在上一部分中,我们介绍了句法分析中的局部句法分析以及依存关系分析(自然语言处理NLP(9)——句法分析c:局部句法分析、依存关系分析),至此,繁复冗长的句法分析部分就结束了。
在这一部分中,我们将要介绍NLP领域的一个重要问题:语义分析。
语义分析分为两个部分:词汇级语义分析以及句子级语义分析。
这也就是为什么在词法分析和句法分析之后,我们要介绍的是语义分析而不是篇章分析的原因。
【一】词汇级语义分析
首先,我们来介绍词汇级语义分析。
词汇级语义分析的内容主要分为两块:
1.词义消歧
2.词语相似度
二者的字面意思都很好理解。其中,词义消歧是自然语言处理中的基本问题之一,在机器翻译、文本分类、信息检索、语音识别、语义网络构建等方面都具有重要意义;而词语语义相似度计算在信息检索、信息抽取、词义排歧、机器翻译、句法分析等处理中有很重要的作用。
词义消歧
自然语言中一个词具有多种含义的现象非常普遍。如何自动获悉某个词的多种含义;或者已知某个词有多种含义,如何根据上下文确认其含义,是词义消歧研究的内容。
在英语中,bank这个词可能表示银行,也可能表示河岸;而在汉语中,这样的例子就更可怕了,比如:

于是,基于这样的现状,词义消歧的任务就是给定输入,根据词语的上下文对词语的意思进行判断,例如:
给定输入:他善与外界打交道
我们期望的输出是可以确定这句话中的“打”和上图中的义项(5)相同。
语义消歧的方法大概分为四类:
1.基于背景知识的语义消歧
2.监督的语义消歧方法
3.半监督的学习方法
4.无监督的学习方法
其中,第一种方法是基于规则的方法(也称为词典方法),后三种都是机器学习方法。
在这里我们主要介绍前两种方法。
基于背景知识的语义消歧
基于背景知识的语义消歧方法基本思想是这样的:通过词典中词条本身的定义作为判断其语义的条件。
举个例子,cone这个词在词典中有两个定义:一个是指“松树的球果”,另一个是指“用于盛放其他东西的锥形物,比如,盛放冰激凌的锥形薄饼”。
如果在文本中,“树(tree)”或者“冰(ice)”与cone出现在相同的上下文中,那么,cone的语义就可以确定了,tree对应cone的语义1,ice对应cone的语义2。
可以看出,这种方法完全是基于规则的。
监督的语义消歧方法
监督学习的方法就是,数据的类别在学习之前已经知道。
在语义消歧的问题上,每个词所有可能的义项都是已知的。有监督的语义消歧方法是通过一个已标注的语料库学习得到一个分类模型。
常用的方法有:
1.基于贝叶斯分类器的词义消歧方法
2.基于最大熵的词义消歧方法
3.基于互信息的消歧方法
在这里我们只介绍第二种方法,对其他两种方法感兴趣的朋友们可以自行查阅相关资料。
基于最大熵的词义消歧方法基本思路是这样的:每个词表达不同含意时其上下文(语境)往往不同,即不同的词义对应不同的上下文。因此,可以将词的上下文作为特征信息利用最大熵模型对词的语义进行分类。
