目录
前言1:
前言2:
一,基础环境
1,三台Centos7.5,一台master,两台slave1和slave2
2,IP配置
3,改主机名
4,配三台主机映射
5,三台主机时钟同步
6,三个节点关防火墙,并开机禁用
7,三台主机互相免密登录
二,Hadoop大数据集群部署
步骤一
步骤二
步骤三
步骤四
步骤五
步骤六
步骤七
三,Hadoop大数据分布式集群的配置
步骤一
步骤二
步骤三
步骤四
步骤五
步骤六
步骤七
步骤八
四,主从节点文件的分发
步骤一
步骤二
步骤三
五,Hadoop集群的启动
1,元数据的格式化
2,组件的启动
3,使用网页形式查看
后言
———————————————————————————————————————————
前言1:
推荐用MobaXterm_20.0这个软件去远程连接你的虚拟机,个人感觉这个是挺好用的,特别是它的那个交互同步执行(以下简称多执行),简直好用到爆,做好的事都很方便,熟练使用可节省不少时间,可以点击下面下载汉化版的,谁用谁知道,简直不要太香。
我试了试给大家在这里粘贴链接会推荐受影响使用大家可以去我发布的资源里下载MobaXterm_20.0汉化:
前言2:
下面的命令,如果不知道在哪个节点敲的,统一声明一下代码前没有标注的都事master节点,slave1和slave2节点的我都在代码前标注了,另外,以下每段代码,我都附上了成功后的截图,以供大家搭建参考。
一,基础环境
1,三台Centos7.5,一台master,两台slave1和slave2

2,IP配置
ip a

ip a

ip a 3,改主机名
3,改主机名
hostnamectl set-hostname master && bash
hostnamectl set-hostname slave1 && bash
hostnamectl set-hostname slave2 && bash

4,配三台主机映射
注:这里就可以用这个远程软件提供的多执行窗口,简单快捷,谁用谁知道,太香了。
vi /etc/hosts192.168.100.80 master
192.168.100.90 slave1
192.168.100.100 slave2
5,三台主机时钟同步
注:如果你是克隆的话这一步就可以不做,就像我的这个一样直接略过,也可以按如下配置。
可以用远程软件的交互执行同时操作以完成
三个节点同时敲(用多执行窗口)
yum install ntpdate -y
ntpdate ntp1.aliyun.com
date
6,三个节点关防火墙,并开机禁用
用多执行窗口
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
7,三台主机互相免密登录
注:这里需要三个节点先去创建一个hadoop的用户,并设置密码,然后使用hadoop用户去做免密,因为后边好多操作都是以hadoop用户的身份实现的。
用多执行窗口
useradd hadoop
passwd hadoop
000000
000000
su hadoop
ssh-keygen(一路回车)
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
ssh slave1
exit
自此基础环境配置完毕。就问你这个功能香不香!!!
二,Hadoop大数据集群部署
步骤一
在master中,创建两个目录,一个/opt/software/存放软件,一个/usr/local/src/安装软件
mkdir /opt/software
mkdir /usr/local/src/
步骤二
将jdk和hadoop的压缩包上传到/opt/software目录下,可以从我发布的资源里下载到两个压缩包,这里就不贴链接了,直接上传即可。
步骤三
上传完成后,解压到/usr/local/src/hadoop和/usr/local/src/jdk下,并通过mv命令改名,使其简单明了
tar -zxvf /opt/software/hadoop-2.7.1.tar.gz -C /usr/local/src/
mv /usr/local/src/hadoop-2.7.1 /usr/local/src/hadoop
tar -zxvf /opt/software/jdk-8u152-linux-x64.tar.gz -C /usr/local/src
mv /usr/local/src/jdk1.8.0_152/ /usr/local/src/jdk
步骤四
并修改所属用户和组确保可为hadoop用户所用
chown -R hadoop:hadoop /usr/local/src/hadoop
chown -R hadoop:hadoop /usr/local/src/jdk
步骤五
配置环境变量使jdk和hadoop生效
vi /etc/profileexport JAVA_HOME=/usr/local/src/jdk export JRE HOME=/usr/local/src/jdk/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/Lib:$JRE_HOME/Lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
步骤六
使环境变量生效
source /etc/profile步骤七
检测jdk和hadoop是否安装成功
java -version
hadoop version

三,Hadoop大数据分布式集群的配置
注:上面我们在master节点装好了jdk和hadoop,可是我们的另外两个从节点也需要jdk和hadoop,所以我们要分发到两个从节点,在此之前需要先做如下配置。
步骤一
修改文件
cd /usr/local/src/hadoop/etc/hadoopvi core-site.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:/usr/local/src/hadoop/tmp</value></property>
</configuration>

步骤二
修改文件
vi hadoop-env.shexport JAVA_HOME=/usr/local/src/java
export HADOOP_PERFIX=/usr/local/src/hadoop
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PERFIX/lib:$HADOOP_PERFIX/lib/natice"

步骤三
修改文件
vi hdfs-site.xml<configuration><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/src/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/src/hadoop/dfs/data</value></property><property><name>dfs.replication</name> <value>3</value> </property>
</configuration>

步骤四
修改文件
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property>
</configuration>

