0x00 前言
上篇分享了如何申请到Twitter api,申请到twitter API后就可以进行爬虫啦!这里分享一下如何使用API对用户推文时间线爬虫
Twitter 是有分享如何使用API爬虫的python代码的,但是具体如何使用,以及各种参数如何设置需要用户自己去配置,这里分享一下如何设置和使用其中爬取用户推文的部分。
0x01 具体步骤
Twitter-API-v2-coda Github地址:https://github.com/twitterdev/Twitter-API-v2-sample-code
详解部分为:Twitter-API-v2-sample-code-main/User-Tweet-Timeline/user-tweets.py
1.首先在twitter developer platform:https://developer.twitter.com/en/apply-for-access 注册一个APP
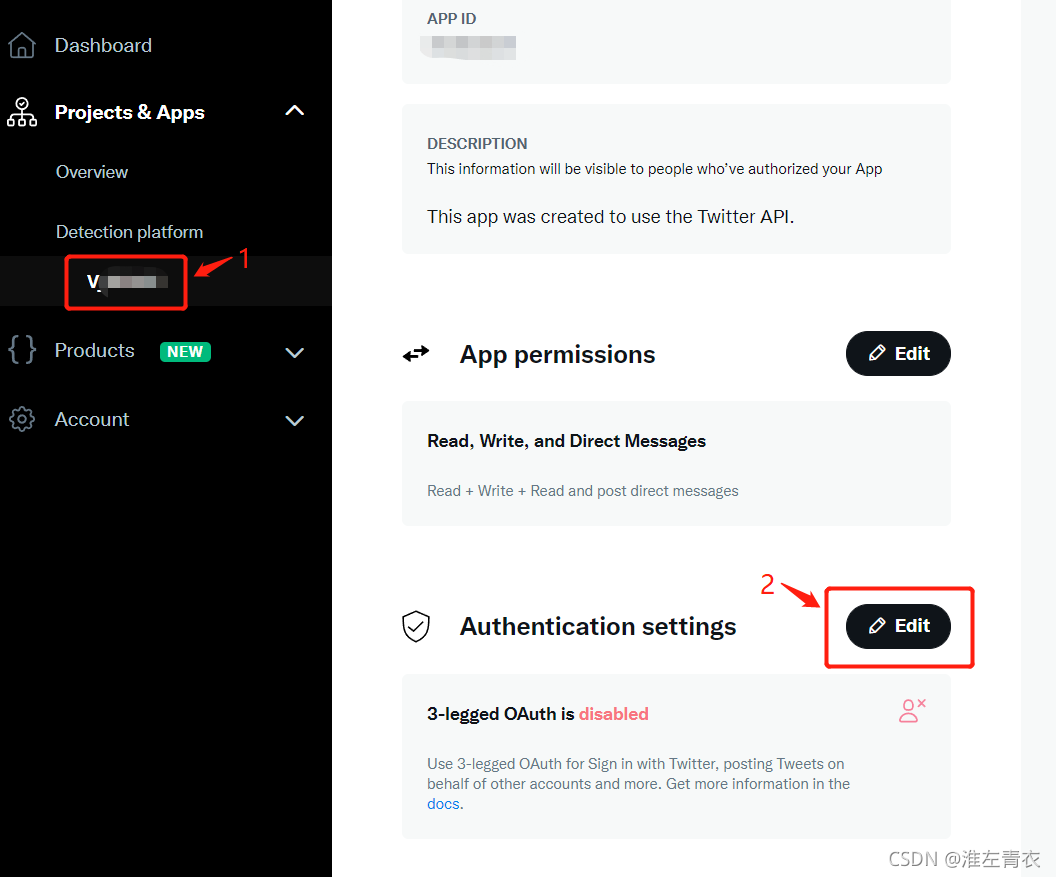
2. 代码分析

代码中bearer_token:上图中2位置的token 就是bearer_token部分,直接粘贴在代码就OK,注意保存这个token,因为下一次打开就是新的token啦。
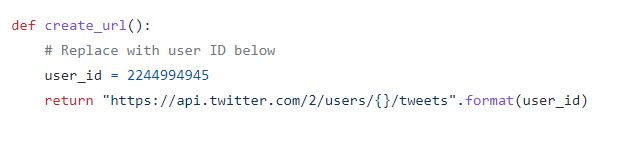
这部分中,user_id很好理解,在其中输入你要爬取的用户ID即可,爬取多个用户就改成一个list.
