2019独角兽企业重金招聘Python工程师标准>>> 
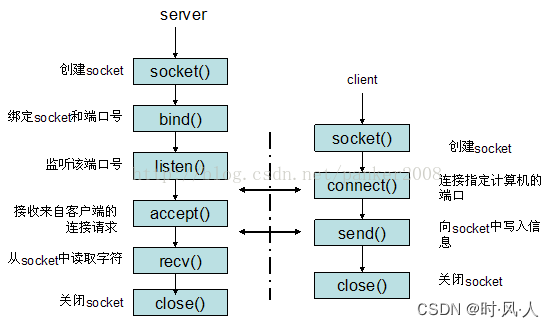
如何实现集群的。
测试代码编写
我们首先写一个demo,该demo在没有terracotta的环境下执行一次,看看结果
我们首先先写一个简单的多线程代码(我们这个例子制定共享TerracottaDemo类的demo对象,它包含的count和yale对象也就随之被整个集群共享了):
package yale.terracotta.demo; public class TerracottaDemo implements Runnable { private static TerracottaDemo demo = new TerracottaDemo(); private Object yale = new Object(); private int count = 0; @Override public void run() { while (true) { synchronized (yale) { count++; System.out.println(Thread.currentThread().getName() + " count:" + count); } try { Thread.sleep((int) (1000 + Math.random())); } catch (Exception e) { e.printStackTrace(); } } } public static void main(String[] args) { new Thread(demo).start(); new Thread(demo).start(); }
}
该class文件存放在:
执行,开启不同的进程进行执行,看看结果:
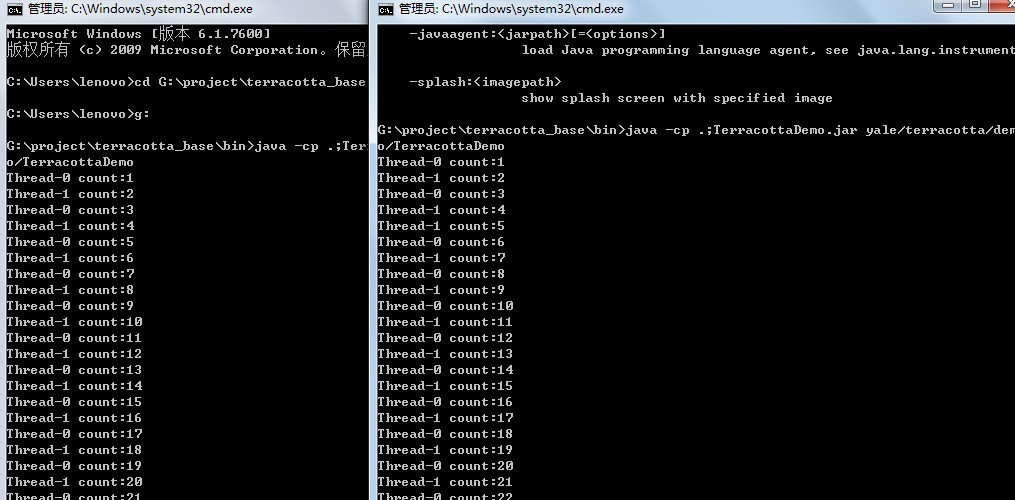
上述执行环境是在win下,通过以上的执行情况我们可以看出,正常情况下各个进程调用各自JVM中的对象,并没有任何的共享
下载、安装
下载Terracotta,下载前需要注册帐号才能进行下载:
http://terracotta.org/:
从上面的信息中,我们可以看到,注册成功后进行邮件验证,验证成功后点击网站”open source”后,可以对其产品Ehcache、Quartz、BigMemory下载,我们下载terracotta (目前最高版本: terracotta-3.6.2.tar.gz、terracotta-ee-3.6.2-installer.jar)后:
安装方法一:解压相应的tar文件到相应的目录即可(Linux版本)即可
安装方法二:通过java –jar terracotta-ee-3.6.2-installer.jar
其实解压后的文件夹中,包含了相应的ehcache、quartz的相关产品
Terracotta Server配置方式
1、 单机,无持久化:服务器把集群要管理的数据保存在内存中,当数据量大于服务器可用内存的时候,会发生内存溢出错误。这种模式一般只在开发中使用;
2、 单机,持久化:服务器把集群要管理的数据保存在硬盘中,利用服务器上的内存作为缓存,以提高常用数据的访问速度。当数据量大于服务器可用内存的时候,服务器会把不常用数据从内存中移除,这样就不会发生内存溢出问题。当服务器宕机,然后被从新启动以后,硬盘中的数据被从新激活,这样集群中共享的数据不会丢失。这种配置提供了一定的灾难恢复(Fail over)的能力,但是还是无法做到高可用性(HA);
3、 双机或者多机镜像(mirroring):一般由两台或者多台物理服务器互为镜像。其中一台作为主服务器支持集群运行。其它备用服务器只是对数据做镜像,并且监视主服务器的状态。当主服务器发生故障宕机的时候,其中一台备用服务器自动升级为主服务器,接管整个集群的支撑工作。这样一来整个集群还继续正常运行,不会受任何影响。这种配置可以实现高可用性。一般对于这种配置模式,我们还把服务器数据配置为持久化模式,但是如果内存数量不是问题,用户也可以选择非持久化;
