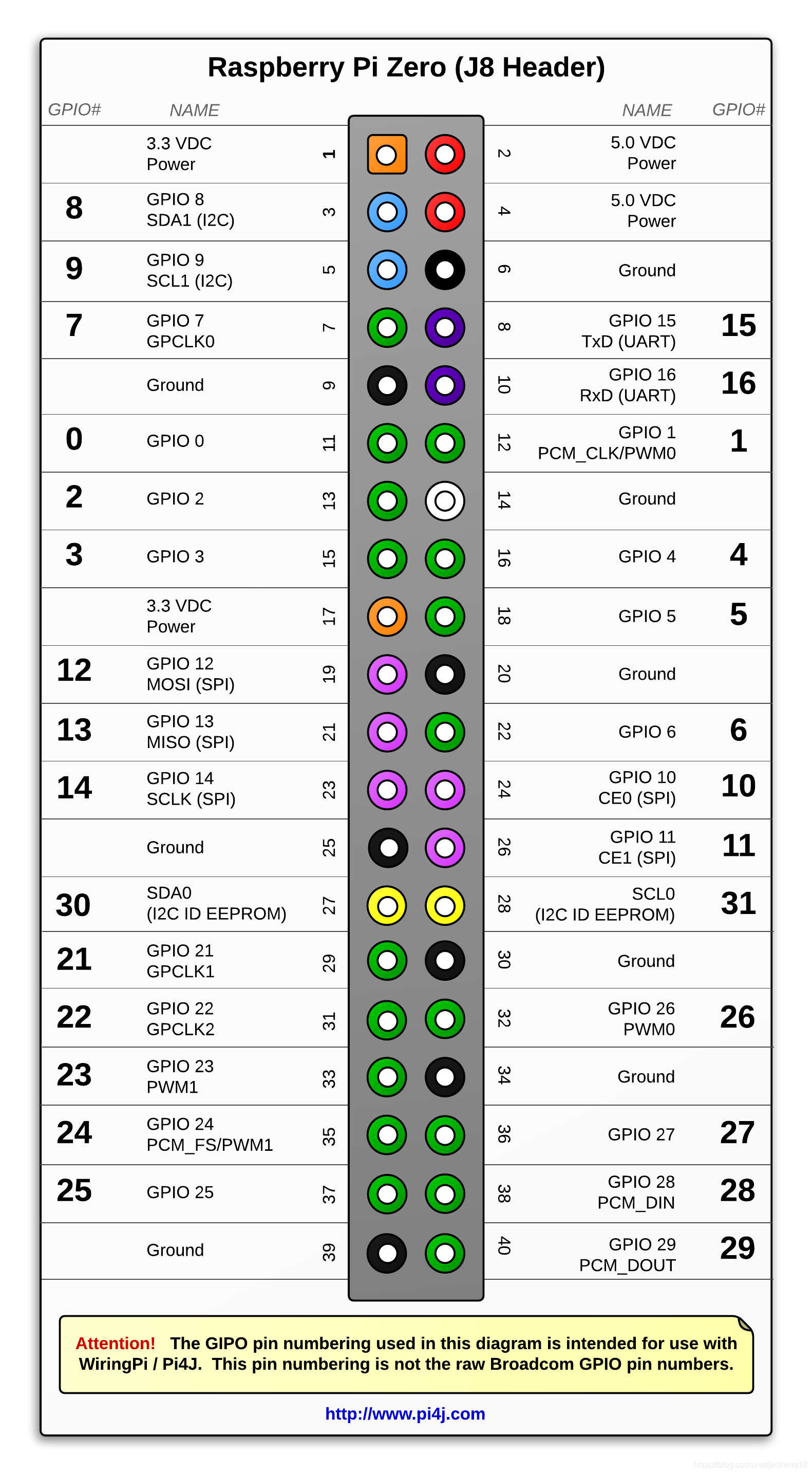
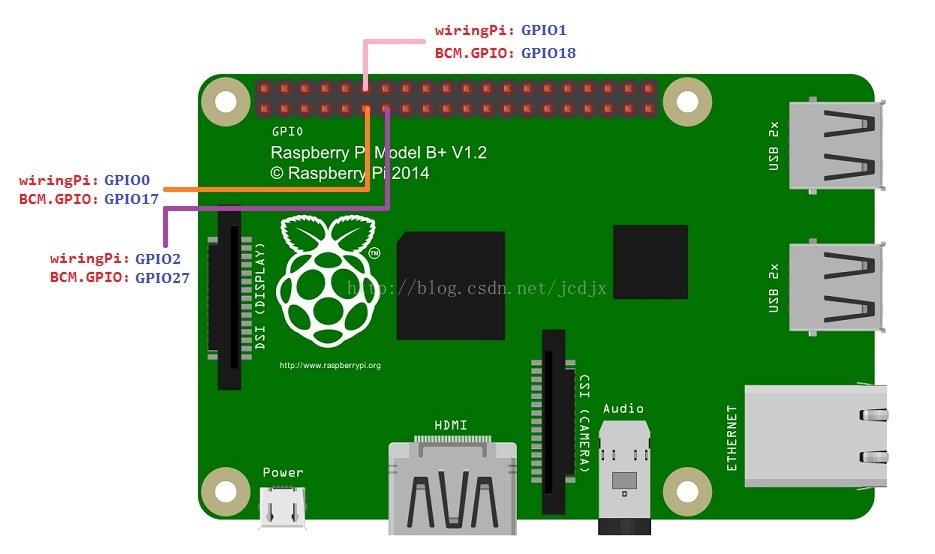
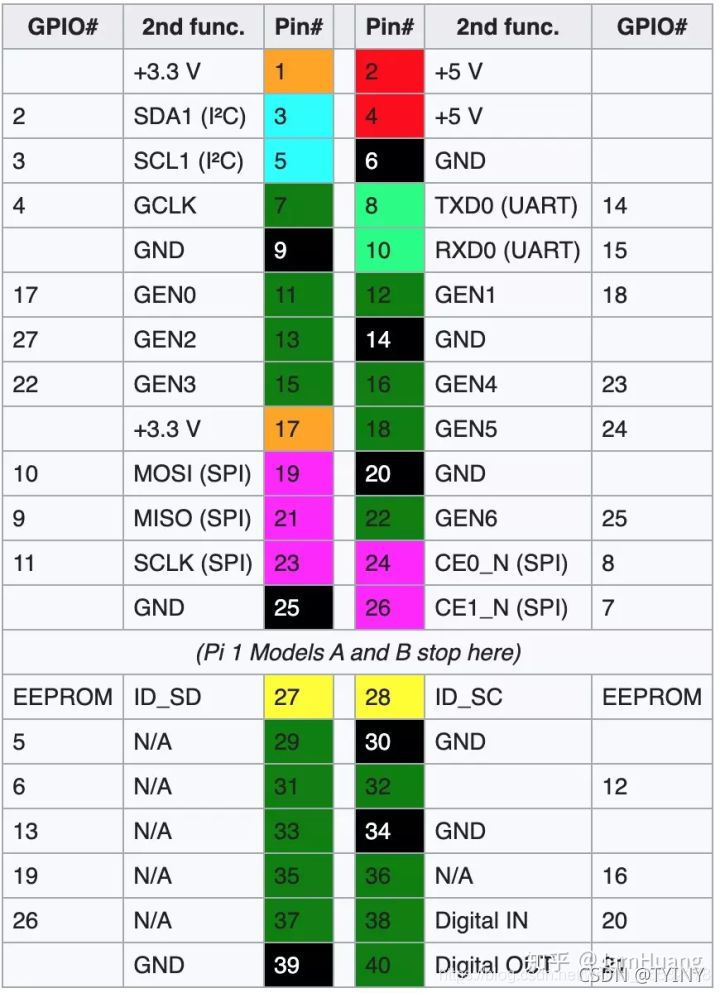
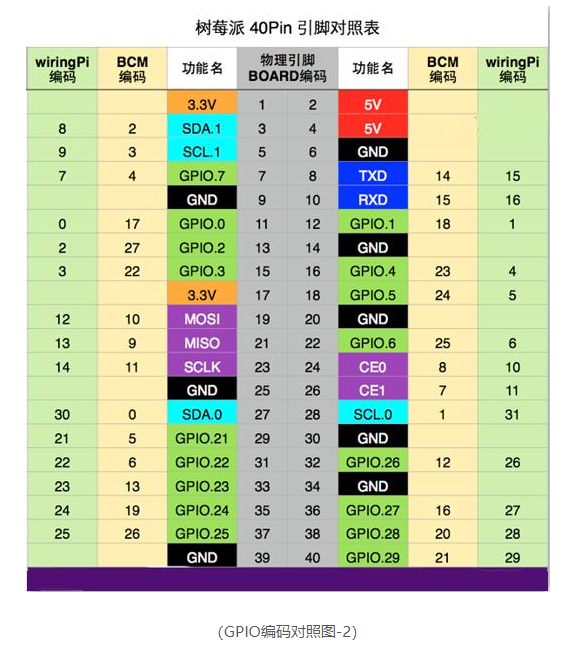
本文主要参考《图像通信技术与应用》作者陈柘 陈川
记录了数字图像的模型、图像变换的数学原理、图像编码的基本思想、
H.26x等视频标准、以及视频的传输模型等概念,只介绍思想,无数学推导,无代码实践,属于音视频入门知识
视频的编码
数字图像概念
人眼视觉模型
人眼感光流程是光线透过晶状体被弯折,弯折程度由睫状肌控制,然后透过玻璃体落在视网膜上,刺激视网膜上的视感知细胞产生神经冲动,于大脑视觉中枢中形成视觉
视感知细胞分为视锥细胞,视杆细胞。前者能区分光的强度和色彩,在明亮环境下敏感,称为亮视觉,后者只能区分光的强度,在低照度环境下敏感,称为暗视觉
在相同光度下,人眼对波长555 nm的黄绿光最敏感。进一步细分会发现,视锥细胞可分为红敏细胞、绿敏细胞、蓝敏细胞,其最敏感的波长的光对应红绿蓝三色。这就是三基色理论
对比效应:人眼分辨力有限,当不同色度、亮度、面积的图像并存时,视觉上会有扭曲感
-
相同的两个红色色块分别放在红色背景,和蓝色背景下,前者的红色会感觉像橘色,后者的感觉像紫色
-
相同的两个彩色色块分别放在灰色背景,和相同彩色背景下,前者的饱和度感觉更弱
-
相同色度和亮度的两个区域,面积越大,人眼感觉亮度和饱和度越强
马赫带效应:相邻神经元的互相抑制现象。一个梯度变化的色带,在变化分界处感觉更暗

视觉暂留:人眼对图像的感觉,在图像消失后呈指数式衰退,但不是立即消失。所以理论上离散图像的变化频率超过24 Hz后,视觉上就形成连续感
人眼的彩色分辨力:人眼对颜色的区分能力远差于对亮度的分辨

人眼的视野:最佳视野范围约左右上下各15°,头部眼球都固定时的最大视野约左右35°和上下40°
色彩与像素
一般的不会发光的物体,其颜色取决于其对环境光的吸收和反射
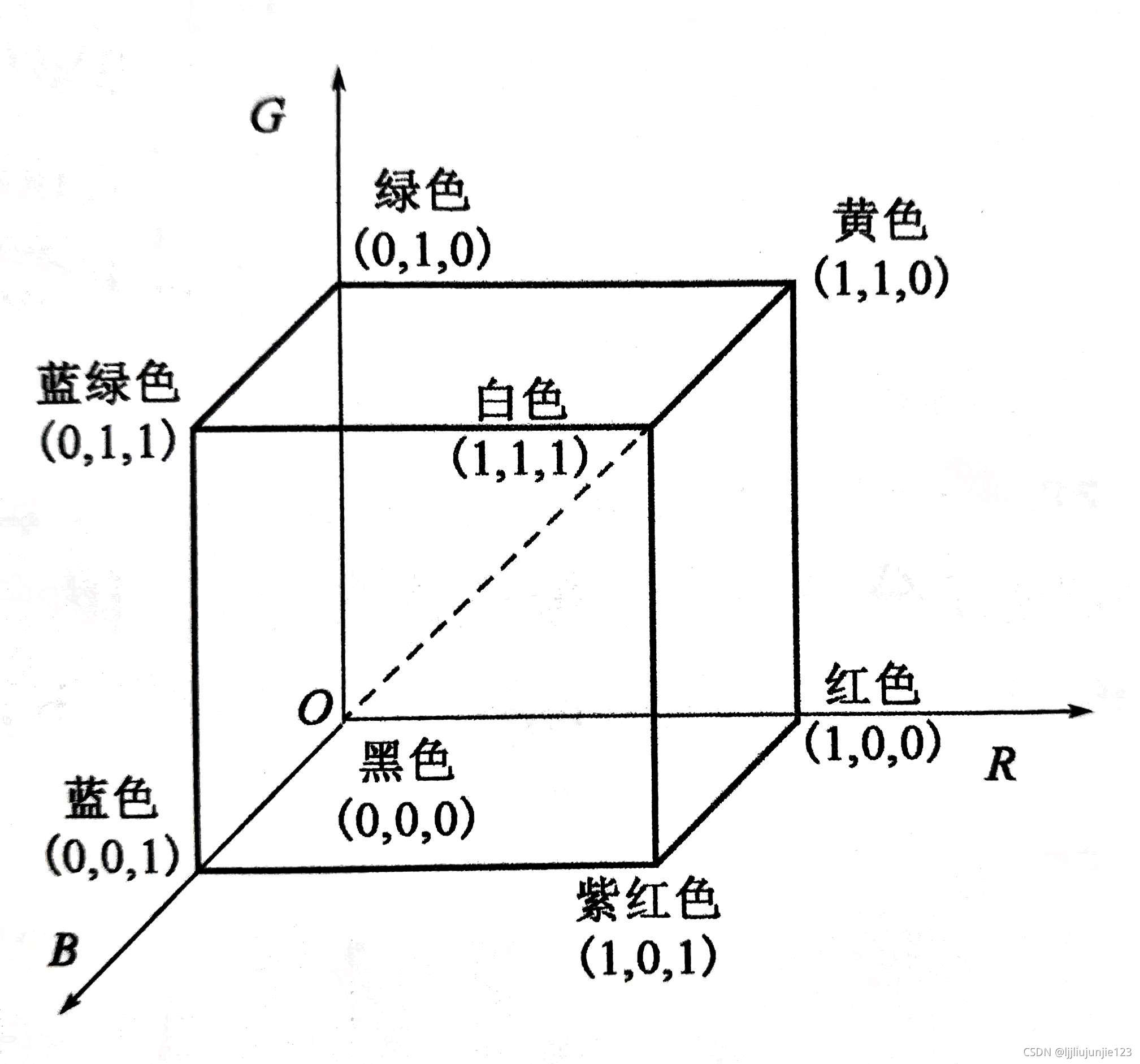