url部分可操作性很多,这是我设置的url.更多可以参考:https://developer.twitter.com/en/docs/twitter-api/tweets/timelines/introduction
url ="<https://api.twitter.com/2/users/{}/tweets?{>}&max_results=100&exclude=retweets&start_time=2021-05-01T00:00:01Z&end_time=2021-06-01T00:00:01Z".format(user_id,tweet_fields)
#max_results:最大返回数,最多能返回的tweets数
#exclude=retweets:排除转发的推文
#start_time,end_time :起止时间
#tweet_fields:get_params中获取,但是要得到两个返回值的话,需要改成我下面设置的格式使用
url = "<https://api.twitter.com/2/users/{}/tweets?{>}&max_results=100&pagination_token={}&exclude=retweets&start_time=2021-05-01T00:00:01Z&end_time=2021-06-01T00:00:01Z".format(user_id, tweet_fields,pagination_token)
#pagination_token:获取到的推文>返回的最大值时,会产生一个pagination_token,即获取下一页。

get_params,可选你要爬取的部分,但是要注意格式,比如我要获取的内容有hasttags,mentions,urls,reply count,retweet count,favorite count. 这些内容在public_metrics,emtities 中可以获得 。注:两个返回值需要改成tweet_fields = “"而不是原来的“tweet_fields ”: "”
tweet_fields = "tweet.fields=public_metrics,entities"
Twitter 有一份参考说明可以找到要找到的内容在哪里:https://developer.twitter.com/en/docs/twitter-api/tweets/timelines/introduction

这部分不用改,就是调用了上面的bearer_token,以及说明了是用v2版本的API
后面直接运行他的代码就可以得到你想要的值啦,
0x02 源码分享
附我对这个代码进行的一些改动可获得推文的id,content,hasttags_count,mentions_count,urls_count,reply_count,retweet_count,favorite_count.
并存储在csv文件中或Mysql数据库中。
#use twitter api
import time
import requests
import threading
import random
import pandas as pddef __init__(self,keyword):threading.Thread.__init__(self)self.keyword = keywordself.bearer_token = 'AAAAAAAAAAAAAAAAAAAAAOHKRwEAAAAAXF5NOvPXXUPATBLLo12cvyhKOl4%3D75zRjigC4imC02b0gP3l1ily5QAcRkyMQt1UHbM4JE5xQ6Jq5i'self.next_token = ""
# To set your environment variables in your terminal run the following line:
# export 'BEARER_TOKEN'='<your_bearer_token>'def create_url(self,id):# Replace with user ID belowuser_id = id# return "<https://api.twitter.com/2/users/{}/tweets>".format(user_id)tweet_fields = "tweet.fields=public_metrics,entities"# print(tweet_fields)# print("<https://api.twitter.com/2/users/{}/tweets?{>}".format(user_id,tweet_fields))#url:+except,time->&exclude=retweets&start_time=2021-08-14T00:00:01Z&end_time=2021-08-28T00:00:01Zif self.next_token == "":#***************change time here********************url ="<https://api.twitter.com/2/users/{}/tweets?{>}&max_results=100&exclude=retweets&start_time=2021-05-01T00:00:01Z&end_time=2021-06-01T00:00:01Z".format(user_id,tweet_fields)# url = "<https://api.twitter.com/2/users/{}/tweets?{>}&max_results=100".format(user_id,tweet_fields)#&exclude=retweets&start_time=2020-10-1T00:00:01Z&end_time=2021-10-1T00:00:01Zelse:pagination_token = self.next_tokenurl = "<https://api.twitter.com/2/users/{}/tweets?{>}&max_results=100&pagination_token={}&exclude=retweets&start_time=2021-05-01T00:00:01Z&end_time=2021-06-01T00:00:01Z".format(user_id, tweet_fields,pagination_token)# "<https://api.twitter.com/2/users/{}/tweets?