4、 服务器阵列分片模式(Server Array Striping):这是Terracotta FX系列产品独有的高端企业级特性,它主要用于提高集群性能。当集群中数据量和数据访问频率太高的时候,可以配置多台服务器,分别负责一部分集群数据的服务。比如集群共享数据达到1G个对象,如果用5台服务器做分片,每一台服务器可以负责2千万个对象。这样就实现了Terracotta服务器的负载均衡。这种数据分片的策略,也就是说哪个数据对象保存在哪个服务器上,对开发人员和实施维护人员是完全透明的。当服务器吞吐量不能满足要求的时候,用户可以考虑修改代码,对共享数据和应用系统中的数据访问算法进行优化;也可以简单地增加阵列分片服务器数量。后者往往是性价比比较高的方式。用户还可以考虑让两台服务器互为镜像,让多个镜像再组合成阵列分片。这样每个镜像做到高可用性,多个镜像在一起,实现集群性能的提高;
配置Terracotta集群
环境的准备工作(这次我们在linux下进行,3台服务器上进行,主节点服务器(192.168.2.11),子节点(192.168.2.11、192.168.2.21、192.168.2.221),现在我们把这个代码打jar包后放在下面配置的集群上,让多个JVM共同访问一个计数器)
1、 创建tc-config.xml文件,存放到terracotta根目录下(可以通过config-samples文件夹下的tc-config-express-reference.xml文件进行修改),该文件是描述client节点在TC Server中行为的唯一信息,也是我们的程序作为Terracotta Client节点添加时主要的内容(为了能够让任何节点都在不修改的情况下都能成为主节点,我在配置文件中配置了一些冗余的信息,以及在每个节点都建立了相同的文件夹):
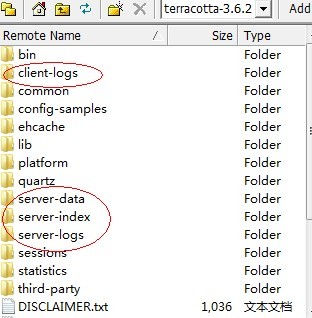
每个节点都有红框中的文件夹
配置文件(一个完整的tx-config.xml文件,附带有文件属性说明,每个节点内容都一样,创建好后,可以直接拷贝到其他节点):
<?xml version="1.0" encoding="UTF-8" ?>
<tc:tc-config xmlns:tc="http://www.terracotta.org/config" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-6.xsd"> <!-- # 配置TERRACOTTA CLUSTER的优化属性,可以放在这里,也可以放在TC.PROPERTIES文件中,TERRACOTTA依以下次序读取属性配置 # 1、安装JAR # 2、本XML文件的tc-config节 # 3、tc.properties文件 # 4、系统属性定义 --> <tc-properties> <!-- <property name="l1.cachemanager.percentageToEvict" value="10"/> <property name="l1.cachemanager.sleepInterval" value="3000"/> <property name="l1.cachemanager.criticalThreshold" value="90"/> <property name="l1.cachemanager.threshold" value="70"/> <property name="l1.cachemanager.monitorOldGenOnly" value="true"/> --> <property name="l2.nha.dirtydb.autoDelete" value="true" /> <property name="l1.cachemanager.enabled" value="true" /> <property name="logging.maxLogFileSize" value="1024" /> </tc-properties> <!-- SYSTEM这一节记录一些影响Terracotta全局的数据 --> <system> <!--default:development can setup "production" --> <configuration-model>development</configuration-model> </system> <!