这个思路是不是很熟悉?因为在NLP领域,几乎所有的机器学习方法利用的都是上下文特征这一套东西。
大家一定还记得最大熵模型是个什么东西(不了解的朋友们可以参考博客:自然语言处理NLP(5)——序列标注b:条件随机场(CRF)、RNN+CRF),在最大熵模型中,最最重要的部分就是如何选取特征,特征的质量直接影响着模型的效果。在传统机器学习领域(非深度学习),特征选取往往是人们手工进行的。
在词义消歧中,最大熵模型的建模与训练如下图所示:
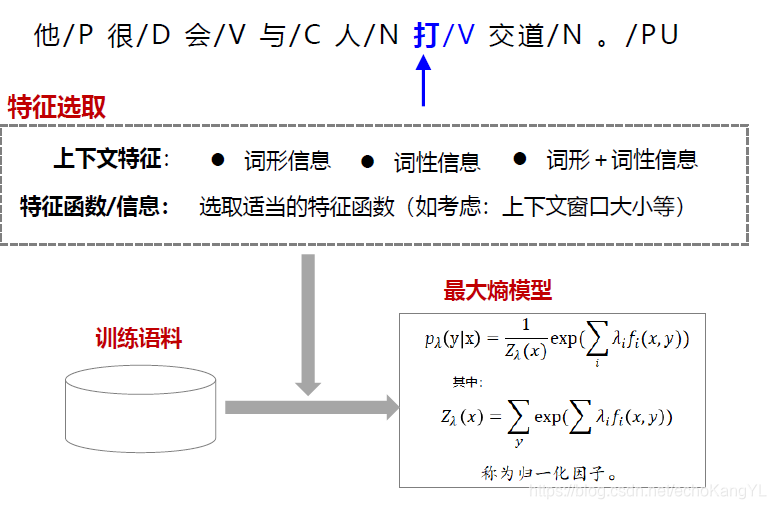
由于最大熵模型在之前的博客中曾详细讨论过,在这里就不再赘述,有疑问的朋友可以私信,我们一同讨论。
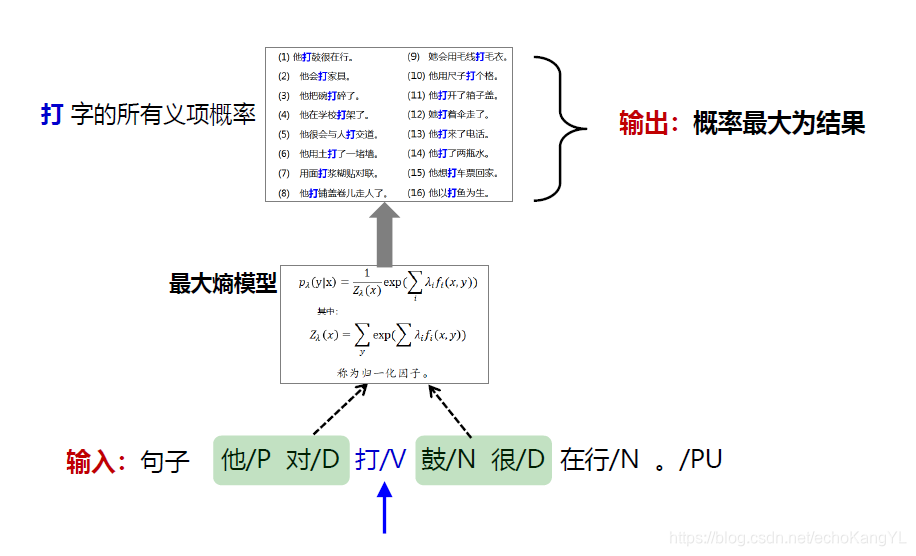
训练过后,我们将新的句子输入模型中,模型会给出一个概率分布(其实最大熵模型的输出就是一个概率分布),我们选取其中概率最大的结果作为模型输出,整个过程如下图所示:
词语相似度
词语相似度的意思大家很容易理解,在这里我们用一种复杂但是稍微正式的方式说明词语相似度的含义,就是:两个词语在不同的上下文中可以互相替换使用而不改变文本的句法语义结构的程度。
在不同的上下文中可以互相替换且不改变文本句法语义结构的可能性越大,二者的相似度就越高,否则相似度就越低。
相似度以一个数值表示,一般取值范围在[0,1]之间。一个词语与其本身的语义相似度为1;如果两个词语在任何上下文中都不可替换,那么其相似度为0。
值得注意的是,相似度涉及到词语的词法、句法、语义甚至语用等方面的特点。其中,对词语相似度影响最大的应该是词的语义。
词语距离是度量两个词语关系的另一个重要指标,用一个[0,∞)之间的实数表示。
大家可以想象,词语距离和词语相似度之间一定是存在某种关系的:
1.两个词语距离为0时,其相似度为1 。即,一个词语与其本身的距离为0;
2. 两个词语距离为无穷大时,其相似度为0;
3.两个词语的距离越大,其相似度越小(单调下降)。
如果将词语相似度记为 s i m ( w 1 , w 2 ) sim(w_1,w_2) sim(w1,w2),而将词语距离记为 d i s ( w 1 , w 2 ) dis(w_1,w_2) dis(w1,w2),我们有:
s i m ( w 1 , w 2 ) = α d i s ( w 1 , w 2 ) + α sim(w_1,w_2)=\frac{\alpha}{dis(w_1,w_2)+\alpha} sim(w1,w2)=dis(w1,w2)+αα
其中, α \alpha α是一个可调节的参数,表示相似度为0.5时的词语距离值(上式简单移项带入值既可)。
到这里,大家可能有个问题:为什么有了词语相似度了,还要多此一举定义词语距离呢?
