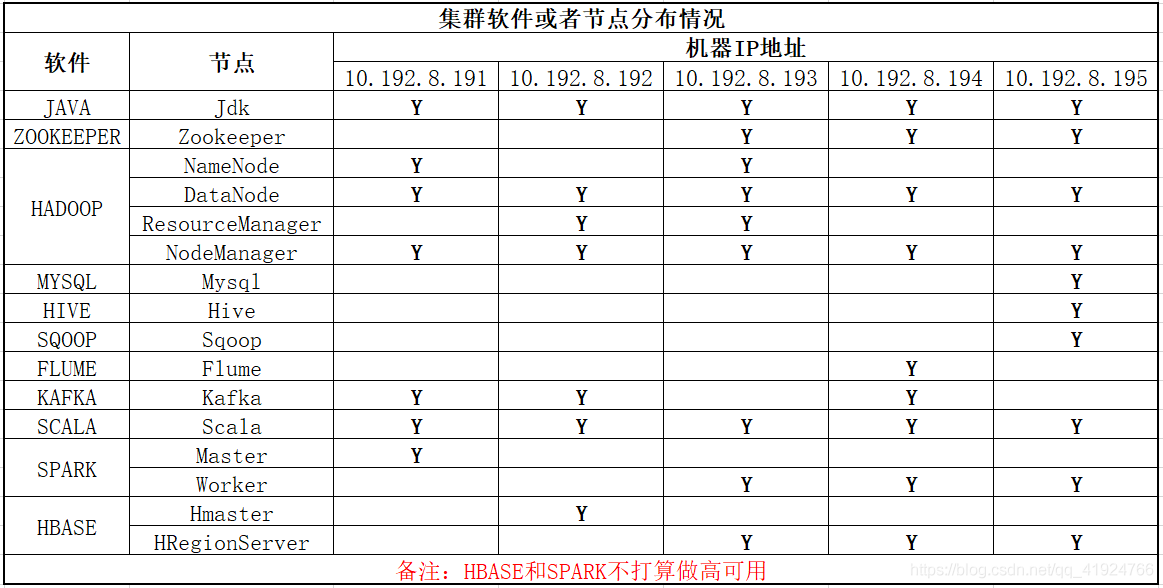
一、数仓之Cloudera Manager
1、CM简介
1.1、简介
Cloudera Manager是一个拥有集群自动化安装、中心化管理、集群监控、报警功能的一个工具。
1.2、架构

