某点评网站爬虫分享----0基础学习,解决反爬,加密,ip代理,封ip“403 Forbidden”等问题。
最近有个调查的项目,其中包含了对于网络数据的爬取。而之前我并没学过网络爬虫,因此我也抱着学习的心态来学习如何爬取某点评网站的评论。
首先由于零基础,我先去搜索了相关视频学习爬虫的基本参数和方法,了解了requests库和beautifulsoup的基本用法。
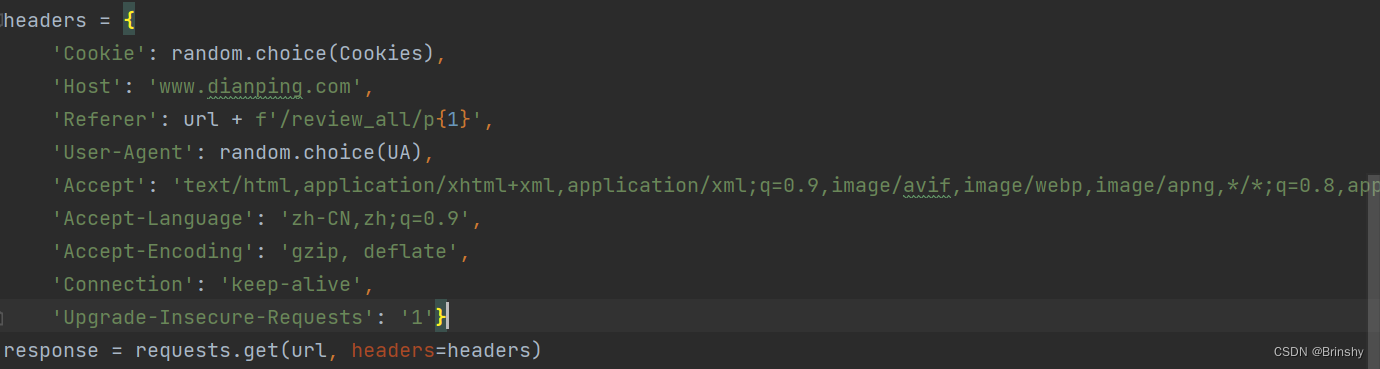
随后我就开始实战,学习某点评怎么爬取,但我 requests请求网址的时候怎么都无法成功,因此查阅资料后我才明白要请求头部加上一些信息,包括cookies,UA以及等等如下图所示:

将这些参数加入到headers里面:
终于可以请求成功了,但请求的数据一看评论内容有加密,因此我只能再去搜索资料,最终通过以下博客学习到了如何爬取评论,这里谢谢大佬先。
解决某网站css加密改进说明_丸丸丸子w的博客-CSDN博客取名最新是因为确实目前是最新的,三个月后会去掉最新找了很多博客代码都过时了,而且不是很好懂以前是字体库,现在是css加密,其反爬机制确实强本篇主要是对这篇博客的补充说明建议先食用这篇,大概懂了原理,出bug时再来看我这篇本篇主要是对原博客三个报错的说明改进。
https://blog.csdn.net/weixin_57345774/article/details/127574631
然后经历了两天的代码修改和测试,终于可以开始了,然后爬到一半又失败了,之前失误没有用ip代理,检测到我了,给我ip封了,于是出现了“403 Forbidden”。
再稍做调整之后,我就去学习如何爬虫进行ip代理,在忙忙碌碌半天后,发现好的代理好贵,而没钱的我所幸找到了一种方法,免费ip代理池——“ProxyPool”,通过以下博客的学习,我开启了ip代理。
python爬虫添加代理ip池ProxyPool (Windows)_阿言Eric的博客-CSDN博客先说一下主要的流程:下载代理ip池文件Proxypool,然后安装代理池要用到的一些扩展库和数据库Redis,启动Redis服务之后,启动ProxyPool服务,然后在python中使用ProxyPool代理ip池。1、下载代理ip池代码:用的是github上比较火的ProxyPool,下载zip文件https://github.com/jhao104/proxy_pool/releases2、解压并安装代理池需要的依赖文件:解压后,cmd命令行进入到该文件夹下(在文件夹地址栏输入cmd
开启ip代理之后,测试什么的都很轻松通过,但开始爬取评论就寄了。 emmmm可能这些免费的ip代理爬这个网站太困难了吧,10个ip里面有10个都用不了。哎。。。。
随后我发现家里另一台电脑的仍然可以正常访问,我就在想这两个电脑ip在同一个网段要封一起封啊,难不成他不是根据公网ip封的。因此我修改电脑的ip和之前不同,结果还是不行。。。。。。
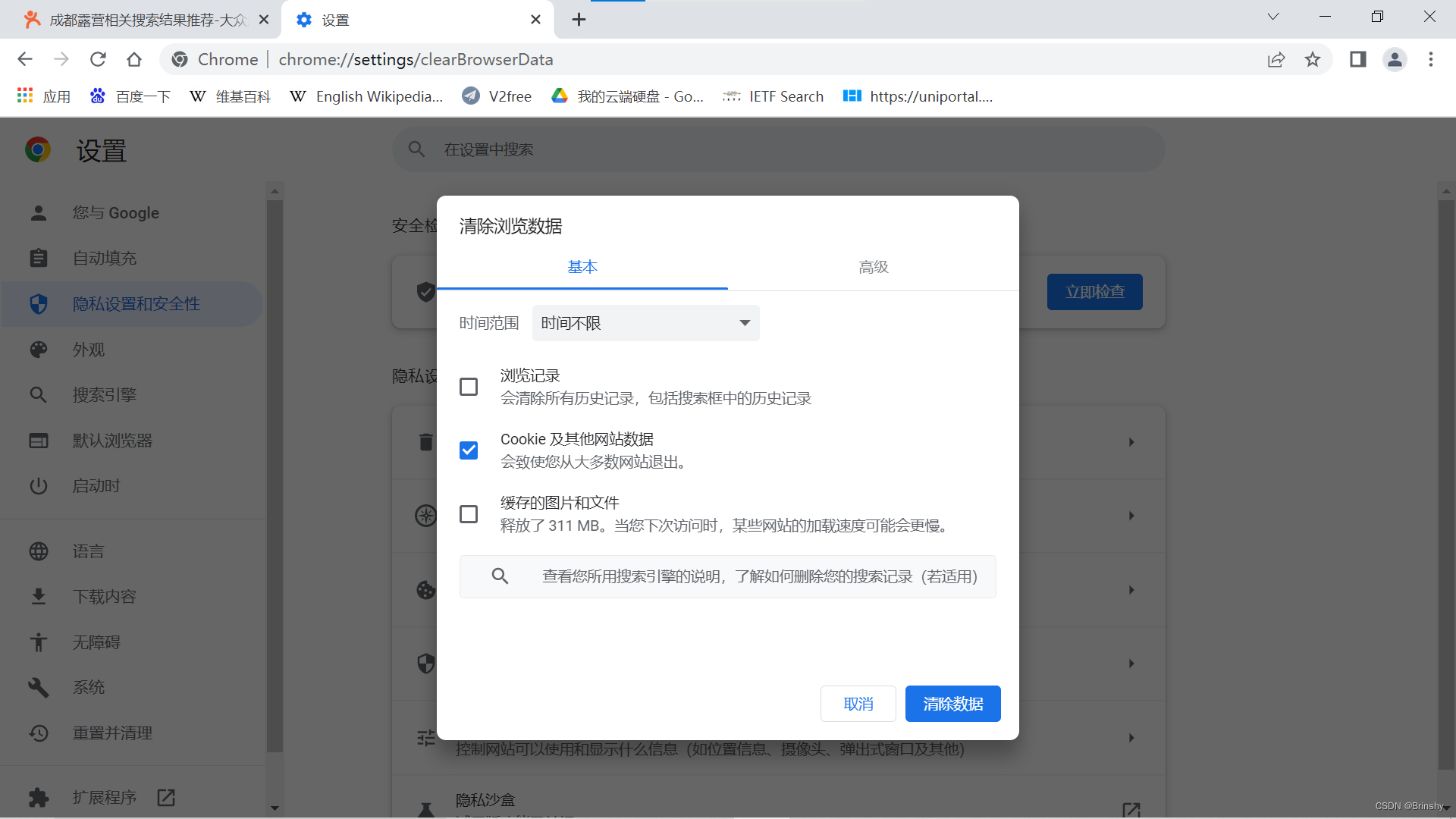
突然我想到难不成他封我更具的不是ip而是cookies,因为cookies会携带某些会话层参数。于是我把另一台电脑的cookies复制过来,发现诶的确可以,成功。因此他是根据cookies进行的封锁,这个时候就简单了,我们把浏览器的cookies清除就ok了,如下图所示。
以上问题克服完,我就开始了评论爬取,中间还有部分挫折,但都是小问题了,相信大家也可以自己慢慢克服,冲冲冲。
以下附上我的爬虫代码:
import requests
import re
from lxml import etree
import pandas as pd
import time
from bs4 import BeautifulSoup
import randomdef crew(i, headers, web, last_page):"""爬取第i页的评论:return: 第i页评论的表格"""response = requests.get(web + f'/review_all/p{i}', headers=headers)svg = ''with open('01 网页数据_加密.html', mode='w', encoding='utf-8') as f:f.write(response.text)# 求出加密方式soup = BeautifulSoup(response.text, 'html.parser')svg = soup.find('svgmtsi')['class'][0]svgmtsi = soup.find_all('svgmtsi', limit=10)for svgm in svgmtsi:svg_temp = ''for i in range(len(svg)):if svg[i] == svgm['class'][0][i]:svg_temp += svg[i]else:breaksvg = svg_temp# 获取css文件请求svg内容css_url = 'http:' + \re.findall(r'<link rel="stylesheet" type="text/css" href="(//s3plus.meituan.