CDH大数据平台搭建之HADOOP安装
- 一、什么是HADOOP?
- 二、如何下载
- 1.官网下载
- 2.网盘下载
- 三、搭建集群
- 1.虚拟机准备
- 2.安装JDK
- 3.安装ZOOKEEPER
- 4.集群规划
- 5.安装HADOOP
- 6.修改配置文件
- 1、进入配置文件目录:
- 2、修改env文件
- 3、修改core-site.xml文件
- 4、修改hdfs-site.xml文件
- 5、配置mapred-site.xml文件
- 6、修改yarn-site.xml文件
- 7、修改slaves文件
- 8、分发文件
- 9、配置环境变量
- 四、启动集群
- 1.启动ZOOKEEPER集群
- 2.启动JournalNode
- 3.格式化namenode
- 4.格式化zkfc
- 5.启动zkfc
- 6.启动namenode
- 7.格式化secondarynamenode
- 8.启动secondarynamenode
- 9.验证是否成功
- 10.启动datanode
- 11.启动resourcemanager
- 12.启动nodemanager
- 五、各个机器命令进程
- 六、网页端口效果
- 1、namenode
- resourcemanager
- 七、高可用测试
- 总结
一、什么是HADOOP?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要是分布式数据存储以及计算。
二、如何下载
1.官网下载
1、apache版本:http://hadoop.apache.org/
2、cdh版本(已收费):http://archive.cloudera.com/cdh5/cdh/5/
2.网盘下载
链接:https://pan.baidu.com/s/18x2lc0Z7JbJ7pW-15VtiDg 提取码:cdh5
三、搭建集群
1.虚拟机准备
请参考CHD大数据平台搭建之VMware及虚拟机安装
以及CHD大数据平台搭建之虚拟环境配置
2.安装JDK
请参考CHD大数据平台搭建之JDK安装
3.安装ZOOKEEPER
请参考CHD大数据平台搭建之ZOOKEEPER安装
4.集群规划
请参考CHD大数据平台搭建之集群规划
5.安装HADOOP
tar -zxvf hadoop-2.6.0-cdh5.7.6.tar.gz -C /opt/modules/
6.修改配置文件
1、进入配置文件目录:
cd /opt/modules/hadoop-2.6.0-cdh5.7.6/etc/hadoop
2、修改env文件
配置env文件java安装目录
hadoop-env.sh
mapred-env.sh
yarn-env.sh
修改:export JAVA_HOME=/opt/modules/jdk1.8.0_91
3、修改core-site.xml文件
1、新建文件夹:
mkdir -p /opt/modules/hadoop-2.6.0-cdh5.7.6/data/tmp
2、添加如下内容
<property><name>fs.defaultFS</name><value>hdfs://mycluster</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property><name>hadoop.tmp.dir</name><value>/opt/modules/hadoop-2.6.0-cdh5.7.6/datas/tmp</value>
</property>
<!-- zookeeper通讯地址-->
<property><name>ha.zookeeper.quorum</name><value>bigdata-training03.hpsk.com:2181,bigdata-training04.hpsk.com:2181,bigdata-training05.hpsk.com:2181</value>
</property>
4、修改hdfs-site.xml文件
1、新建文件夹:
mkdir -p /opt/modules/hadoop-2.6.0-cdh5.7.6/datas/jn
2、添加如下内容:
<!-- 完全分布式集群名称 -->
<property><name>dfs.nameservices</name><value>mycluster</value>
</property><!-- 集群中NameNode节点都有哪些 -->
<property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value>
</property><!-- nn1的RPC通信地址 -->
<property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>bigdata-training01.hpsk.com:9000</value>
</property><!-- nn2的RPC通信地址 -->
<property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>bigdata-training03.hpsk.com:9000</value>
</property><!-- nn1的http通信地址 -->
<property><name>dfs.namenode.http-address.mycluster.nn1</name><value>bigdata-training01.hpsk.com:50070</value>
</property><!-- nn2的http通信地址 -->
<property><name>dfs.namenode.http-address.mycluster.nn2</name><value>bigdata-training03.hpsk.com:50070</value>
</property><!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://bigdata-training01.hpsk.com:8485;bigdata-training02.hpsk.com:8485;bigdata-training03.hpsk.com:8485;bigdata-training04.hpsk.com:8485;bigdata-training05.hpsk.com:8485/mycluster</value>
</property><!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property><name>dfs.ha.fencing.methods</name><value>sshfence</value>
</property><!-- 使用隔离机制时需要ssh无秘钥登录-->
<property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hpsk/.ssh/id_rsa</value>
</property><!-- 声明journalnode服务器存储目录-->