-- Servers节点内,用来指定Servers Array里所有服务器,TC Server通过子节点<dso-port>来配置服务监听端口为9510, 使TC client与DSO模式协同工作 --> <servers> <server host="192.168.2.11" name="oraclerac1" bind="192.168.2.11"> <!--当配置以持久方式(persistent)保存数据时候的数据存放地址--> <data>/usr/java/terracotta/server-data</data> <!--日志存放地址--> <logs>/usr/java/terracotta/server-logs</logs> <index>/usr/java/terracotta/server-index</index> <!--供客户端调用的端口--> <dso-port>9510</dso-port> <!--供jmx调用的端口--> <jmx-port>9520</jmx-port> <!--server间的监听端口--> <l2-group-port>9530</l2-group-port> <!-- 一个空的<authentication/>代表使用JAVA默认的JMX认证方式,需要修改:$JAVA_HOME/jre/lib/management/jmxremote.password 增加一行 用户 密码 # $JAVA_HOME/jre/lib/management/jmxremote.access, 增加一行 用户 readwrite # 同时要执行 # 1、chmod 500 jmxremote.password 2、chown <启动TC-SERVER的用户> jmxremote.password --> <authentication /> <!-- # 定义terracotta http server 访问用户管理文件名,文件格式为 # username: password [,rolename ...] # rolename目前只有statistics,允许收集统计数据 <http-authentication> <user-realm-file>/usr/java/terracotta/realm.properties</user-realm-file> </http-authentication> --> <dso> <!-- 定义在server 启动后多少秒内,可以连接? --> <client-reconnect-window>120</client-reconnect-window> <!-- 定义DSO对象的持久性保存方式 # temporary-swap-only-方式只临时使用下磁盘,比permanent-store方式要快些 # permanent-store-方式只有变化立即写入磁盘,更有利于SERVER异常后的数据恢复。 # 默认为temporary-swap-only方式 --> <persistence> <mode>permanent-store</mode> </persistence> <garbage-collection> <!-- 配置分布式JVM垃圾的回收方式,true代表自动回收,false模式下只有在'run-dgc'脚本被调用的情况才回收 --> <enabled>true</enabled> <!-- 配置为TRUE在分布式垃圾回收的时候是否写额外信息到日志中,有利于系统优化 --> <verbose>false</verbose> <!-- 分布式垃圾回收时间间隔,单位秒 --> <interval>3600</interval> </garbage-collection> </dso> </server> <server host="192.168.2.21" name="oraclerac2"> <data>/usr/java/terracotta/server-data</data> <logs>/usr/java/terracotta/server-logs</logs> <index>/usr/java/terracotta/server-index</index> <dso-port>9510</dso-port> <jmx-port>9520</jmx-port> <l2-group-port>9530</l2-group-port> <authentication /> <dso> <client-reconnect-window>120</client-reconnect-window> <persistence> <mode>permanent-store</mode> </persistence> <garbage-collection> <enabled>true</enabled> <verbose>false</verbose> <interval>3600</interval> </garbage-collection> </dso> </server> <server host="192.168.2.221" name="dataguard"> <data>/usr/java/terracotta/server-data</data> <logs>/usr/java/terracotta/server-logs</logs> <index>/usr/java/terracotta/server-index</index> <dso-port>9510</dso-port> <jmx-port>9520</jmx-port> <l2-group-port>9530</l2-group-port> <authentication /> <dso> <client-reconnect-window>120</client-reconnect-window> <persistence> <mode>permanent-store</mode> </persistence> <garbage-collection> <enabled>true</enabled> <verbose>false</verbose> <interval>3600</interval> </garbage-collection> </dso> </server> <ha> <!--下面的mode我们选用了networked-active-passive方式, 表示DSO数据是存放在不同的TC Serer上的, 数据的同步通过 网络数据来交换完成,该模式下的active和passive实际上是通过 状态检查和投票产生的, 而另外一种方式disk-based-active-passive表示 TC serers的DSO数据是存放在同一个存储设备上的, 不同的TC serers 通过网络文件系统等方式在配置文件的<data>属性中被引用,该模式下的active和 passive是通过disk lock来完成的 --> <mode>networked-active-passive</mode> <networked-active-passive> <!--心跳检查间隔,单位秒--> <election-time>5</election-time> </networked-active-passive> </ha> <update-check> <!--运行时候是否进行Terracotta版本检查,会连接Terracotta.org--> <enabled>true</enabled> <!--检查间隔天数,默认为7--> <period-days>10</period-days> </update-check> </servers> <!--设置影响所有连接到系统的client--> <clients> <!--告诉dso把TC client的日志放在哪里,可以使用参数 %h代表hostname, %i代表IP地址, 默认为启动client的目录的相对目录,也可以使用绝对路径--> <logs>/usr/java/terracotta/client-logs/pojo/%i</logs> </clients> <application> <dso> <!-- 定义那些class应该有terracotta来构建,即应该在jvm进行cluster和共享,可以通过定义包含(include)及 排除 (exclude)两种方式来配置 --> <instrumented-classes> <!--添加自定义的对象/类被共享,但是这个类中有的字段是被描述成"transient"的,还是应该 保持"transient"字段应有的特性, 通过设置<honor-transient>为'true',已经声明成"transient"的 字段他们的状态和值不会在不同应用的实例间可用,只有本地的 应用实例可以创建,读,写这些字段, 如果应用程序有对其依赖的包,此处还需进行添加 --> <include> <class-expression> yale.terracotta.demo.TerracottaDemo </class-expression> <!