*?)">', response.text)[0]css_response = requests.get(css_url)with open('02 css样式.css', mode='w', encoding='utf-8') as f:f.write(css_response.text)# 获取svg映射表svg_url = 'http:' + \re.findall(r'svgmtsi\[class\^="' + svg + r'"\].*?background-image: url\((.*?)\);', css_response.text)[0]svg_response = requests.get(svg_url)with open('03 svg映射表.svg', mode='w', encoding='utf-8') as f:f.write(svg_response.text)# 获取svg加密字典import parselwith open('03 svg映射表.svg', mode='r', encoding='utf-8') as f:svg_html = f.read()sel = parsel.Selector(svg_html)texts = sel.css('text')lines = []for text in texts:lines.append([int(text.css('text::attr(y)').get()), text.css('text::text').get()])# paths = sel.css("path")# texts = sel.css('textPath')# lines = []# for path, textPath in zip(paths, texts):# lines.append([int("".join(re.findall("M0 (.*?) H600", path.css('path::attr(d)').get()))),# textPath.css('textPath::text').get()])with open('02 css样式.css', mode='r', encoding='utf-8') as f:css_text = f.read()class_map = re.findall(r'\.(' + svg + r'\w+)\{background:-(\d+)\.0px -(\d+)\.0px;\}', css_text)class_map = [(cls_name, int(x), int(y)) for cls_name, x, y in class_map]d_map = {}# 获取类名与汉字的对应关系for one_char in class_map:try:cls_name, x, y = one_charfor line in lines:if line[0] < y:passelse:index = int(x / 14)char = line[1][index]# print(cls_name,char)d_map[cls_name] = charbreakexcept Exception as e:print(e)# 替换svg加密字体,还原评论with open('01 网页数据_加密.html', mode='r', encoding='utf-8') as f:html = f.read()for key, value in d_map.items():html = html.replace('<svgmtsi class="' + key + '"></svgmtsi>', value)with open('04 网页数据.html', mode='w', encoding='utf-8') as f:f.write(html)# 去除空格,并存到dataframe中# e = etree.HTML(html)# pl = e.xpath("//div[@class='review-words Hide']/text()")# 获取信息soup = BeautifulSoup(html, 'html.parser')for e in