三基色理论用不同比例的红绿蓝色混合,可生成人眼能感知的所有颜色。基于这个理论的色彩模型是最常用的RGB模型,但色彩模型不仅这一个
RGB模型
CMYK模型
印刷使用的模型。因为印刷出的字符的颜色,取决于入射光从颜料上的反射光,所以需要用RGB的反向色来打印。比如想打印红色字体,这里的红色是指人眼感觉它的红的,也就意味着它的反射光只有红色。一般入射光都是白色,所以说明这个颜料能吸收白色中除了红色的部分。根据三基色理论,白光可以近似看成红+蓝+绿,所以这个颜料需要能吸收蓝+绿光。能吸收蓝光的颜料,人眼看它的感觉应该是蓝色的补色,也就是白色 - 蓝色 = 黄色,同理白色 - 绿色 = 紫红色。所以用黄色颜料和紫红色颜料混合打印,字体就看起来是红色的
C:绿+蓝=青,M:红+蓝=紫红,Y:绿+红=黄。为了打印的方便,认为加入K代表黑色。
YUV模型
利用人眼对亮度和色彩的分辨力不同,把一个像素的颜色拆成亮度分量Y和色彩分量UV,后者采样率可以适当降低,人眼无法察觉。可参考一文理解 YUV - 知乎
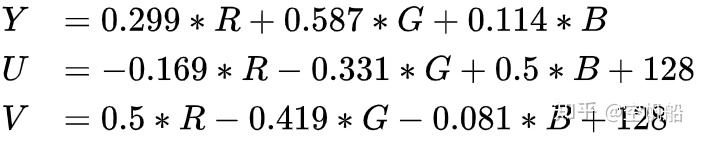
对YUV进行缩放和偏移即可得到视频编码标准中常用的模型 YCbCr。可参考图像色彩编码YUV(YCbCr)的基本知识_老王的技术博客-CSDN博客_ycbcr
HSI模型
将人眼对彩色的感觉分为色调H,饱和度S,亮度I,从这三个分量来定义颜色
最外层是纯色,两端是黑白色,角度代表色调,0-360对应不同的颜色

与RGB转换公式

像素
狭义的像素是光的模拟量通过采样和量化,变成数字量后的表达形式。所以旧式的胶片是没有像素概念的
采样的原理是奈奎斯特采样定理,量化则分为标量量化和矢量量化
图像变换理论
无论是什么图像变换,都是一个集合向另一个集合的映射,信息是不变的,变化的是信息的表现形式。在不同的形式下,做一些特定事情会更方便。而在视频编码中最常做的,就是在尽可能保证人眼对一幅图像的感觉是完整清晰的前提下,尽可能多地删减信息,以降低信息传输码率
傅里叶变换
空间域向频域的映射
f(t,z)是两个连续变量t和z的连续函数,其二维连续傅里叶变换和逆变换定义如下
对其进行离散化,得到离散的二维傅里叶变换和逆变换
f(x,y)是大小M x N的数字图像,u = 0,1,2 ...... M-1,v = 0,1,2 ...... N-1