--如果设置为false,那么所有标示为临时对象(transient)的类都要求使用terracotta来构建--> <honor-transient>true</honor-transient> <!-- 定义在装载类时候要执行的动作: 如果是java类方法,使用method,注意method不能有参数,调用脚本, 使用execute 如果配置了onload,那么method和execute 2者必须配置一种 <on-load><method></method></on-load> --> </include> </instrumented-classes> <!-- 列出临时属性field,即不需要在cluster、shared的属性列表 <transient-fields> <field-name>xx.yy.zz</field-name> <field-name>xx.yy.zz</field-name> </transient-fields> --> <!-- 告知DSO哪些应用在你的web容器中使用DSO,对于session内共享对象是否使用auto-lock模式自动进行管理, 可以通过设置session-locking值来决定,如果设置为false,就不进行auto-lock自动模式管理,而是需要应用进行控制, 但无论哪种模式,通过HttpSession对象进行操作,比如setAttribute(), setMaxInactiveInterval()仍然自动会锁 <web-applications> <web-application>yale_app</web-application> <web-application session-locking="false">yale_app1</web-application> </web-applications> --> <roots> <root> <!--变为全局变量--> <field-name> yale.terracotta.demo.TerracottaDemo.demo </field-name> <!-- <root-name></root-name> <distributed-methods> <method-expression></method-expression> </distributed-methods> 使这些字段“transient”,这样这些值就只能在本地上是可用的 <transient-fields> <field-name></field-name> </transient-fields> --> </root> </roots> <!-- 分布式方法调用,当某个method在一个JVM被调用后,整个cluster下jvm都调用此method,常用于事件监听 <distributed-methods> 设置为false,那么只有在method归属对象在jvm已经创建,method才被调用,默认为true <method-expression run-on-all-nodes="false">xx.yy.zz</method-expression> </distributed-methods> --> <!-- 可以通过将应用放在同一应用组中来共享class,但必须将应用放在不同Terracotta节点中, 比如放在不同web server实例中, 目前Terracotta不支持在同一节点中共享不同应用的class 同时可以通过named-classloader指定class 装载类 <app-groups> <app-group name="petstore-group"> <web-application>yale_app</web-application> <web-application>yale_app1</web-application> <named-classloader>Standard.system</named-classloader> </app-group> </app-groups> --> <!