{>}&max_results=100&pagination_token={}&exclude=retweets&start_time=2020-10-1T00:00:01Z&end_time=2021-10-1T00:00:01Z"return urldef get_id(self):#注释掉的这部分为从数据库中调取id# id = []# db = mysql.connector.connect(host='localhost', user='root', password='000000', port=3306, db='FindBOT',auth_plugin='mysql_native_password')# cursor = db.cursor()# try:# cursor.execute("select * from %s" % (self.keyword) + "_bot_list where (mark = '0')")# results = cursor.fetchall()# for row in results:# if row[4] == 0:# id.append(row[0])# try:# cursor.execute("update %s" % (self.keyword) + "_bot_list set mark = '1' where id ='%s '" % (row[0]))# db.commit()# except Exception as e:# traceback.print_exc(e)# db.rollback()# print("defalt update")# except Exception as e:# traceback.print_exc(e)# db.rollback()# print("defalt select")# db.close()# ***************change bot/user id here********************#从csv文件中获取id listpath = "your path"df = pd.read_csv(path)ids = list(df['id'])marks = list(df['mark'])dict_results = dict(zip(ids, marks))id = list(filter(lambda ids: dict_results[ids] < 1, ids))return iddef bearer_oauth(self,r):"""Method required by bearer token authentication."""r.headers["Authorization"] = f"Bearer {self.bearer_token}"r.headers["User-Agent"] = "v2UserTweetsPython"return rdef connect_to_endpoint(self,url):proxies = {"http": "<http://127.0.0.1:7890>", "https": "<http://127.0.0.1:7890>", }# 这里设置了一个代理,因为国内可能连不上,但是不用好像也可以爬出来。response = requests.request("GET", url, auth=self.bearer_oauth, proxies=proxies)if response.status_code != 200:raise Exception("Request returned an error: {} {}".format(response.status_code, response.text))return response.json()#entities_feature get one page feature(max_results)
def entities_feature(self,response):id = []content = []hashtags_count = []mentions_count = []urls_count = []hashtags = []mentions = []urls = []like = []reply = []retweet = []try:for i in range(0,len(response['data'])):id .append(response['data'][i]['id'])content.append(str((response['data'][i]['text'])))if response['data'][i]['public_metrics'] :like.append(response['data'][i]['public_metrics']['like_count'])reply.append(response['data'][i]['public_metrics']['reply_count'])retweet.append(response['data'][i]['public_metrics']['retweet_count'])else:like.append(0)reply.append(0)retweet.append(0)continuehashtag_str = ""mention_str = ""url_str = ""if 'entities' not in response['data'][i].keys():hashtags.append("null")mentions.append("null")urls.append("null")hashtags_count.append(0)mentions_count.append(0)urls_count.append(0)continueelse:entities = response['data'][i]['entities']if 'hashtags' in entities:hashtags_count.append(len(response['data'][i]['entities']['hashtags']))for j in range(0, len(response['data'][i]['entities']['hashtags'])):if j < len(response['data'][i]['entities']['hashtags']) - 1:hashtag_str += response['data'][i]['entities']['hashtags'][j]['tag'] + ";"else:hashtag_str += response['data'][i]['entities']['hashtags'][j]['tag']hashtags.append(hashtag_str)else:hashtags_count.append(0)hashtags.append("null")if 'mentions' in entities:mentions_count.append(len(response['data'][i]['entities']['mentions']))for j in range(0, len(response['data'][i]['entities']['mentions'])):if j < len(response['data'][i]['entities']['mentions']) - 1:mention_str += response['data'][i]['entities']['mentions'][j]['username'] + ";"else:mention_str += response['data'][i]['entities']['mentions'][j]['username']mentions.append(mention_str)else:mentions_count.append(0)mentions.append("null")if 'urls' in entities:urls_count.append(len(response['data'][i]['entities']['urls']))for j in range(0,len(response['data'][i]['entities']['urls'])) :if j < len(response['data'][i]['entities']['urls'])-1:url_str += response['data'][i]['entities']['urls'][j]['url'] +";"else:url_str += response['data'][i]['entities']['urls'][j]['url']urls.append(url_str)else:urls_count.append(0)urls.append("null")except :print("*"*30)# print(response)data = []for i in range(0,len(id)) :data.append([id[i],content[i],retweet[i],reply[i],like[i],hashtags_count[i],mentions_count[i],urls_count[i],hashtags[i],mentions[i],urls[i]])return datadef save_data(self,data):#此次可该为Mysql数据库存储# for a in data:# db = mysql.connector.connect(host='localhost', user='root', password='000000', port=3306, db='FindBOT',# auth_plugin='mysql_native_password', charset="utf8mb4")# cursor = db.cursor()# try:# cursor.execute(# "INSERT IGNORE INTO %s" % self.keyword + "_bot_tweets ( id,content,retweet_count,reply_count,favorite_count,hashtags_count,mentions_count,urls_count,hashtags,mentions,urls) VALUES ('%s',\\'%s\\','%d','%d','%d','%d','%d','%d','%s','%s','%s')" % (# a[0], escape_string(a[1]), a[2], a[3], a[4], a[5], a[6], a[7], a[8], a[9], a[10]))# db.commit()# # print("success")# except mysql.connector.Error as err:# print("****************************************")# print(a)# print("Something went wrong: {}".format(err))# print("****************************************")# # traceback.print_exc(e)# db.rollback()# db.close()# ***************change save csv here********************df = pd.read_csv('51_61.csv')haven_id = list(df['id'])haven_content = list(df['content'])haven_retweet_count = list(df['retweet_count'])haven_reply_count = list(df['reply_count'])haven_favorite_count = list(df['favorite_count'])haven_hashtags_count = list(df['hashtags_count'])haven_mentions_count = list(df['mentions_count'])haven_urls_count = list(df['urls_count'])for a in data :if a[0] in haven_id :continueelse:haven_id.append(a[0])haven_content.append(a[1])haven_retweet_count.append(a[2])haven_reply_count.append(a[3])haven_favorite_count.append(a[4])haven_hashtags_count.append(a[5])haven_mentions_count.append(a[6])haven_urls_count.append(a[7])# marks = [1]*len(haven_id) mark是我用来标记用户的。没啥用marks = list(df['mark'])data = {'id': haven_id, 'mark': marks,'content':haven_content,'retweet_count':haven_retweet_count,'reply_count':haven_reply_count,'favorite_count':haven_favorite_count,'hashtags_count':haven_hashtags_count,'mentions_count':haven_mentions_count,'urls_count':haven_urls_count}df = pd.DataFrame(data)# ***************change save csv here********************df.to_csv('**.csv', index=False)def get_feature(self,url):json_response = self.connect_to_endpoint(url)feature = self.entities_feature(json_response)# print(json.dumps(json_response, indent=1, sort_keys=True))if 'next_token' in json_response['meta'].keys():self.next_token = json_response['meta']['next_token']else:self.next_token = ""return featuredef run(self) :ids =self.get_id()for id in ids :try:print(id)url = self.create_url(id)print(url)feature = self.get_feature(url)print(feature)while self.next_token != "" :next_feature = []new_url =self.create_url(id)next_feature = self.get_feature(new_url)for value in next_feature :feature.append(value)if feature == []:#+logcontinueelse:self.save_data(feature)time.sleep(sleeptime)except:# +logcontinue
if **name** == '**main**':
crawl_by_api("china").run()
0x03 一些闲话
本人创建了一个公众号,分享科研路上的小问题,新发现,欢迎关注公众号,给我留言!!!
一起奋发向上,攻克难题吧~~