频域中傅里叶变换系数,大致分为低频系数和高频系数。一张图像变化越剧烈,比如充斥着纹理,高频系数的幅值越大。相反,图像越平滑,低频系数幅值越大。
傅里叶变换的一些数学运算性质如下

余弦变换/DCT变换
傅里叶变换需要进行复数运算,不利于计算机处理,所以余弦变换是其替代品,因为它只需要实数运算
f(x,y)是大小M x N的数字图像,x,u = 0,1,2 ...... M-1,y,v = 0,1,2 ...... N-1
其他
根据高数和线代的基本知识,上述两个变换具有共同的变换核,可以定义为函数g(u,v,x,y)
当M = N时,g(u,x)等于g(v,y)。可以定义一个MxN的矩阵G表示各个变换系数。则余弦变换的矩阵形式为。矩阵的运算在计算机中非常方便
再次观察变换核函数g,当固定u,v时,会发现g函数图像是一个MxN的图像,可以称这个图为基图像。那么遍历u,v,可以得到一系列基图像。那么二维离散的余弦变换可以看成,将一幅图像分解称一系列基图像,余弦变换系数是各个权重。
下图是M = N = 8时的基图像组。

沃尔什-哈达玛变换
这是一个运算速度比余弦变换更快的变换。其理论基础是哈达玛矩阵
一个NxN的哈达玛矩阵H满足
通过一些线代变换,可以得到只包含 +1 和 -1 元素的任意阶哈达玛矩阵。利用这种矩阵与图像进行正交变换时,由于只有加减法,所以自然运算速度快。
K-L变换
前面三种变换都是正交变换,核心思想都是线代的空间映射。K-L变换又叫作霍特林变换,是基于统计特性的变换
将一个NxN的图像矩阵,每一行/列看成一个向量,再把它们放在一起,堪称一个向量 x 的N个取值。那么该向量 x 就可以看作一个随机变量。定义其数学期望和协方差矩阵为
矩阵Cx是一个实对称矩阵,主对角元素表示各个x分量的能量大小,其他元素表示各个分量间的相关性
线代告诉我们,一个N阶实对称矩阵总可以找到一组N个正交的特征向量和特征值。矩阵C是N平方阶,所以有N方个特征向量和特征值。设为e和λ,并假设特征值从大到小排序。把所有e向量作为行向量,排成一个矩阵A,则A的行与行之间是正交的。
我们把A当作一个正交变换矩阵,则K-L变换和逆变换