1)Cloudera Repository:软件由Cloudera管理分布存储库。(有点类似Maven的中心仓库)
2)Server:负责软件安装、配置,启动和停止服务,管理服务运行的群集。
3)Management Service:由一组执行各种监控,警报和报告功能角色的服务。
4)Database:存储配置和监视信息。
5)Agent:安装在每台主机上。负责启动和停止的过程,配置,监控主机。
6)Clients:是用于与服务器进行交互的接口(API和Admin Console)
2、环境准备
2.1、虚拟机准备
克隆三台虚拟机(hadoop102、hadoop103、hadoop104),配置好对应主机的网络IP、主机名称、关闭防火墙。
rpm -qa |grep vim #查看是否安装vim编辑器
yum -y install vim* #安装
yum install net-tools #安装网络包
ifconfig #查看网络
ifup ens33 #激活网络
vi /etc/sysconfig/network-scripts/ifcfg-ens33 #修改网络
systemctl restart network #重启网络
vim /etc/hostname #修改主机名(hadoop102、hadoop103、hadoop104)
#三台主机关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#在三台主机的/etc/hosts配置ip地址与主机名映射
vim /etc/hosts
192.168.186.102 hadoop102
192.168.186.103 hadoop103
192.168.186.104 hadoop104
2.2、SSH免密登录
配置hadoop102对hadoop102、hadoop103、hadoop104三台服务器免密登录。CDH服务开启与关闭是通过server和agent来完成的,所以这里不需要配置SSH免密登录,但是为了我们分发文件方便,在这里我们也配置SSH。
1)生成公钥和私钥:
ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
2)将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
3)重复1和2的操作,配置hadoop103对hadoop102、hadoop103、hadoop104三台服务器免密登录。
2.3、集群同步脚本
在/root目录下创建bin目录,并在bin目录下创建文件xsync,文件内容如下:
mkdir bin
cd bin/
yum -y install rsync #安装rsync同步
vi xsync #创建文件
在该文件中编写如下代码
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname #3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir#4 获取当前用户名称
user=`whoami`#5 循环
for((host=103; host<105; host++)); doecho ------------------- hadoop$host --------------rsync -av $pdir/$fname $user@hadoop$host:$pdir
done
修改脚本 xsync 具有执行权限
chmod 777 xsync
2.4、安装JDK(三台)
在hadoop102的/opt目录下创建module和software文件夹
yum install lrzsz #安装上传(rz)下载(sz)包
cd /opt #进入opt目录
mkdir module #创建目录
mkdir software #创建目录
cd software/ #进入目录
#需要使用官网提供的jdk
rz #上传oracle-j2sdk1.8-1.8.0+update181-1.x86_64.rpm
rpm -ivh oracle-j2sdk1.8-1.8.0+update181-1.x86_64.rpm #安装
配置JDK环境变量
打开/etc/profile文件
vim /etc/profile
在profile文件末尾添加JDK路径
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
让修改后的文件生效
source /etc/profile
检测是否安装成功
java -version
将hadoop102中的JDK和环境变量分发到hadoop103、hadoop104两台主机
xsync /usr/java/ #同步到另外两台
xsync /etc/profile
分别在hadoop103、hadoop104上source一下
[root@hadoop103 ~]# source /etc/profile
[root@hadoop104 ~]# source /etc/profile
2.5、集群整体操作脚本
在/root/bin目录下创建脚本xcall.sh
[root@hadoop102 bin]$ vim xcall.sh
在脚本中编写如下内容
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
doecho --------- $i ----------ssh $i "$*"
done
修改脚本执行权限
[root@hadoop102 bin]$ chmod 777 xcall.sh
将/etc/profile文件追加到~/.bashrc后面
[root@hadoop102 module]# cat /etc/profile >> ~/.bashrc[root@hadoop103 module]# cat /etc/profile >> ~/.bashrc[root@hadoop104 module]# cat /etc/profile >> ~/.bashrc
测试
[root@hadoop102 bin]# xcall.sh jps