这是为了当直接计算词语的相似度比较困难时,可以先计算词语距离,再转换成词语的相似度。
然后我们再来介绍一个概念:词语相关性。
词语相关性反映的是两个词语互相关联的程度,可以用这两个词语在同一个语境中共现的可能性来衡量。
一开始看见整个概念的时候可能会有种“这和词语相似度不是差不多么”这样的感觉,其实不然。
举个例子,“医生”和“疾病”这两个词之间的相似度很低,但是相关性很高(因为这两个词经常在同一语境中出现)。
用一句高深的话来讲,词语相似性反映的是词语之间的聚合特点,而词语相关性反映的是词语之间的组合特点。
词语相关性也以一个数值表示,一般取范围在[0,1]之间的实数。
虽然相关性与相似性并不相同,但实际上,词语相关性和词语相似性有着密切的联系。如果两个词语非常相似,那么这两个词语与其他词语的相关性也会非常接近。反之,如果两个词语与其他词语的相关性特点很接近,那么这两个词一般相似程度也很高。
利用词典方法(规则法)计算词语语义相似度的方法很多,这里不再赘述,有兴趣的朋友们可以自行查阅相关资料。
提到语义相似度这个概念,相信大家很容易想到词向量这个概念(对词向量不了解的朋友们可以参考博客:自然语言处理NLP(3)——神经网络语言模型、词向量)。根据词向量的性质,语义相似的词其词向量空间距离更相近,训练出的词向量具有词义相近的词在向量空间聚簇的语言学特性。
词向量的相关工作就太多了,部分模型还对词向量进行k-means聚类,聚类后再次训练,得到多原型神经网络语言模型,考虑一词多义的情况。有兴趣的朋友们可以自行查阅相关资料或者私信讨论,在这里就不再进行介绍。
【二】句子级语义分析
句子级语义分析主要分为两个部分:浅层语义分析和深层语义分析,在这里我们主要介绍浅层语义分析。
提到浅层语义分析,就离不开语义角色标注(Semantic Role Labeling, SRL)这个概念。语义角色标注主要围绕着句子中的谓词来分析各成分与其之间的结构关系,并用语义角色来描述这些结构关系。
那么问题来了,为什么要围绕谓词来分析句子呢?