-- 默认为TURE,启用 mutations方式来影射共享对象 <dso-reflection-enabled>true</dso-reflection-enabled> --> <!-- 本节用于设置自定义的锁,锁可以分为自动锁(autolock)和命名锁(named-lock) # 锁的级别可以分为: # 1、写锁write # 2、同步写锁synchronous-write # 3、读锁read # 4、并发锁 concurrent # 其中并发锁一定要小心使用, 并发允许同时写一个对象。 --> <locks> <!-- 对一个已经声明为共享的对象进行操作,告诉DSO,当调用这些对象的时候, 假设给它加上 了一把持久的锁。 autolock锁可以将你期望的方法,通过java的同步机制(block和method)来进行管理, 对于没有定义为synchronized的对象,需要设置auto-synchronized=true,比如<autolock auto-synchronized=true> name-lock 完全依赖于java的synchronization机制,可以对锁进行命名以方便管理 例子中给TerracottaDemo.run()方法定义了自动锁(autolock)。 他告诉Teraccotta当这个方法对共享的数据加锁的时候(TerracottaDemo.yale对象是共享的),使得这个锁在整个集群范围内生效。 这样一来集群中任何一个线程锁住这个对象的时候,其它任何线程都要等这个锁解除 后才能访问被保护的数据(TerracottaDemo.count)。 这样计数器的访问也就在整个集群中得到了保护 --> <autolock> <method-expression> void yale.terracotta.demo.TerracottaDemo.run() </method-expression> <lock-level>write</lock-level> </autolock> </locks> </dso> </application>
</tc:tc-config>
2、 拷贝tc-config.xml(上面已经存在该文件了)文件到各个linux服务器上(存放在terracotta根目录下)
3、 把上面的线程的代码例子打成jar包,拷贝到各个linux服务器上(存放在terracotta根目录下)
主节点操作以下命令(192.168.2.11):
进入到$TC_HOME/bin目录,执行start-tc-server.sh,未执行参数-f<tc-config.xml>启动时,启动程序会使用tc.jar包里自带的默认配置文件’com/tc/config/schema/setup/default-config.xml’:
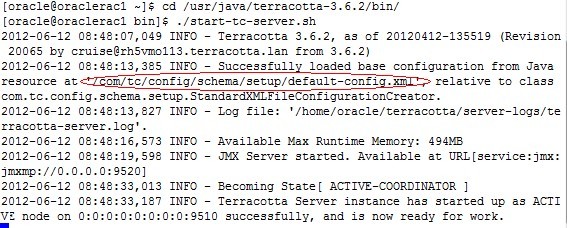
我们不采用上面的启动方式,我们启动指定的配置文件:
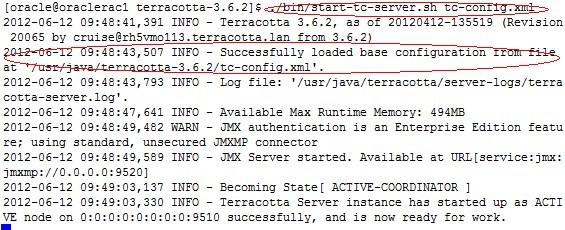
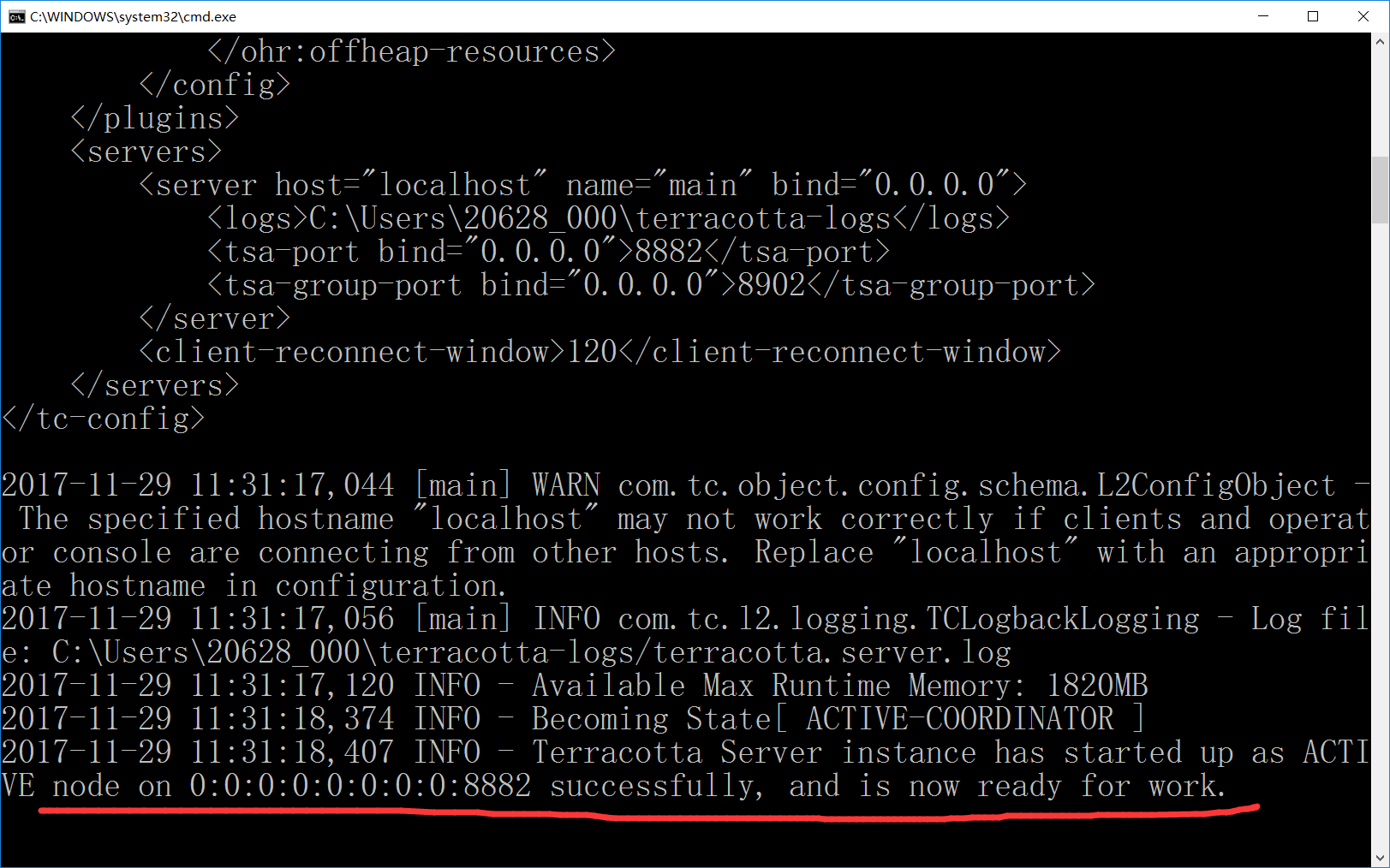
我们可以看到terracotta server已经启动成功
子节点操作以下命令(192.168.2.11、192.168.2.2192.168.2.221):
我们依次启动3个子节点服务器后,可以看到控制台打印的结果(控制台显示客户端已经成功连接到服务器192.168.2.11:9510,我们可以看到计数器仍然在累加,在全局范围内共享):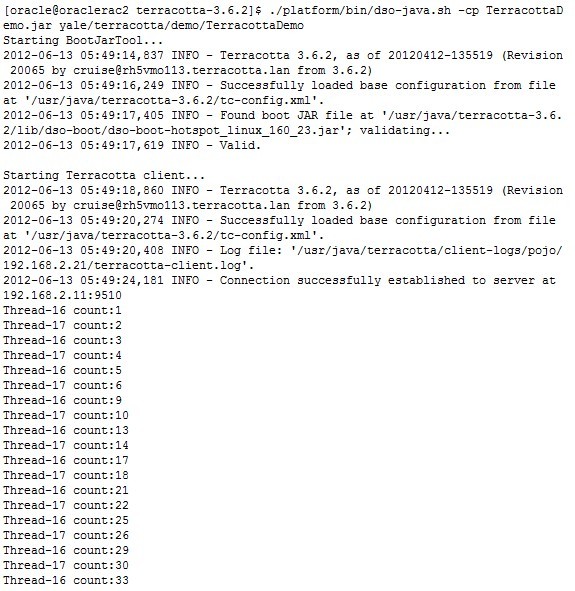
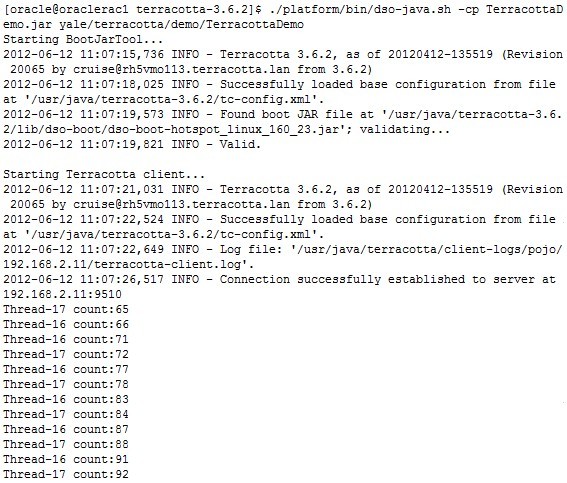
可见计数器已经在集群中被3个Java程序实例所共享。每个程序有两个线程访问计数器。这样整个集群中实际上有6个线程在同时累加计数器, 从上面可以看到,整个Java代码没有作任何改动。只是增加了一个tc-config.xml文件,从tc-config.xml文件中的配置内容可以看出,terracotta还是做了很多的工作的,而且已经比较完善,其实不管它是结合自己的产品ehcache、quartz进行整合,还是结合apache下的相关产品进行整合,terracotta可以整合的产品较多,因此我们也没有必要一个一个去搭建,它们的整合过程只是在配置的方式上有所不同,其实我们在深入了解它的原理后在进行其他产品的整合,其实都是一个简单的过程。