其中进行逆变换时,如果不使用全部的特征向量,只选择特征值最大的前几个,同样能重构出完整的NxN图像。可以证明,这幅图像与原图的均方误差是剩余的特征值的和。这样就实现了编码的压缩
小波变换
本人这部分还没看懂,想了解参考
小波变换(wavelet transform)的通俗解释(一) - 交流_QQ_2240410488 - 博客园
如何通俗地讲解傅立叶分析和小波分析间的关系? - 知乎
图像编码理论及协议
图像编码的目的是消除数字图像中的冗余信息。冗余分为
-
空间冗余:相邻的像素值接近的像素
-
时间冗余:用于视频序列前后帧图像的关系
-
视觉冗余:利用人眼对图像部分细节的不敏感
-
信息熵冗余:像素平均编码码长大于该图像信息熵,则存在信息熵冗余
信源与信息熵:信息熵的通俗理解
香农率失真理论 【计算机科学与技术】信息论笔记(8):率失真理论_招财猫qwq的博客-CSDN博客_率失真理论
熵编码
熵编码也称信息熵编码,其最重要的特点是可以实现对信源的无失真编码,香农率失真理论表明,信源的熵是保持全部信息条件下对数据实施压缩的下限
基于这种思想设计的编码:香农-范诺编码、霍夫曼编码、算术编码、行程编码
前两者思想相似,根据概率不同分配长短不同的码字,概率越大,码字越短。
算术编码被用在H.263和JPEG协议中。算术编码根据信源符号出现的概率,经过递推的算术运算,将信源输出的符号序列表示为0-1区间的一个子区间,序列越长,该区间长度越短。算术编码使用小数来替代信源符号,理论上可以接近熵的极限值,特别当信源概率分布比较均匀,算术编码效率优于霍夫曼编码。详见 https://segmentfault.com/a/1190000011561822
行程编码又叫作游程长度编码。编码时遇到相同像素连续出现时,用像素值+长度的组合来替代原本的一串像素。详见行程编码压缩算法_Time is a choice-CSDN博客_行程编码算法
变换编码
变换编码模型如下流程图,基本思想是:先通过分块降低编码的码流,然后一般通过正交变换去除图像的空间相关性,在新的正交变换域,变换系数接近统计上的独立分布,能量向直流和少数低频变换系数集中。变换系数量化后通过熵编码传输形成码流,最终在解码端经过上述过程的反变换即可恢复图像。
常见的正交变换在上一章中讲到了很多,其中K-L变换是均方误差意义下的最优变换,但其计算太过复杂,所以一般选择仅次于它的离散余弦变换,该变换法用于 JPEG