我们暂且把这个问题放下,先来介绍格文法,在这里我们会找到这个问题的答案。
格文法
格文法是从语义的角度出发,即从句子的深层结构来研究句子的结构,着重探讨句法结构与语义之间关系的文法理论。
在分析句子的过程中,我们有一种很常见的方法是找出句子中的主语、宾语等语法关系。大家可以联想一下初高中的英语阅读题,特别是完形填空,就是类似的套路。然而,格文法认为,这些都只是句子表层结构上的概念。
在语言的底层,所需要的不是这些表层的语法关系,而是用施事、受事、工具、受益等概念所表示的句法语义关系,这些句法语义关系经过各种变换之后才在表层结构中成为主语或宾语。
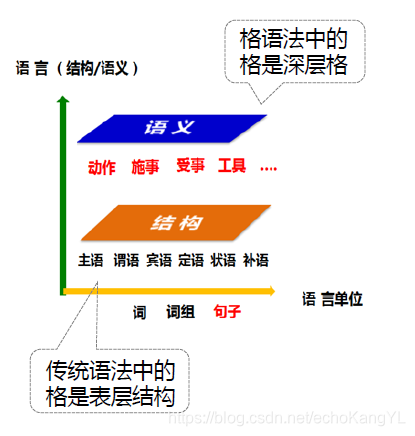
在传统语法中,“格”是指某些曲折语中特有的用于表示词语间语法关系的名词和代词的形态变化,例如主格、宾格等。
然而在格文法中,格是深层格,是指句子中的体词(名词、代词等)和谓词(动词、形容词等)之间的及物性关系。如,动作和施事者的关系、动作和受事者的关系等,这些关系是语义的,是一切语言中普遍存在的。
深层格由底层结构中名词与动词之间的句法语义关系来确定,不管表层句法结构如何变化,底层格语法不变;底层的“格”与任何具体语言中的表层结构上的语法概念,如主语,宾语等,没有对应关系。
这个概念有些难懂,我们举个例子:

其表层结构与深层语义是有区别的,具体如下:
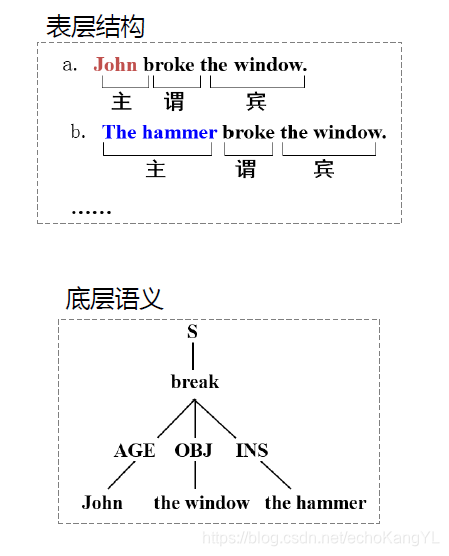
由这个例子我们可以看出,在格文法中,无论具体的句子的主语、宾语等等怎么改变,其深层语义是完全相同的。
在格文法中,不同“格”(上图中所提到的施事格、受事格等等)的概念、格文法的组成等内容十分丰富,在这里不一一进行介绍,有兴趣的朋友们可以自行查阅相关资料或者私信进行讨论~
利用格文法分析的结果可用格框架表示。一个格框架由一个主要概念和一组辅助概念组成,这些辅助概念以一种适当定义的方式与主要概念相联系。在实际应用中,主要概念一般是动词,辅助概念为施事格、方位格、工具格等语义深层格。