2.6、安装MySQL
注意:一定要用root用户操作如下步骤;先卸载MySQL再安装
安装包准备
#查看MySQL是否安装
rpm -qa|grep -i mysql
#如果安装了MySQL,就先卸载
rpm -e --nodeps mysql包
#删除阿里云原有MySql依赖
yum remove mysql-libs#下载MySql依赖并安装
yum install libaio
yum -y install autoconfcd /opt/software
yum install wget
wget https://downloads.mysql.com/archives/get/p/23/file/MySQL-shared-compat-5.6.24-1.el6.x86_64.rpm
wget https://downloads.mysql.com/archives/get/p/23/file/MySQL-shared-5.6.24-1.el6.x86_64.rpm#安装
rpm -ivh MySQL-shared-5.6.24-1.el6.x86_64.rpm
rpm -ivh MySQL-shared-compat-5.6.24-1.el6.x86_64.rpm#上传mysql-libs.zip到hadoop102的/opt/software目录,并解压文件到当前目录
rz
yum install unzip
unzip mysql-libs.zip#进入到mysql-libs文件夹下
cd mysql-libs
安装MySQL服务端
rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
查看产生的随机密码
cat /root/.mysql_secret
#查看MySQL状态
service mysql status
#启动MySQL
service mysql start
安装MySQL客户端
#安装MySQL客户端
rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
mysql -uroot -pOEXaQuS8IWkG19Xs
#修改密码
SET PASSWORD=PASSWORD('root');
exit;
#进入MySQL
mysql -uroot -proot
#显示数据库
show databases;
#使用MySQL数据库
use mysql;
#展示MySQL数据库中的所有表
show tables;
#展示user表的结构
desc user;
#查询user表
select User, Host, Password from user;
#修改user表,把Host表内容修改为%
update user set host='%' where host='localhost';
#删除root用户的其他host
delete from user where host!='%';
#刷新
flush privileges;
#退出
quit;
2.7、创建CM用的数据库
在MySQL中依次创建监控数据库、Hive数据库、Oozie数据库、Hue数据库
mysql> GRANT ALL ON scm.* TO 'scm'@'%' IDENTIFIED BY 'scm';
mysql> CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
#Hive数据库
mysql> CREATE DATABASE hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
#Oozie数据库
mysql> CREATE DATABASE oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
#Hue数据库
mysql> CREATE DATABASE hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
2.8、下载第三方依赖
三台节点上全部执行下面依赖的语句,需要联网
yum -y install chkconfig python bind-utils psmisc libxslt zlib sqlite cyrus-sasl-plain cyrus-sasl-gssapi fuse fuse-libs redhat-lsb
2.9、关闭SELINUX
安全增强型Linux(Security-Enhanced Linux)简称SELinux,它是一个 Linux 内核模块,也是Linux的一个安全子系统。为了避免安装过程出现各种错误,建议关闭,有如下两种关闭方法:
临时关闭(不建议使用)
setenforce 0 #但是这种方式只对当次启动有效,重启机器后会失效。永久关闭
#修改配置文件/etc/selinux/config
vim /etc/selinux/config
将SELINUX=enforcing 改为SELINUX=disabled
SELINUX=disabled
#同步/etc/selinux/config配置文件
xsync /etc/selinux/config
#重启hadoop102、hadoop103、hadoop104主机
reboot #重启
2.10、配置时间同步
NTP服务器配置
yum install ntp #集群中所有节点安装ntp
[root@hadoop102 ~]# vim /etc/ntp.conf
#注释掉所有的restrict开头的配置
#添加下面一行
restrict 192.168.186.102 mask 255.255.255.0 nomodify notrap
#将所有server配置进行注释
#添加下面两行内容
server 127.127.1.0
fudge 127.127.1.0 stratum 10
启动NTP服务
service ntpd start
NTP客户端配置(hadoop103,hadoop104)
vim /etc/ntp.conf
# 注释所有restrict和server配置
# 添加下面一行
server 192.168.186.102
手动测试
ntpdate 192.168.186.102
显示如下内容为成功:
22 Jun 15:09:23 ntpdate[29268]: adjust time server 192.168.186.102 offset 0.006673 sec
如果显示如下内容需要先关闭ntpd:
22 Jun 15:17:28 ntpdate[49701]: the NTP socket is in use, exiting
启动ntpd并设置为开机自启(每个节点hadoop102,hadoop103,hadoop104)
chkconfig ntpd on
service ntpd start
使用群发date命令查看结果,时间相同,同步完成,finalshell可以群发命令的
3、CM安装部署
3.1、CM安装包
cm6.3.1-redhat7.tar.gz
3.2、CM安装
将mysql-connector-java-5.1.27-bin.jar拷贝到usr/share/java路径下,并重命名
cd /opt/software/mysql-libs/
rz #上传
tar -zxvf mysql-connector-java-5.1.27.tar.gz #解压
cd mysql-connector-java-5.1.27
mv mysql-connector-java-5.1.27-bin.jar mysql-connector-java.jar
mkdir /usr/share/java #新建目录
cp mysql-connector-java.jar /usr/share/java/
scp -r /usr/share/java/ hadoop103:/usr/share/
scp -r /usr/share/java/ hadoop104:/usr/share/
集群规划
| 节点 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 服务 | cloudera-scm-server cloudera-scm-agent | cloudera-scm-agent | cloudera-scm-agent |
上传解压
#创建cloudera-manager目录,存放cdh安装文件
mkdir /opt/cloudera-manager
cd /opt/software/ #进入目录
tar -zxvf cm6.3.1-redhat7.tar.gz #解压
#进入解压后的文件
cd cm6.3.1/RPMS/x86_64/
#移动rpm包
mv cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm /opt/cloudera-manager/
mv cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm /opt/cloudera-manager/
mv cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm /opt/cloudera-manager/
#进入目录查看
cd /opt/cloudera-manager/#安装cloudera-manager-daemons,安装完毕后多出/opt/cloudera目录
rpm -ivh cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
cd /opt/cloudera
cd ..
xsync /opt/cloudera-manager/ #同步到hadoop103、hadoop104#进入hadoop103和hadoop104安装daemons
[root@hadoop103 ~]# cd /opt/cloudera-manager/
[root@hadoop103 cloudera-manager]# rpm -ivh cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
[root@hadoop104 ~]# cd /opt/cloudera-manager/
[root@hadoop104 cloudera-manager]# rpm -ivh cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
安装cloudera-manager-agent
#三台机器安装依赖
yum install bind-utils psmisc cyrus-sasl-plain cyrus-sasl-gssapi fuse portmap fuse-libs /lib/lsb/init-functions httpd mod_ssl openssl-devel python-psycopg2 MySQL-python libxslt
#三台机器安装manager-agent
rpm -ivh cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm
三台机器安装agent的server节点
#在hadoop102上修改配置文件
vim /etc/cloudera-scm-agent/config.ini
#修改下面参数
server_host=hadoop102
#脚本同步到hadoop103和hadoop104
xsync /etc/cloudera-scm-agent/config.ini
安装cloudera-manager-server
#在hadoop102执行
rpm -ivh cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm
上传CDH包到parcel-repo
cd /opt/cloudera/parcel-repo/
rz
#包名分别为:
CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel
CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha1
manifest.json
#改名
mv CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha1 CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha
修改server的db.properties
vim /etc/cloudera-scm-server/db.properties
com.cloudera.cmf.db.type=mysql
com.cloudera.cmf.db.host=hadoop102:3306
com.cloudera.cmf.db.name=scm
com.cloudera.cmf.db.user=scm
com.cloudera.cmf.db.password=scm
com.cloudera.cmf.db.setupType=EXTERNAL
启动server服务
/opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm scm
systemctl start cloudera-scm-server
systemctl status cloudera-scm-server
假如报错
我们进入目录查看日志:
cd /var/log/cloudera-scm-server
或者
journalctl -xe
启动agent节点(三台)
systemctl start cloudera-scm-agent
4、CM的集群部署
访问http://hadoop102:7180,(用户名、密码:admin)