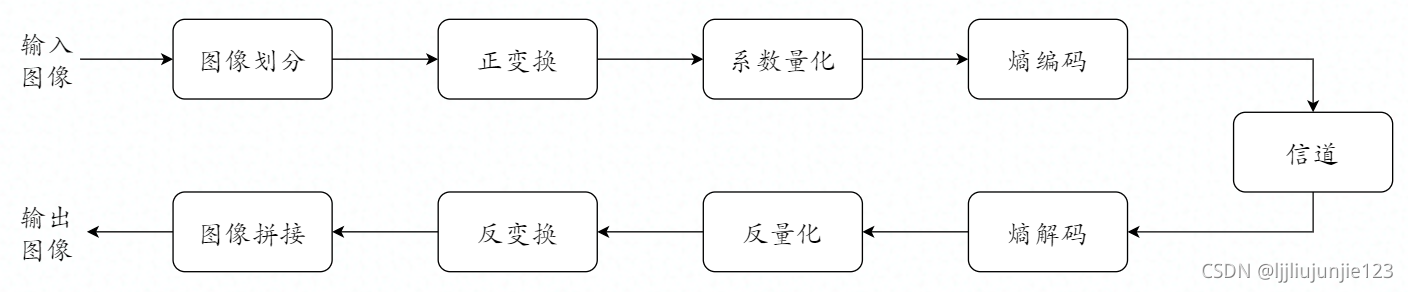
预测编码
预测编码利用的是图像固有的统计相关性,分为
一维预测,或叫作行内预测,用待预测样本在同一行的相关像素预测当前像素
二维预测,或叫作帧内预测,用待预测样本同一行的以及前面若干行的相关像素预测当前像素
三维预测,或叫作帧间预测,用同一帧内同一行以及前面若干行的,以及相邻帧的对应区域的值,编码当前像素
一般的预测方法是线性预测,详见预测编码_qingkongyeyue的博客-CSDN博客_预测编码
矢量量化编码
矢量量化把空间上相邻像素看作一个整体,编码为一个矢量。证明发现相同的量化等级时,矢量量化比标量量化引起的误差小。
按照一定的规则,将图像分成若干个不相交的区域,每个区域选一个点作为代表矢量,称为一个码字,所有码字的结合称为码书。矢量编解码流程如下
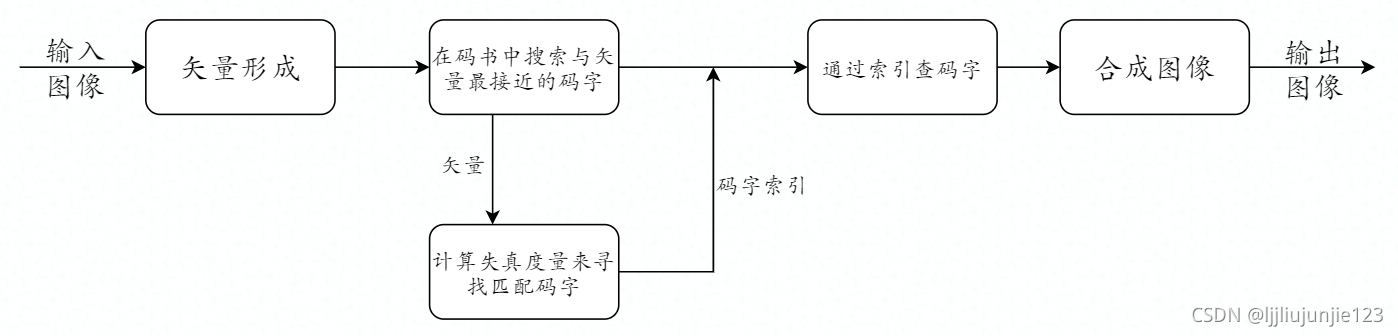
根据流程可以分析,制约这个编码的核心环节是:
-
码书设计:最佳划分准则+最佳码书准则。相关算法有 LBG算法,学习矢量量化(基于神经网络)
-
码字搜索:部分失真搜索算法(
PDS算法)、变换域码字快速搜索算法、均值金字塔码字快速搜索算法 -
码字索引的分配:基于最优化技术,如遗传算法、模拟退火算法、禁忌搜索算法等
JPEG 2000编码协议
JPEG2000之前还有JPEG和JEPG-LS两种协议,但现在更多用的是前者,所以本文只关心一个。
首先要理解什么是编码协议,我们接触最多的可能是https协议,所以表意的理解,协议规定了一个问题的解决方式,你可以优化细节,但大方向必须得是一样的,就像网站的样子长得千奇百怪,但网站地址格式是大同小异。
图像编码协议就规定了图像编解码以及传输过程中的算法和数据格式。
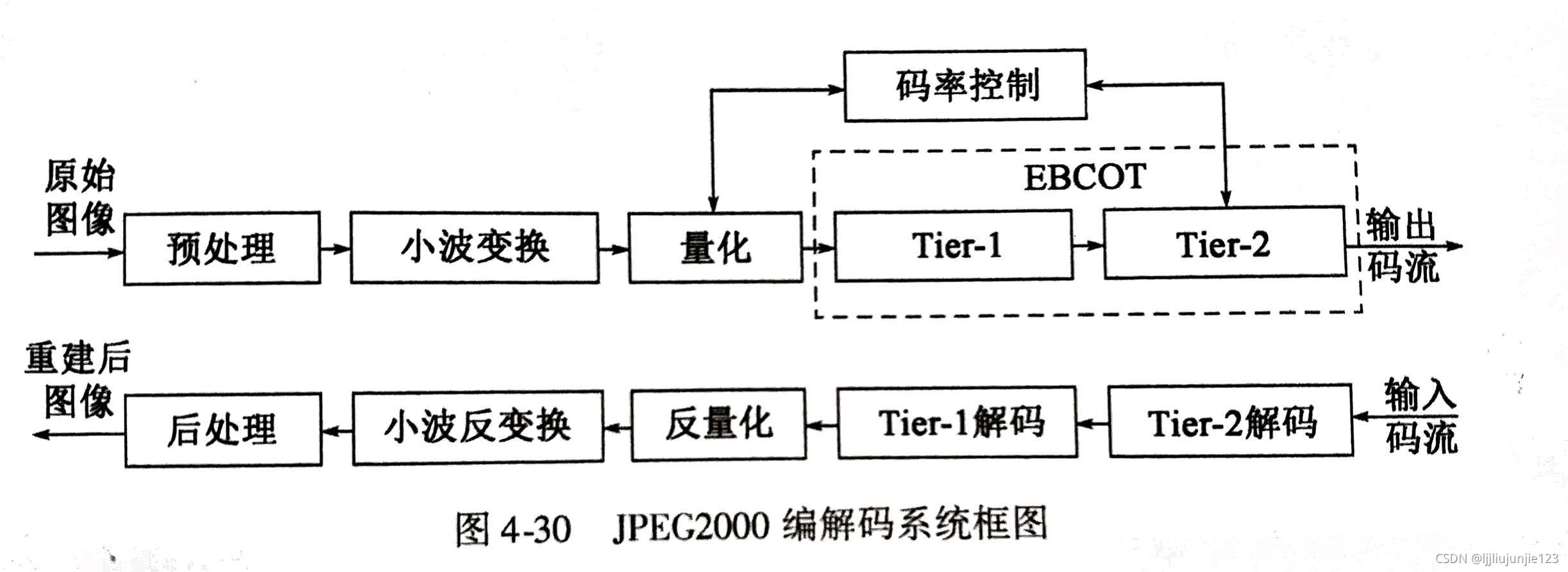
核心技术之一是离散小波变换
该协议的特点:
-
高压缩率
-
无损和有损压缩:通过参数控制即可
-
适应连续色调以及二值图像
-
码流渐进控制:允许按照所需的分辨率传输码流,接收端获得所需分辨率的图像后可以终止解码,不必传输全部图像
-