这样描述可能有些抽象,具体而言,把格框架中的格映射到输入句子中的短语上,识别一句话所表达的含义,即要弄清楚“干了什么”、“谁干的”、“行为结果是什么”以及发生行为的时间、地点和所用工具等。
下面我们举个利用格文法进行语义分析的例子:

大家不要过于在意上图中的具体格式,其表示的含义很容易理解。
语义角色标注(SRL)
基于格文法,提出了一种语义分析的方法——语义角色标注。
正如句法分析需要基于词法分析的结果进行一样,语义角色标注需要依赖句法分析的结果进行。
因此,语义角色标注方法分为如下三种:
1.基于完全句法分析的语义角色标注
2.基于局部句法分析的语义角色标注
3.基于依存句法分析的语义角色标注
刚好是句法分析的三种方法,对句法分析不熟悉的朋友们可以参考博客:
自然语言处理NLP(7)——句法分析a:Chomsky(乔姆斯基)形式文法
自然语言处理NLP(8)——句法分析b:完全句法分析
自然语言处理NLP(9)——句法分析c:局部句法分析、依存关系分析
但是无论那种方法,语义角色标注的过程都如下图所示:

其中,论元识别既可以单独称为一个步骤,也可以与论元剪除或者论元标注合并。
上图中,大家想一想就会发现,语义角色标注的核心就是对论元进行语义标签的分类(第二步分类),语义角色标注的不同方法,其实就是针对这个问题设计不同的更加高效的分类器。
句法分析是语义角色标注的基础,在统计方法中后续步骤常常会构造的一些人工特征,这些特征往往也来自句法分析;在神经网络方法中可以用神经网络自动提取特征来实现分类(标注)任务——神经网络在NLP领域,一大重要的作用就是代替了人工构建特征。
到了这里我们发现,其实语义角色标注任务和我们之前所介绍的分类标注任务可以用相同的套路来解决(例如最大熵模型、隐马尔科夫模型、条件随机场等等)。
在这里多说一句,其实对NLP介绍到这里,给定具体的任务并将其进行形式化之后,很多问题都可以利用之前提到过的方法和套路来解决。
下面,我们对上文提到的SRL方法进行介绍,主要介绍基于完全句法分析和依存句法分析的语义角色标注方法,针对依存方法,我们还将进一步介绍当下比较热门的神经网络方法。
基于完全句法分析的统计SRL方法