4.1、接收条款和协议



4.2、集群安装


4.3、指定主机

4.4、选择CDH版本6.3.2

若出现没有版本执行下面:
cd /opt/cloudera/parcel-repo #进入本地存储
查看是否有
-rw-r--r-- 1 root root 2082186246 6月 22 17:01 CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel
-rw-r--r-- 1 root root 40 6月 22 16:15 CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha
-rw-r--r-- 1 root root 33887 6月 22 16:14 manifest.json
systemctl restart cloudera-scm-server#重启服务
如果还不行,就重启服务器或者查看文件权限
chmod 644 manifest.json 赋权
chmod 644 CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha
chmod 644 CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel
4.5、等待下载安装

4.6、检查网络性能,检查主机



[root@hadoop101 software]# echo never > /sys/kernel/mm/transparent_hugepage/defrag
[root@hadoop101 software]# echo never > /sys/kernel/mm/transparent_hugepage/enabled
[root@hadoop102 software]# echo never > /sys/kernel/mm/transparent_hugepage/defrag
[root@hadoop102 software]# echo never > /sys/kernel/mm/transparent_hugepage/enabled
[root@hadoop103 software]# echo never > /sys/kernel/mm/transparent_hugepage/defrag
[root@hadoop103 software]# echo never > /sys/kernel/mm/transparent_hugepage/enabled