ROI(Region of Interest)解码技术 -
容错性高
-
可扩展性:除核心算法外的部分可以嵌入用户的具体功能模块
视频编码理论及协议
基于波形的编码
主要利用的是帧间的相关性。将序列图像中,将一幅图像划分成背景区、运动物体区和暴露区。相邻帧的背景区绝大部分数据相同,而运动物体的移动暴露出背景的一部分称为暴露区,这部分可用缓存做记录
-
帧重复方式:对于变化缓慢的部分,通过抽帧和跳帧减少数据量,恢复时通过复制相邻帧
-
条件帧修补法:将第k帧的像素作为第k+1帧对应点像素的预测值,把真实值和预测值做差得到误差值,可以认为误差值小于一定阈值时,用预测值替代真实值,也就不用传输该点。如果大于,就把误差值传输过去,在接收端通过第k帧的值,加上该误差值得到k+1帧值
-
运动补偿帧间预测法:要进行预测的是当前帧,其前后帧作为参考帧。寻找当前帧像素所属的运动物体,在参考帧中的位置,这个过程叫作运动预测。运动物体在参考帧中相对当前帧的位置偏移称为运动矢量。
-
物体划分
-
运动估计
-
运动补偿
-
预测编码
-
基于内容的编码
上一代编码的对象是像素,而这一代是物体或区域的形状、纹理和运动等参数
物体基编码
通过一个能够描述物体形状和运动的参数模型来表示视频图像中的物体,在收发端使用相同的物体模型
基本的物体模型有四种:二维刚体模型、二维柔体模型、三维刚体模型、三维柔体模型
对图像划分的基本概念是MC区域,可以用已有模型表达的区域和MF区域,不能用已有模型表达的区域
知识基编码
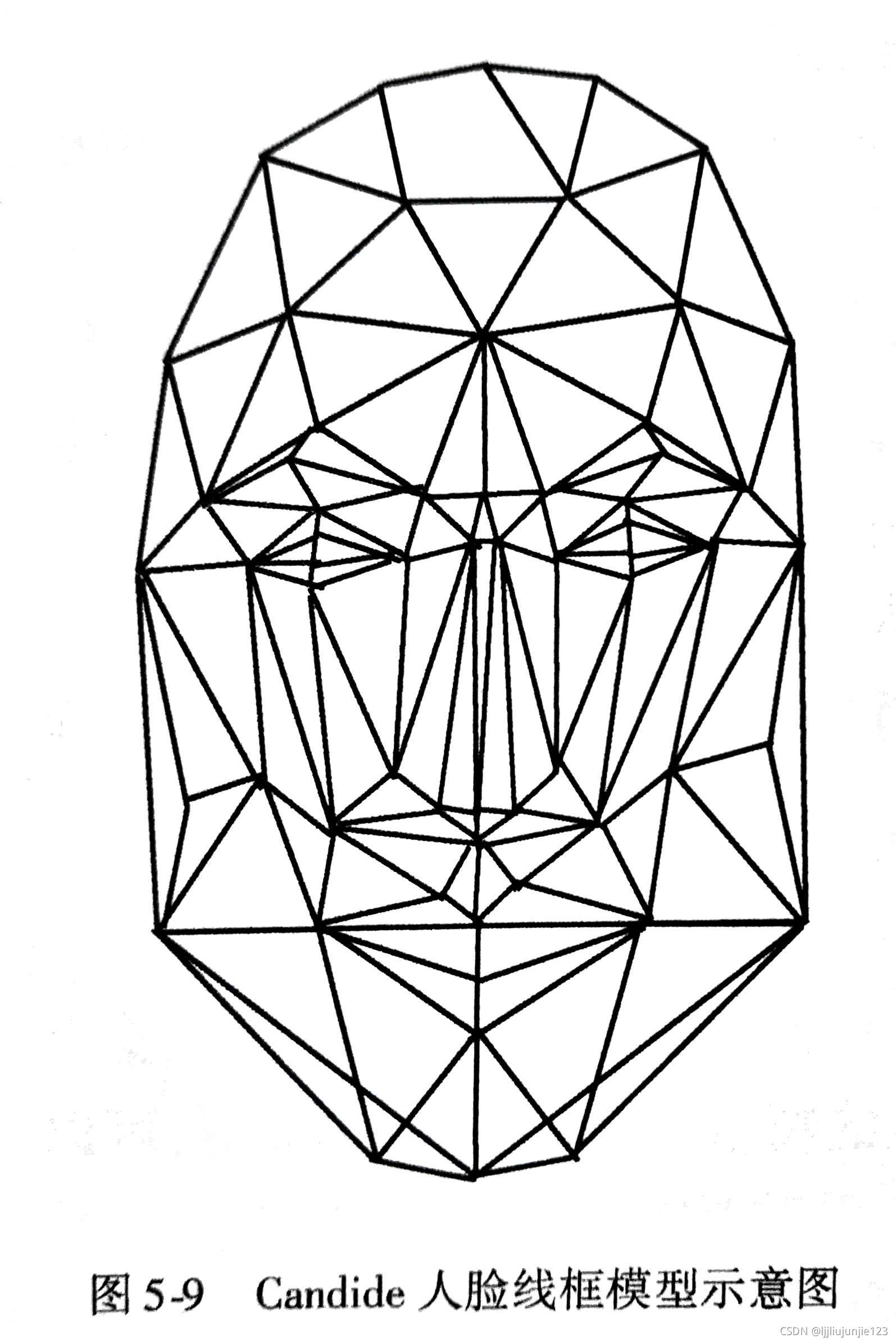
基于对物体的先验知识来对物体建模,比如人脸模型
在一些情况下,这种编码比物体基编码压缩率更高,因为物体基的模型是泛化模型,而这里的模型是针对具体物体设计的,表征能力更强
最通用的Candide人脸线框模型如图
语义基编码
语义基是在知识基的层次上,更高的抽象,用更简洁的表达来描述物体。以人脸为例,知识基编码需要传递人脸模型每个节点的矢量关系,但是语义基希望能从这些关系的组合中识别出表情的概念,如喜怒哀乐等等,这样传输时只需要一个表情的种类就行,远远小于人脸模型的节点数值。
目前研究最多的语义基就是人脸表情,比较成功的`FACS和FAP系统,能用不到100个参数描述头部运动和脸部表情