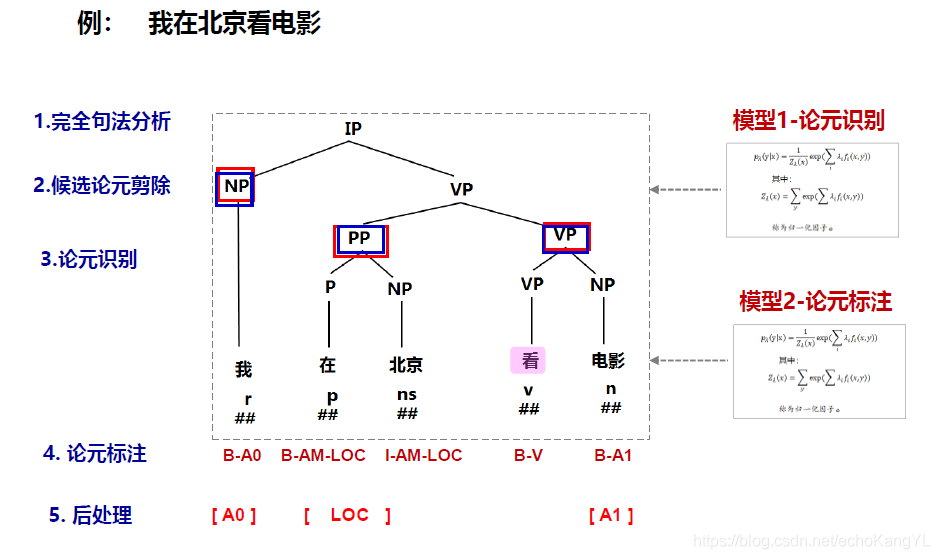
举个例子,我们原始的输入句子是:“警察已到现场,正在详细调查事故原因”
那么我们的任务如下:
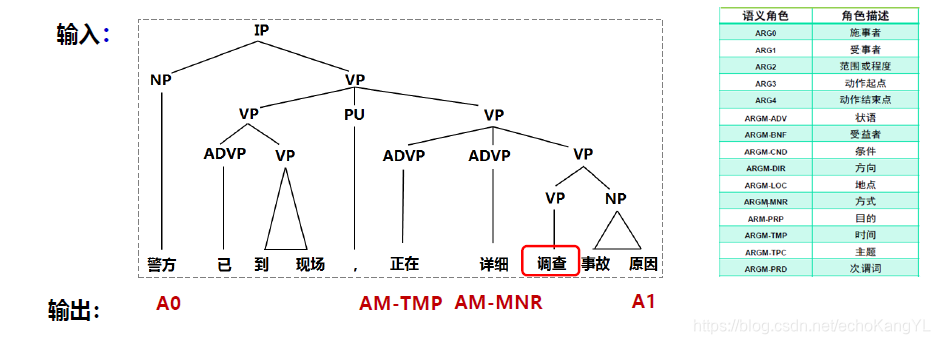
值得注意的是,我们SRL任务的输入是已经完成句法分析的句子(通常为句法树)。
图中右侧的表格是标注的label。
我们再来回忆一下SRL的过程,这个过程很重要(下图中句法分析已经结束),我们接下来会一步步进行介绍:

候选论元剪除
对于完全句法分析而言,论元剪除规则分为如下两步(基于不同的句法分析方法,论元剪除规则有所不同):
1.将谓词作为当前节点,依次考察它的兄弟节点:如果一个兄弟节点和当前节点在句法结构上不是并列的(coordinated)关系,则将它作为候选项。如果该兄弟节点的句法标签是PP,在将它的所有子节点也都作为候选项。
2.将当前节点的父节点设为当前节点,重复第1步的操作,直至当前节点是句法树的根节点。
这样的描述有些晦涩,我们还是以上面的句子为例:
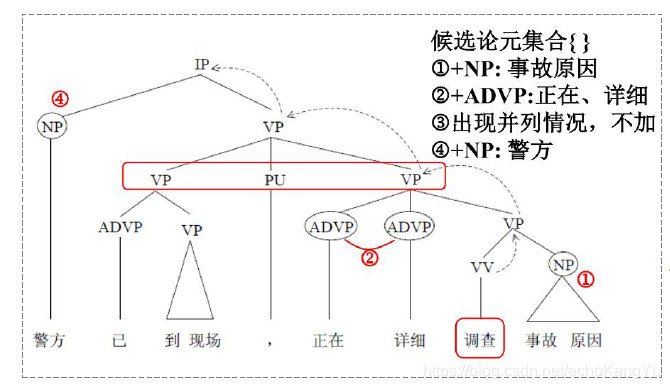
于是,我们就有了谓词“调查”的候选论元集合:{ 警方、正在、详细、事故原因 }
论元识别
正如我们上面所提到的,该步骤可以与论元剪除合并,也可以与接下来的论元标注合并,当然,也可以单独作为一步。
论元识别顾名思义,就是识别上一步得到的候选论元集合中的论元是不是真的是论元。
所以,很明显,这是个二分类序列标注问题,方法在之前章节中也有过很多介绍(例如最大熵模型、CRF、HMM等等),这里就不再赘述。
假设在这一步中,我们认为上面的集合中所有的元素都是论元(即,模型没有判断出负类)。
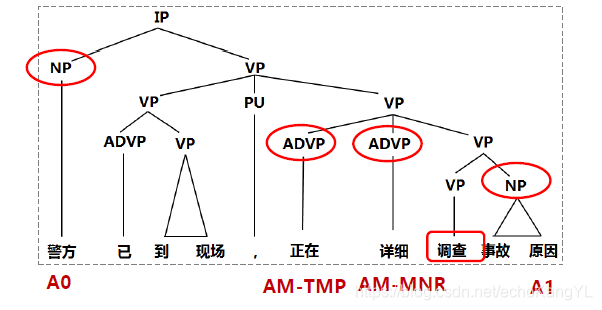
论元标注
顾名思义,该步的任务就是将上面一步中所识别出(为正类)的论元进行标注,标注的label是之前所提到的绿色表格中的内容。
很明显,这是个多分类序列标注问题,方法在之前章节中有过很多介绍(方法依然是最大熵、CRF、HMM等)。
在这里,我们回忆一下,最重要的部分是什么?