还可能警告:

Cloudera 建议将 /proc/sys/vm/swappiness 设置为最大值 10。当前设置为 30。使用 sysctl 命令在运行时更改该设置并编辑 /etc/sysctl.conf,以在重启后保存该设置。您可以继续进行安装,但 Cloudera Manager 可能会报告您的主机由于交换而运行状况不良。
# 三台主机运行:
echo 10 > /proc/sys/vm/swappiness

4.7、群集设置

二、数仓之数据采集模块
1、HDFS、YARN、Zookeeper安装
1.1、选择自定义安装

1.2、选择安装服务

1.3、分配节点

1.4、集群设置全部选默认即可

1.5、自动启动进程

1.6、修改HDFS中的权限检查:dfs.permissions





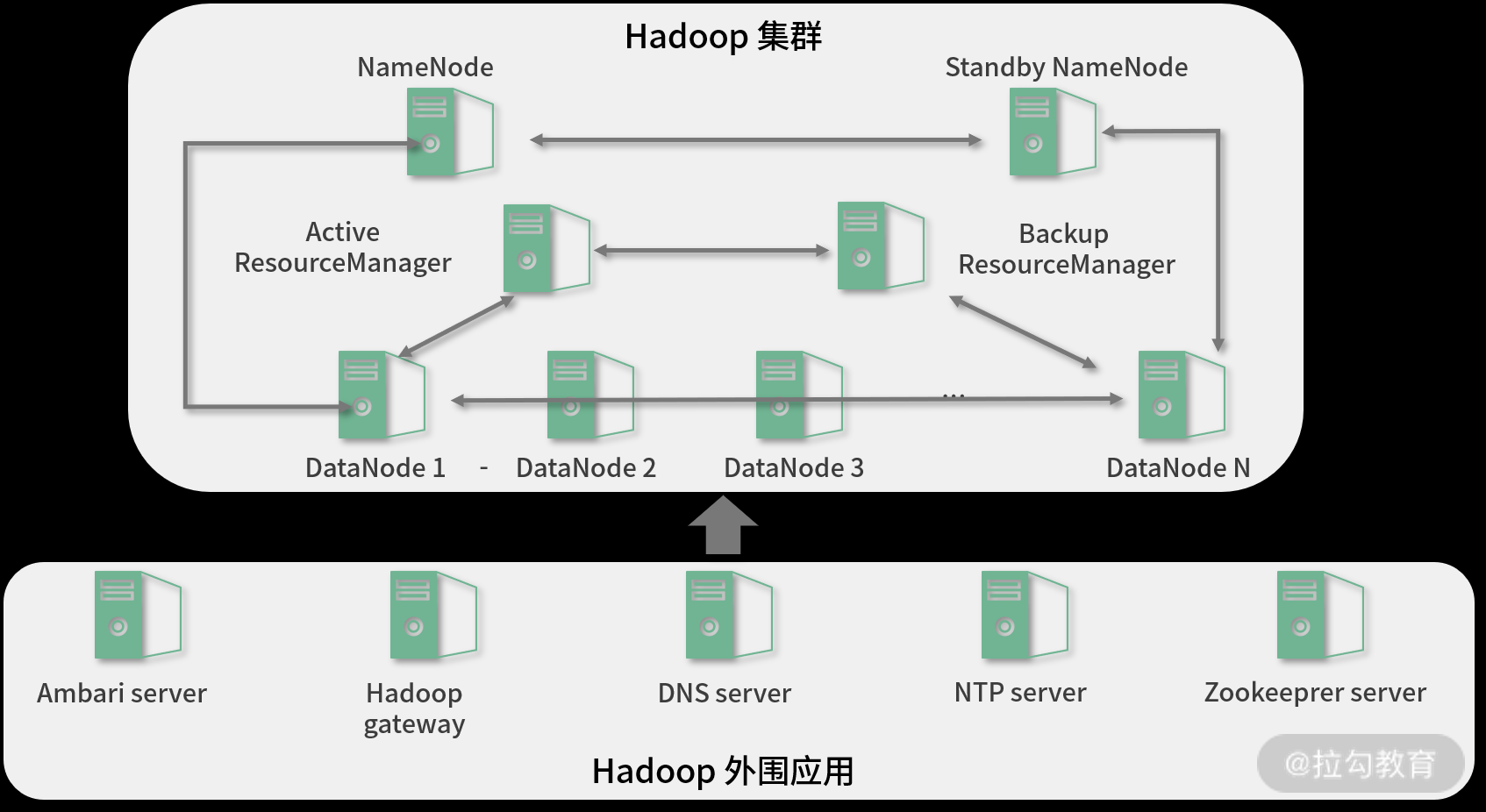
1.7、配置NameNode HA
进入HDFS页面点击启动High Availability