H.26X与MPEG-X编码
目前视频编码标准大体分为两类,分别是针对视频会议、可视电话等实时视频通信业务的H.26X系列,包括H.261, H.262, H.263, H.264, H.265,和面向视频数据存储、网络传输等应用的MPEG-X系列,包括MPEG-1, MPEG-2, MPEG-4, MPEG-7, MPEG-21
两套标准有一定的合作,H.262作为MPEG-2的视频部分,H.264作为MPEG-4的视频部分
关于每种编码格式的细节,可以参考以下文章
二、主流视频编码标准的发展:H.261\H.263\MPEG-1\MPEG-2\MPEG-4_叮咚的博客-CSDN博客
https://juejin.cn/post/6844904083904528392
https://juejin.cn/post/6877841773436076040#heading-6
H.265/HEVC编码
这是目前比较新的编码标准,还没有大范围普及,设计目标是支持4K乃至更高分辨率的超高清画质视频
它的一些核心特点使其具有比现行标准比特率少50%
-
自适应的编码方式和参数。宏块大小不固定
-
DCT整数变换 -
支持
4x4的离散正弦变换 -
新增自适应环路滤波
-
并行化设计
H.265(HEVC)深度解析_xiaojun11的专栏-CSDN博客
图像及视频的传输理论
传输模型
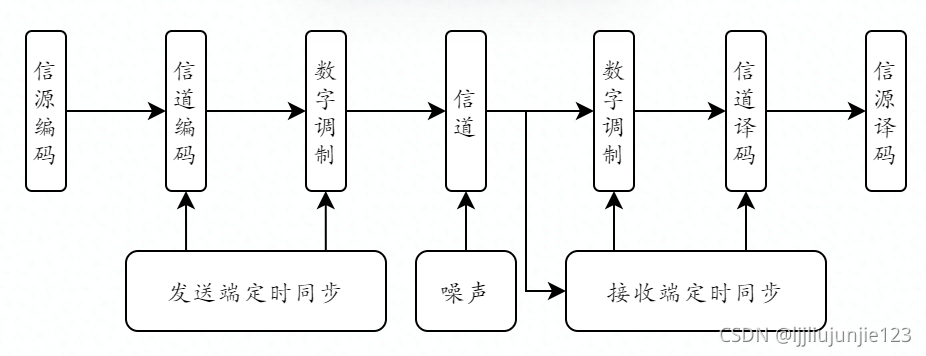
信道是传输信息的通道,对应的实物如光纤、同轴电缆、卫生、微波、无线电等等
码率控制
码率是比特数的速率,这里的码可以理解为二进制码。之所以要控制码率,是因为信道的带宽是有限的,且是随时间变化的,为了适应这一特点,才开发出控制码率的技术
基本的控制思想是在视频编码与信道之间加入一个缓冲器,先将编码好的码流缓存到缓冲器中,再从缓冲器中以信道码率发送数据。同时从缓冲器发送一个信号到码率控制器,这个信号比如是缓冲器的空余大小,然后码率控制器据此控制视频编码器,这样形成一个负反馈调节
码率的控制并不是单一的,而是分层的。
-
图像层码率控制:根据编码器输出目标码率、系统延迟、缓冲器饱和度等确定码率分配策略
-
宏块层码率控制:根据图像层码率的控制目标,分配各个宏块的量化步长