soup.find_all('div', class_="less-words"):e.extract()reviews_items = soup.find('div', class_="reviews-items")if last_page == 0:lastpages = soup.find_all('a', class_='PageLink')for lastpage in lastpages:last_page = int(lastpage['title'])if lastpages == []:last_page = 1reviews = reviews_items.find_all('li', class_=None)pl = []for review in reviews:try:comment = review.find('div', class_="review-words Hide").get_text()except:comment = review.find('div', class_="review-words").get_text()star = review.find('div', class_="review-rank").find('span')['class'][1]time = review.find('span', class_="time").get_text()fabulous = review.find('em', class_='col-exp')if fabulous == None:fabulous = '(0)'else:fabulous = fabulous.get_text()pl.append((comment, star, time, fabulous))# comments = soup.find_all('div', class_="review-words Hide")# pl = []# for comment in comments:# pl.append(comment.get_text())dq_list = []cc_df = pd.DataFrame()for p in pl:if p[0] == '\n\t ' or p[0] == '\n ':passelse:dq_list.append(p)for pp in dq_list:# cc_df = cc_df.append({'评论': pp}, ignore_index=True)temp = pd.DataFrame({'评论': pp[0], '星级': pp[1], '时间': pp[2], '赞数': pp[3]}, index=[0])cc_df = pd.concat([cc_df, temp], ignore_index=True)return cc_df, last_pagedef get_web(i, url, headers, key_words, tag_word):webs = []resp = requests.get(url + f'/p{i}', headers=headers)soup = BeautifulSoup(resp.text, 'html.parser')items = (soup.find('div', class_="shop-list J_shop-list shop-all-list").find_all('li'))for item in items:link = item.find('div', class_='txt').find('div', class_='tit').find('a')tag = item.find('span', class_='tag').get_text()comment_have = item.find('a', class_="review-num")istopTrade = item.find('span', class_="istopTrade")if istopTrade != None:if istopTrade.get_text() == '(尚未营业)':continueif comment_have == None:continueflag_tag = Falsefor tag_w in tag_word:if tag_w in tag:flag_tag = Truebreakif flag_tag == False:continuefor word in key_words:if word in link['title']:webs.append((link['title'], link['href']))breakreturn websdef add_workbook():with open("out.csv", "ab") as f:f.write(open("new_out.csv", "rb").read())return None# ip代理地址池用的函数