命名

分配角色

审核更改

等待启动服务

1.8、配置Yarn HA



2、Kafka安装
2.1、Kafka安装
可以选择在线安装和离线包安装,在线安装下载时间较长,离线包安装时间较短。这里我们为了节省时间,选择离线安装。
添加服务

选择Kafka,点击继续

Kafka的Broker选择三台机器





2.2、查看Kafka Topic
[root@hadoop102 ~]# /opt/cloudera/parcels/CDH/bin/kafka-topics --zookeeper hadoop102:2181 --list
2.3、创建Kafka Topic
进入到/opt/cloudera/parcels/KAFKA目录下分别创建:启动日志主题、事件日志主题
#创建topic test
/opt/cloudera/parcels/CDH/bin/kafka-topics --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 --create --replication-factor 1 --partitions 1 --topic test
2.4、删除Kafka Topic
#删除启动日志主题
/opt/cloudera/parcels/CDH/bin/kafka-topics --delete --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test
三、数仓搭建环境准备
1、Hive安装
1.1、添加服务

1.2、添加hive服务

1.3、将Hive服务添加到集群

1.4、配置hive 元数据

1.5、测试通过后继续

1.6、自动启动Hive进程


四、Spark 安装
1、安装Spark
CDH6.x自带spark2.4无需升级










五、其他配置
1、HDFS配置域名访问
在阿里云环境下 Hadoop集群必须用域名访问,不能用IP访问,开启如下配置dfs.client.use.datanode.hostname


2、设置物理核和虚拟核占比
为演示效果将虚拟核扩大1倍,一般真实场景下物理核和虚拟核对比值为1:1或1:2
修改配置,每台机器物理核2核虚拟成4核
yarn.nodemanager.resource.cpu-vcores

3、修改单个容器下最大cpu申请资源
修改yarn.scheduler.maximum-allocation-vcores参数调整4核

4、设置每个任务容器内存大小和单节点大小
将每个任务容器默认大小从1G调大至4G,当前集群环境下每个节点的物理内存为8G,设置每个yarn可用每个节点内存为7G
修改yarn.scheduler.maximum-allocation-mb 每个任务容器内存所需大小

修改yarn.nodemanager.resource.memory-mb每个节点内存所需大小

5、关闭Spark动态分配资源参数
关闭spark.dynamicAllocation.enabled 参数否则分配的资源不受控制

6、修改HDFS副本数
修改副本数为1
dfs.replication

7、设置容量调度器
CDH默认公平调度器,修改为容量调度器
yarn
Scheduler

默认root队列,可以进行修改,添加3个队列spark,hive,flink,spark资源设置占yarn集群40%,hive设置占yarn集群20%,flink设置占40%


配置完毕后重启服务,到yarn界面查看调度器,已经发生变化有hive队列和spark队列

六、配置OOZIE








七、配置HUE










八、配置KUDU





九、 配置Impala