特征构建。
在上一步中也是相同的,特征构建是序列标注任务中最重要的一环。
值得注意的是这一步中的特征构建可以与上一步不同,而且往往不同(因为这是两个不同的分类器)。
于是,我们得到了如下的结果:
后处理
后处理一步就是将标注之后的论元进行处理或者加上一些更加丰富(简单易懂)的信息,这部分不是我们所讨论的重点,因此只稍微提两句。
后处理部分的内容主要包括:
1.每个词只能标为一种标签(包括NULL)
2.一种角色(NULL除外)通常在句子中只出现一次,因此在角色标注序列中,应无重复角色出现。
经过了上述步骤,我们就可以通过训练得到SRL模型了,训练过程与其他任务类似,在这里就不进行介绍了。值得注意的是,我们得到的是两个模型:论元识别模型、论元标注模型。前者是二分类模型,后者是多分类模型。
然后,我们来了一个新句子,其标注过程如下:
基于依存句法分析的统计SRL方法
同样以“警察已到现场,正在详细调查事故原因”为例。由于句法分析方法发生了改变,所以与上述方法不同的是SRL的输入:
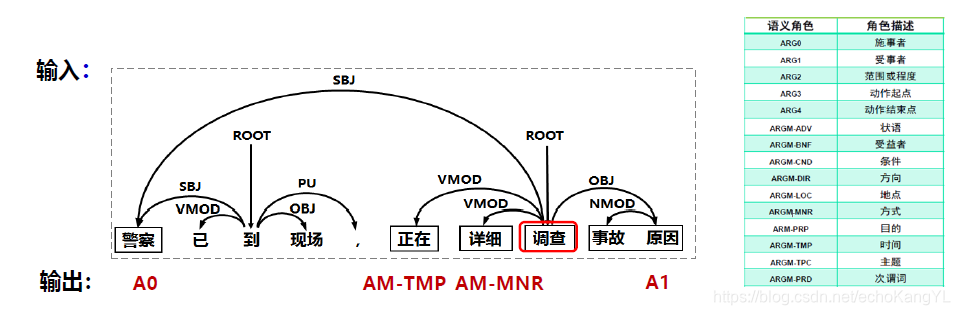
可以看出,输入由完全句法树改变为了依存分析树。
与完全句法分析SRL相同的是右边的表格(论元标注label)。
大家想一下整个SRL过程就能够发现,除了第一步候选论元剪除之外,其他步骤都与上述方法中的对应步骤相同,所以我们在这部分中仅讨论这一步骤。
候选论元剪除
该步骤同样分为两部:
1.将谓词作为当前节点,将它所有的孩子都作为候选项。
2.将当前节点设为它的父节点,重复第1步的操作,直到当前节点是
依存句法树的根节点。
过程如下:
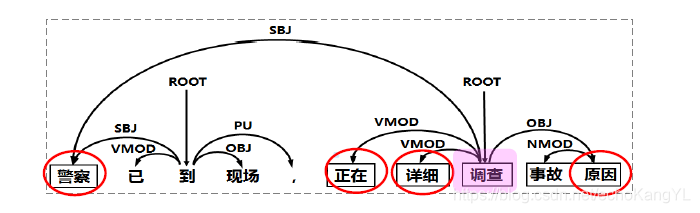
谓词“调查”的所有孩子{ 正在,详细,原因,警察 }都加入到候选项中,这些孩子节点恰好是该谓词的所有论元。