典型常用的码率控制算法:
-
MPEG-2 TM5码率控制算法 -
MPEG-4 VM8码率控制算法 -
H.263 TMN8码率控制算法 -
H.264码率控制算法
差错控制
所有的信道都是有噪声的,信息在有噪声的信道上传输时,有概率失真
传输的错误分为随机错误和突发错误。随机错误是比特值的倒置、插入或丢失,突发错误是连续的码字错误、或丢包
在H.264标准下,不同层次的码流错误的影响不同:
-
序列头:序列头包含视频空间分辨率、帧速率等信息,出错导致整个序列解码失败
-
图像头:图像头包含图像编码模式、时间戳,出错该图像解码失败。如果该图像被作为参考图像,其错误会影响到其余图像
-
块组头和宏块头:块组是该标准下最小的编码单位,出错该块无法解码
-
块组数据:如果出错后数据长度不变,可正常解码,反之无法解码
传输的错误会沿着时间轴传播,还会沿着空间域扩散。根据不同的编码标准,影响范围不同
差错控制分为如下层次
-
编码端差错控制
-
又称为容错编码,即引入冗余数据来增强抗误码能力
-
增加同步标记:周期性插入同步标记进行错误隔离
-
数据分割:不同重要程度的语法元素用不同的编码策略、以及不同的信道来传输
-
容错预测:周期性发送一些帧内编码帧或块,来隔绝错误在时间轴上的传输
-
分层编码:将图像编码为一个基本层和多个增强层
-
-
传输层差错控制
-
主要技术是纠错编码
-
前向差错纠正:发送端的码流中加入监督码元,比如奇偶校验码,汉明码等,接收端利用监督码元纠错
-
自动请求重传
-
信息反馈:接收端把接收的信息原封不动地传回发送端,发送端比较信息流是否与原信息相同,如不同则重发
-
混合纠错
-
不平等差错保护
-
常用的纠错码及相关技术非常多,如奇偶校验码、线性分组码、循环码、
BCH码、交织码、RS码、CRC码、卷积码
-
-
解码端错误掩盖
-
空间域:用相邻数据块的像素值进行内插
-
时间域:用相邻帧的图像经过运动补偿后,替代该帧图像
-
流媒体
流媒体是指将一份较大的视频文件,分割成一系列较小的数据包,并按视频播放顺序串联,在IP网络上依次发送给客户端。客户端接收到一定数量的数据包后即可播放视频,无需等待传输完整个视频文件
to do:流媒体协议、流媒体技术实践、android下的流媒体