# def get_proxy():
# # 5000:settings中设置的监听端口,不是Redis服务的端口
# return requests.get("http://127.0.0.1:5010/get/").json()
# def delete_proxy(proxy):
# requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))if __name__ == '__main__':# 用自己的headers、Cookies、UACookies = []UA = []# 爬虫读取每一个店家网址getweb = Falseif getweb:webs = []start = 1 # 默认第一遍从第2页开始end = 40 # 默认爬取200页for i in range(start, end + 1):url = 'https://www.dianping.com/search/keyword/8/0_%E9%9C%B2%E8%90%A5'# 用自己的headers、Cookies、UAheaders = {}temp_web = get_web(i, url, headers, ['营'], ['采摘', '拓展', '游', '融'])for web in temp_web:if web not in webs:webs.append(web)time.sleep(10)print(f'第{i}页店家获取成功')with open(r'00 店家网址.txt', 'w', encoding='utf-8') as f:for web in webs:f.write(str(web[0]) + ':' + str(web[1]) + '\n')# 读取txt获取网址webs = []with open(r'00 店家网址.txt', 'r', encoding='utf-8') as f:web = f.readline().rstrip().split(':')if web != ['']:webs.append(web)while web != ['']:web = f.readline().rstrip().split(':')if web != ['']:webs.append(web)with pd.ExcelWriter('评论汇总.xlsx', mode='a', engine="openpyxl") as writer:for web_all in webs:# 设置开始页数和终止界面start_page = 1 # 默认第一遍从第2页开始end_page = 300 # 默认爬取200页last_page = 0df1 = pd.DataFrame()# 开始爬虫try:for i in range(start_page, end_page + 1):# 设置访问头部和页面web = web_all[1]# 用自己的headers、Cookies、UACookies = []headers = {}df2, last_page = crew(i, headers, web, last_page)df1 = pd.concat([df1, df2], axis=0, ignore_index=True)time.sleep(10 + random.randint(1, 10))print(web_all[0] + f"----第{i}页爬取成功" + f"----总共页数{last_page}")# 存入exceldf1.reset_index(inplace=True)df1.to_excel(writer, sheet_name=web_all[0], index=False)print(web_all[0] + f"----最终页数{end_page}")except:# 存入excelif last_page != i - 1 or i - 1 == 0:print(web_all[0] + ':爬虫失败中断')with open(r'05 中断爬取点位.txt', 'w', encoding='utf-8') as f1:f1.write(str(web_all[0]) + ':' + str(web_all[1]) + '\n')breakelse:df1.reset_index(inplace=True)df1.to_excel(writer, sheet_name=web_all[0], index=False)print(web_all[0] + f"----最终页数{i - 1}")