最近想爬取网易云音乐的歌单,发现网上很多教程都用Selenium,比较麻烦。因为研究网易云音乐排行榜html码源,发现榜单是iframe动态加载的。用原网址爬取是爬取不到内容的。想用requests爬取的话需要获取iframe的源码。
目录
- 一、url和请求头分析
- 二、获取信息
- 三、下载歌曲
- 四、写入csv文件
- 五、代码整合
一、url和请求头分析
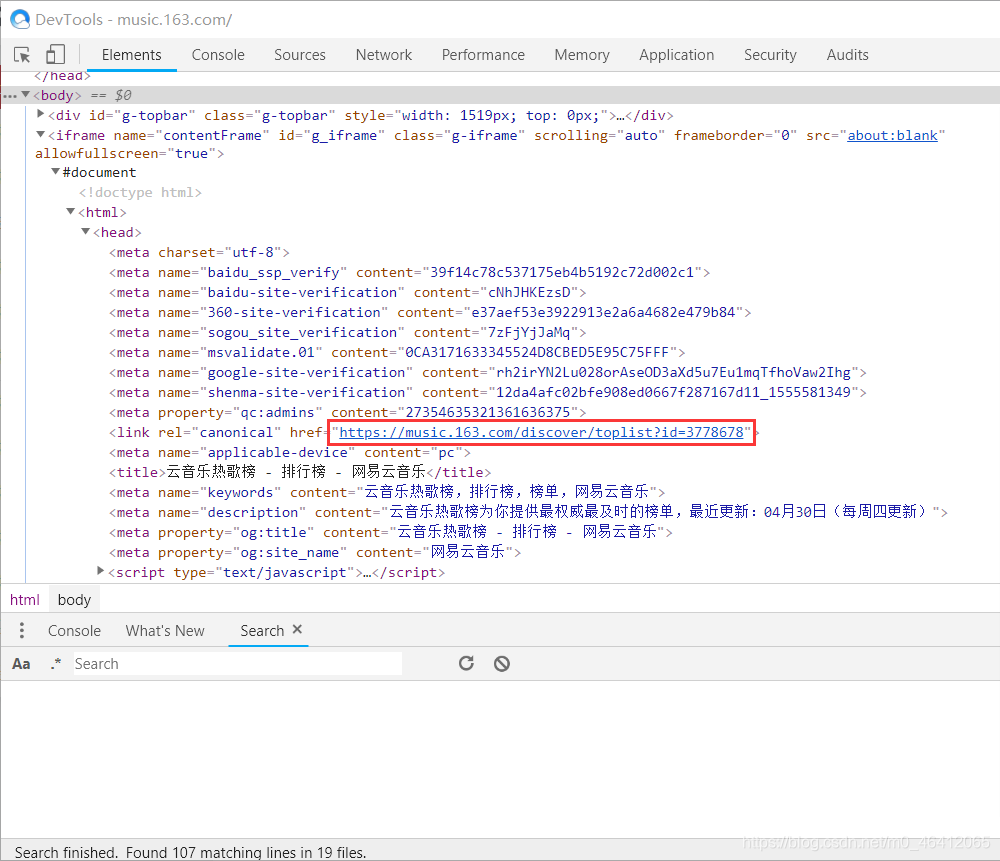
比如爬取这个云音乐热歌榜。网址为
https://music.163.com/#/discover/toplist?id=3778678
这样是获取不到我们想要的信息的
import requests
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}
res=requests.get("https://music.163.com/#/discover/toplist?id=3778678",headers=headers).text
通过观察节点代码发现,这两个网址都是可以获取到我们想要的信息,
https://music.163.com/m/discover/toplist?id=3778678
https://music.163.com/discover/toplist?id=3778678
也就是框架的源代码。请求头非常简单只需要User-Agent就行。
二、获取信息
有了源码获取信息就变得简单了。用xpath,pyquery,beautifulsoup都行。
这里写一个类,方便爬取其他榜单的歌曲。通过观察发现我们需要获取id为
song-list-pre-data 的节点的文本信息,并且这个文本是一个列表。这里初始化了一个id参数,id对应着不同的榜单。选择用pyquery来解析源码。并转换成json格式的数据。利用get方法来寻找相应的歌曲名等。
from pyquery import PyQuery as pq
import requests
import json
import csv
import re
class Wangyi_yun(object):def __init__(self,id):#定义初始信息请求头和urlself.headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}self.id=idself.url="https://music.163.com/m/discover/toplist?id="+str(self.id)def get_page(self):#获取网页源代码res=requests.get(self.url,headers=self.headers).textreturn resdef get_data(self,html):#利用pyquery库解析原网页doc=pq(html)result=doc("#song-list-pre-data").text()return json.loads(result)def main(self):#获取歌曲名字等详细信息data=self.get_page()json_data=self.get_data(data)for item in range(len(json_data)):yield{"name":json_data[item].get("name"),"singer":json_data[item].get("artists")[0].get("name"),"url":"https://music.163.com/#/song?id="+str(json_data[item].get("id"))"ID":json_data[item].get("id")}三、下载歌曲
网易云音乐的下载链接为
http://music.163.com/song/media/outer/url?id=
只需把歌曲的id补上即可。注意这里的id是歌曲的id。不是榜单的id。
def get_download(self,ID,name):"""下载歌曲,并保存到本地工作路径:param name 歌曲名字:param ID 歌曲的ID""" r=requests.get("http://music.163.com/song/media/outer/url?id="+ID)with open(name+".mp3","wb") as file: file.write(r.content)
四、写入csv文件
def write_csv(self, data):#参数data为main()函数生成的为字典with open("wangyiyun.csv", "a", encoding="utf-8-sig", newline='') as file:fieldnames = ["name", "singer","url"]writer = csv.DictWriter(file, fieldnames=fieldnames)writer.writerow(data)五、代码整合
from pyquery import PyQuery as pq
import requests
import json
import csv
import re
class Wangyi_yun(object):def __init__(self,id):#定义初始信息请求头和urlself.headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}self.id=idself.url="https://music.163.com/m/discover/toplist?id="+str(self.id)def get_page(self):#获取网页源代码res=requests.get(self.url,headers=self.headers).textreturn resdef get_data(self,html):#利用pyquery库解析原网页doc=pq(html)result=doc("#song-list-pre-data").text()return json.loads(result)def get_download(self,ID,name):#下载歌曲,并保存到本地工作路径 #http://music.163.com/song/media/outer/url?id=为网易云的下载连接更换id即可r=requests.get("http://music.163.com/song/media/outer/url?id="+str(ID))with open(name+".mp3","wb") as file: file.write(r.content)def write_csv(self, data):#利用csv库将json数据保存到csv中with open("wangyiyun.csv", "a", encoding="utf-8-sig", newline='') as file:fieldnames = ["name", "singer","url","ID"]writer = csv.DictWriter(file, fieldnames=fieldnames)writer.writerow(data)def main(self):data=self.get_page()json_data=self.get_data(data)for item in range(len(json_data)):yield{"name":json_data[item].get("name"),"singer":json_data[item].get("artists")[0].get("name"),"url":"https://music.163.com/#/song?id="+str(json_data[item].get("id")),"ID":json_data[item].get("id")}if __name__=="__main__": rank_music=Wangyi_yun(3779629) #参数为榜单相应url的idfor items in rank_music.main():rank_music.write_csv(items)#写入csv文件for items in rank_music.main():#遍历生成器ID=items.get("ID")name=items.get("name")rank_music.get_download(ID,name)time.sleep(3)