<property><name>dfs.journalnode.edits.dir</name><value>/opt/modules/hadoop-2.6.0-cdh5.7.6/datas/jn</value>
</property><!-- 关闭权限检查-->
<property><name>dfs.permissions.enable</name><value>false</value>
</property><!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property><!-- 自动切换-->
<property><name>dfs.ha.automatic-failover.enabled</name><value>true</value>
</property>
5、配置mapred-site.xml文件
1、修改文件名
mv mapred-site.xml.template mapred-site.xml
2、添加如下内容:
<!-- 指定MR运行在YARN上 -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property><!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>bigdata-training02.hpsk.com:10020</value>
</property>
6、修改yarn-site.xml文件
1、添加如下内容:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property><!--启用resourcemanager ha-->
<property><name>yarn.resourcemanager.ha.enabled</name><value>true</value>
</property><!--声明两台resourcemanager的地址-->
<property><name>yarn.resourcemanager.cluster-id</name><value>cluster-yarn1</value>
</property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value>
</property><property><name>yarn.resourcemanager.hostname.rm1</name><value>bigdata-training02.hpsk.com</value>
</property><property><name>yarn.resourcemanager.hostname.rm2</name><value>bigdata-training03.hpsk.com</value>
</property><!--指定zookeeper集群的地址-->
<property><name>yarn.resourcemanager.zk-address</name><value>bigdata-training03.hpsk.com:2181,bigdata-training04.hpsk.com:2181,bigdata-training05.hpsk.com:2181</value>
</property><!--启用自动恢复-->
<property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value>
</property><!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property><name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property><!-- 日志聚集功能使能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property><!-- 日志保留时间设置7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
7、修改slaves文件
1、添加如下内容:
bigdata-training01.hpsk.com
bigdata-training02.hpsk.com
bigdata-training03.hpsk.com
bigdata-training04.hpsk.com
bigdata-training05.hpsk.com
8、分发文件
xsync参考CHD大数据平台搭建之xsync分发脚本
xsync hadoop-2.6.0-cdh5.7.6
9、配置环境变量
1、编辑配置文件
sudo vi /etc/profile
2、添加内容
# HADOOP_HOME
export HADOOP_HOME=/opt/modules/hadoop-2.6.0-cdh5.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
四、启动集群
1.启动ZOOKEEPER集群
在193、194、195三台机器启动ZK
zkServer.sh start
2.启动JournalNode
5台机器上面都执行
sbin/hadoop-daemon.sh start journalnode
3.格式化namenode
191上面格式化namenode
bin/hdfs namenode -format
4.格式化zkfc
191上面格式化zkfc
bin/hdfs zkfc -formatZK
5.启动zkfc
在191和193上启动zkfc
sbin/hadoop-daemon.sh start zkfc
6.启动namenode
在191上启动namenode
sbin/hadoop-daemon.sh start namenode
7.格式化secondarynamenode
在193上格式化namenode
bin/hdfs namenode -bootstrapStandby
8.启动secondarynamenode
在193上启动namenode
sbin/hadoop-daemon.sh start namenode
9.验证是否成功
1、191和193上的命令行输入jps命令,有namenode进程
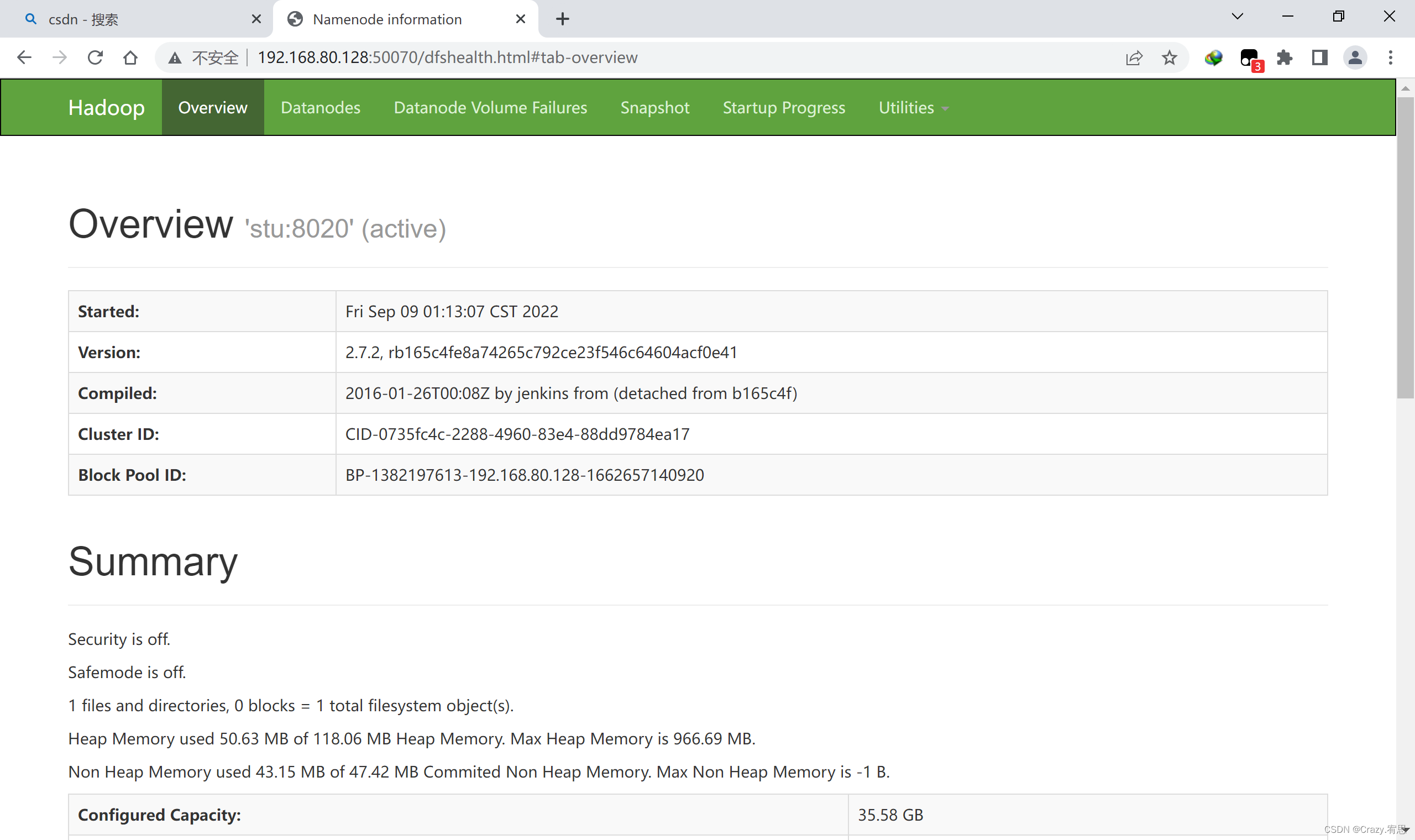
2、网页端口查看:
10.192.8.191:50070和10.192.8.193:50070
一个是standby和一个active
10.启动datanode
所有机器启动datanode
sbin/hadoop-daemon.sh start datanode
11.启动resourcemanager
192和193上启动resourcemanager
sbin/yarn-daemon.sh start resourcemanager
12.启动nodemanager
所有机器启动nodemanager
sbin/yarn-daemon.sh start nodemanager
五、各个机器命令进程
1、10.192.8.191进程如下:

2、10.192.8.192进程如下:

3、10.192.8.193进程如下:

4、10.192.8.194进程如下:

5、10.192.8.195进程如下:

六、网页端口效果
1、namenode
1、10.192.8.191网页

2、10.192.8.193网页

resourcemanager
1、10.192.8.192

2、10.192.8.193
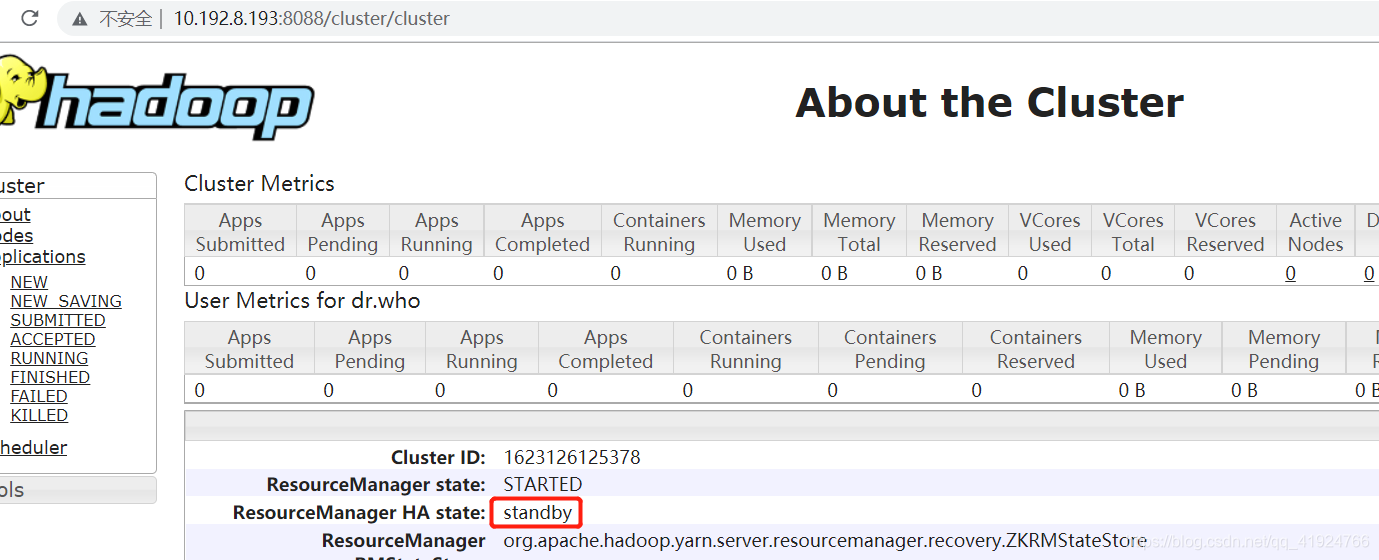
七、高可用测试
命令行kill -9 active状态的NN或者RN
查看另一个NN或者RN是否变成active
总结
到此hadoop集群也就搭建完成了,觉得写得可以的小伙伴可以点个赞,网盘大数据所需软件,需要的找前面链接下载哦。