基于依存句法分析的神经网络SRL方法
介绍了以上两种SRL方法之后,我们需要着重注意的有两点:
1.上述两种方法都是通过概率统计法进行SRL的方法(在我们之前章节中多次提到的那张图中既不是规则法,也不是神经网络法,而属于概率统计法)。
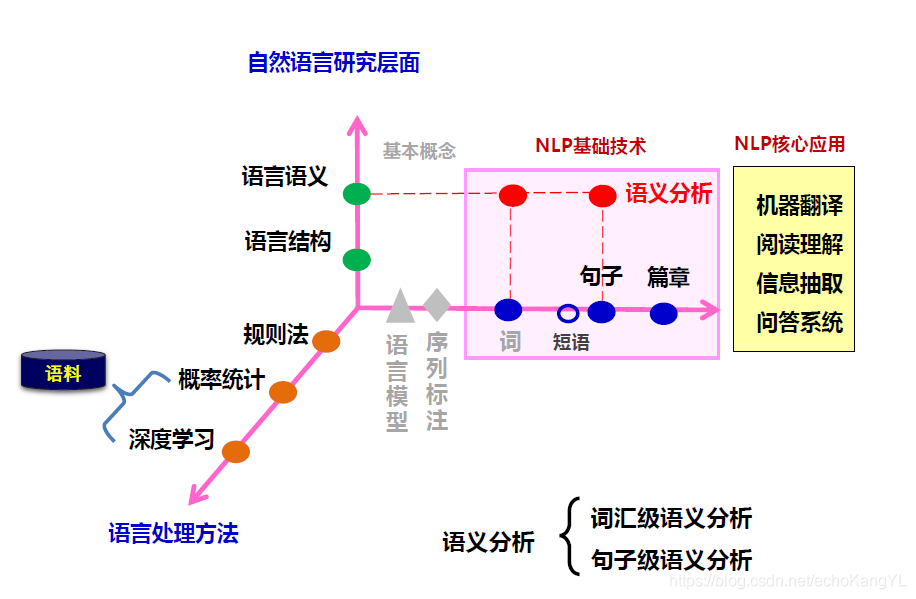
(之前的两种方法属于左下角的概率统计方法)
2.我们知道,特征构建是标注问题的重中之重,然而在传统概率统计方法中,只能由人工构建特征,这就为模型的性能打上了一个大大的问号。因此,为了解决这个问题,我们在这一部分中介绍基于依存关系分析的神经网络SRL方法。
我们之前提到,神经网络法的主要目的是为了利用神经网络自动构建特征,那么我们很自然就可以想到,该种方法与概率统计法的主要区别就在于模型,神经网络模型架构如下:
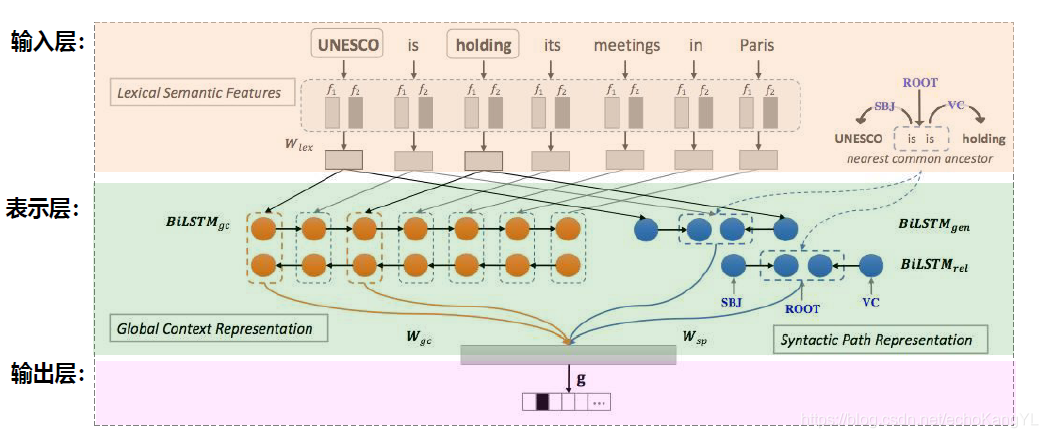
上图中,我们的输入是原始句子(图片正上方)以及依存关系树(图片右下角),经过了神经网络之后的输出为某词的标注结果。
其中,输入的依存关系树部分主要是节点信息和边信息。
值得注意的是,神经网络的具体架构可以自行设计,图片中利用的是双向LSTM架构。
模型训练过程就不再赘述,有兴趣的朋友可以自行查阅相关资料或者私聊讨论~
评价指标
如何评价一个语义角色标注模型的好坏呢?
一般情况下,我们通常使用常见的P、R、F1值进行评测,对该评测指标不了解的朋友们可以参考博客:自然语言处理NLP(6)——词法分析
在这一部分中,我们介绍了语义分析的基本知识,包括格文法以及语义角色标注的相关内容。
在下一部分中,我们将会介绍篇章分析相关的内容。
如果本文中某些表述或理解有误,欢迎各位大神批评指正。
谢谢!