步骤五
修改文件
vi yarn-site.xml<configuration><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property>
</configuration>

步骤六
修改文件
vi mastersmaster
步骤七
修改文件
vi slavesslave1
slave2

步骤八
创建目录
mkdir -p /usr/local/src/hadoop/dfs/name
mkdir -p /usr/local/src/hadoop/dfs/data
mkdir -p /usr/local/src/hadoop/tmp

自此,分布式集群的配置完成
四,主从节点文件的分发
步骤一
分发hadoop目录,改所属用户和组
scp -r /usr/local/src/ root@slave1:/usr/local/src/
scp -r /usr/local/src/ root@slave2:/usr/local/src/
slave1和slave2
chown -R hadoop:hadoop /usr/local/src

步骤二
分发环境变量,并生效
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/slave1和slave2 节点
source /etc/profile步骤三
多窗口执行,检测每个节点是否成功
java -version
hadoop version每个节点都一样,才是成功。
五,Hadoop集群的启动
1,元数据的格式化
多执行窗口
su hadoop
source /etc/profilemaster节点
hdfs namenode -format
2,组件的启动
master节点
start-all.sh多窗口执行
jps
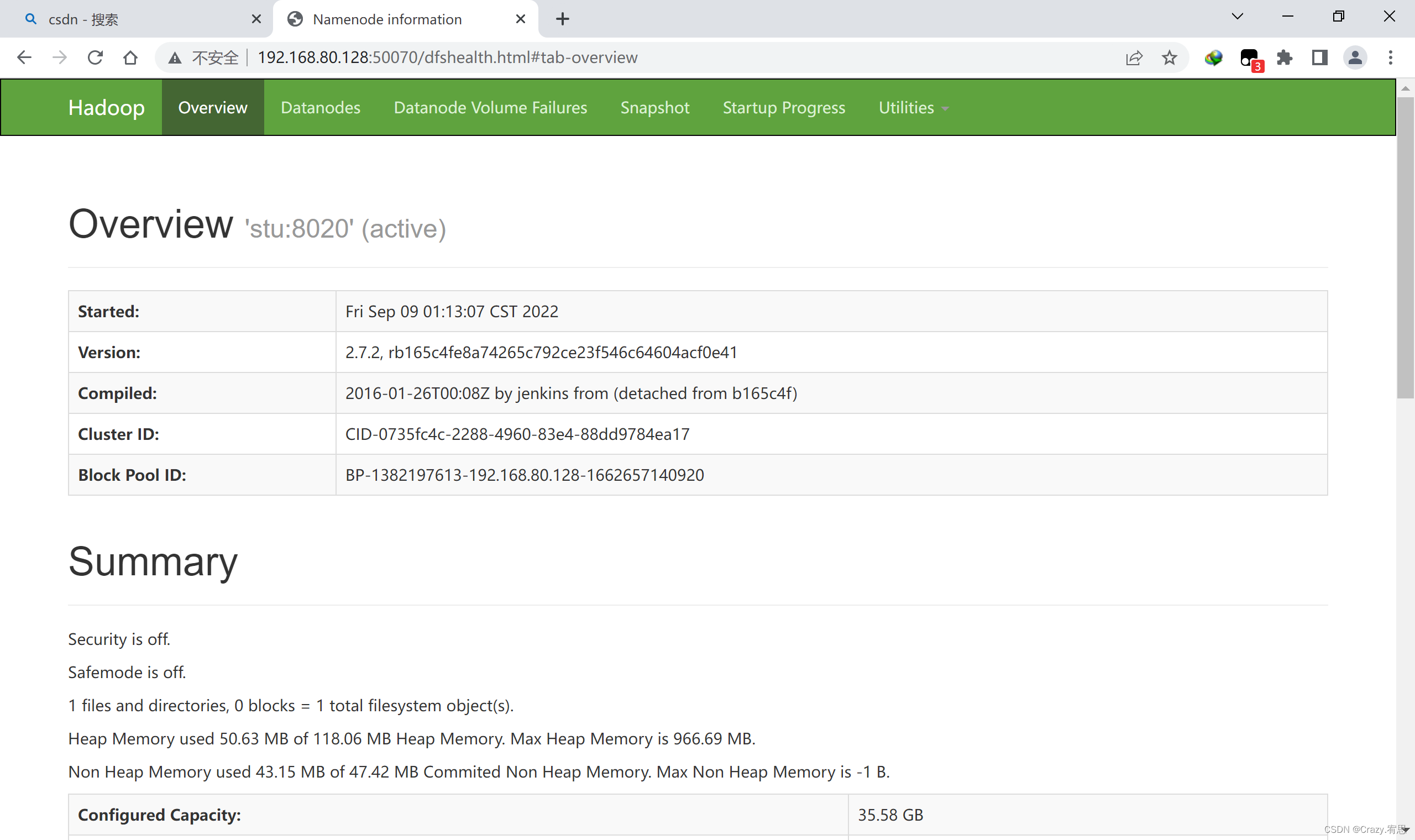
3,使用网页形式查看
192.168.100.80:50070
192.168.100.80:8088
192.168.100.80:9000
后言
自此,一个Hadoop分布式大数据平台搭建完成,感谢观看,欢迎点赞,评论,提问,转发,不足之处,还请多多指教。