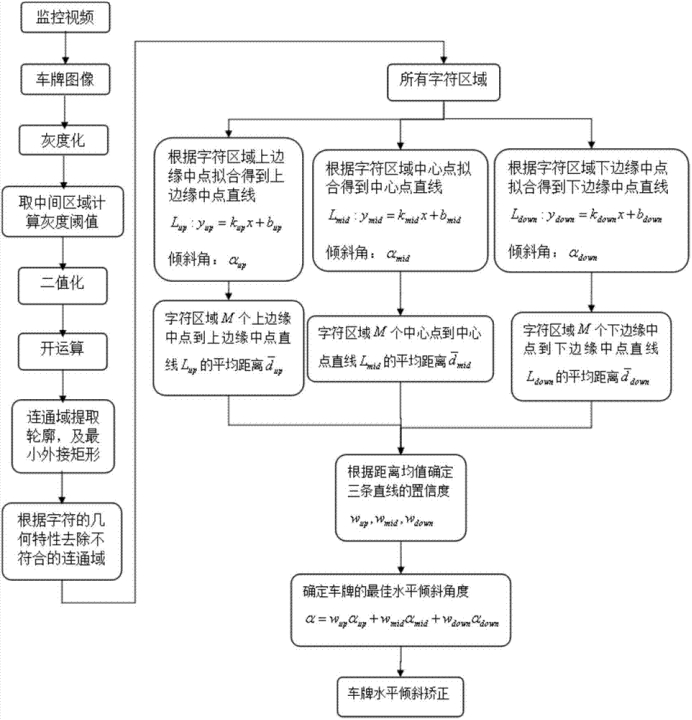
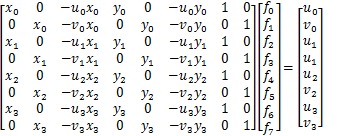【XLPNet车牌识别算法】第二章 检测部分-算法篇1
- 1. XLPNet检测算法前言
- 2. XLPNet检测算法详解
- 2.1 起源
- 2.2 算法细节
- 2.1 算法命名
- 2.2 数据集
- 2.3 预备知识
- 2.4 核心:旋转高斯分布(Rotated Gaussian Distribution)
- 2.4.1 基于高斯策略的样本分配
- 2.4.2 高斯置信度预测
- 2.4.3 高斯NMS
- 2.5 网络结构
- 2.5.1 Backbone
- 2.5.2 Neck
- 2.5.3 Head

NOTICE!
NOTICE!
NOTICE!
现已开源!
开源github地址:https://github.com/JackEasson/XLPNet_for_ALPR
1. XLPNet检测算法前言
- 第一章序言中我已经提到,对于车牌检测任务而言,采用角点(corners)定位的形式要比传统的边界框(bounding boxes)形式更加的精确。实验中出现,其中边界框的宽与高回归难度更大;
- 检测算法上一个自然的联想是:角点检测 → \rightarrow → 关键点回归 → \rightarrow → Anchor-free检测策略;
- 为进一步轻量化模型,采用单特征图检测策略,即单检测头(Detection Head)策略,有别于主流的检测算法,如Yolo系列,SSD,RetinaNet,FCOS等;
- 二维高斯分布是整个XLPNet检测算法的核心。
2. XLPNet检测算法详解
2.1 起源
- Anchor-free +单检测头 + 高斯,很容易就想到了经典的检测算法:CenterNet,结构简洁、后处理NMS-free、运行高效,确实叫人赏心悦目。因此CenterNet算是XLPNet检测算法最初的想法来源;
- 在我的一篇会议论文《SLPNet: Towards End-to-End Car License Plate Detection and Recognition Using Lightweight CNN》(文章链接)中,首先结合Anchor-free +单检测头 + 高斯策略,提出了一套检测算法,XLPNet检测算法即是在其基础上进行了改进提升。
论文中SLPNet结构:

实际上,XLPNet结构与SLPNet类似,同样是车牌检测 → \rightarrow → 车牌区域映射 → \rightarrow → 透视变换 → \rightarrow → 车牌无分割识别。
2.2 算法细节
2.1 算法命名
因为是基于角点进行车牌的检测任务,因此为了指称方便,将XLPNet检测算法命名为:CornerLPDetection,简称CLPD。
2.2 数据集
为方便起见,数据集直接采用国内最大的开源车牌数据集:CCPD数据集(CCPD2019为蓝牌,CCPD2020为能源车牌,本项目仅采用CCPD2019进行了实验)。
相关介绍性博客:链接
论文和数据集下载地址:链接
其中已经对车牌的各个角点都进行了标注,以一张图片为例:

名称:02-10_16-292&475_466&571-460&539_292&571_298&507_466&475-0_0_14_6_30_25_29-55-22,以-进行分割,第三项460&539_292&571_298&507_466&475即是角点信息,对应的4个角点顺序是:右下 - 左下 - 左上 - 右上,即从右下角点开始,顺时针排列。
2.3 预备知识
熟悉的朋友请跳过~
-
关于anchor-free检测算法:链接
这里我以FoveaBox论文中的图为例:

FoveaBox作为通用Anchor-free目标检测算法,输出特征图中栅格中心点作为关键点,其中被划分为正样本的,负责回归对象的左上角和右下角角点,而本文CLPD回归车牌的四个角点,基本算法流程一致。 -
关于特征金字塔网络FPN:链接

本文CLPD算法虽然只使用一个检测头,即只使用一个输出特征图来检测车牌对象,但为了引入不同阶段、不同尺度的信息,利用了FPN为了进行了特征融合。
2.4 核心:旋转高斯分布(Rotated Gaussian Distribution)
-
二维高斯分布大家可以重温一下:博客链接
f ( X ) = 1 2 π ∣ Σ ∣ 1 / 2 e x p [ − 1 2 ( X − u ) T Σ − 1 ( X − u ) ] , X = ( x , y ) f(X)=\frac{1}{2\pi\vert \Sigma\vert^{1/2}}exp[-\frac1 2 (X-u)^T\Sigma^{-1}(X-u)],X=(x,y) f(X)=2π∣Σ∣1/21exp[−21(X−u)TΣ−1(X−u)],X=(x,y)
公式中,最重要的一个参数即是协方差矩阵 Σ \Sigma Σ,其控制了二维高斯分布的形状。 -
旋转高斯,亦即协方差矩阵并非一个简单的对角矩阵,那么如何将高斯分布的旋转角度和协方差矩阵联系起来呢?下面这篇博客(链接)从线性变换的角度探讨了高斯分布协方差阵 Σ \Sigma Σ的意义:

这里的 Q T Q^T QT即是我们熟知的旋转矩阵:
[ c o s θ − s i n θ s i n θ c o s θ ] \begin{bmatrix} cos\theta & -sin\theta \\ sin\theta & cos\theta\\ \end{bmatrix} [cosθsinθ−sinθcosθ]
此外,这里的 D D D中的两个值可以认为用来控制旋转后的高斯分布进行横向和纵向开口大小(放缩比例)。
2.4.1 基于高斯策略的样本分配
前言:
检测算法中的正负样本分配即是要对一个Ground Truth(GT)依据预定规则设定正样本、负样本(有些算法如FoveaBox还会引入忽略样本),正样本要负责对象位置的回归,负样本和忽略样本则不需要。而对于对象置信度的回归,则负样本期望值为0,正样本期望值为预测位置的实际得分,忽略样本则不做监督。
目前的anchor-free样本分配策略有:
-
FCOS式:其中GT内部所有关键点作为关键点

-
FoveaBox式:收缩GT边界框,小框内部为正样本,小框和中间框之间为忽略样本,其他为负样本

实验证明,CLPD作为轻量化的anchor-free检测算法,采用FoveaBox式样本分配策略,人为设定忽略样本将一定程度上影响回归效果,造成训练时的不稳定,因此选择基于FCOS式策略加以改进
首先有以下两点考虑:
- 车牌的四个角点信息构成一个四边形,往往带有一些旋转、错切等特性(简而言之就是透视效果),因此直接选择GT内部的关键点作为正样本,不能很好体现空间分布信息;
- 此外,GT内部全作为等价的正样本也有改进余地,引入权重思想,我们往往认为越中心的关键点越能获得更加全面的特征信息,所以中心处的关键点权重应该更大(思路来源:《Soft Anchor-Point Object Detection》相关博客链接);

因此,为契合任意四边形的形状、按分布配权的思想,CLPD算法引入了二维高斯分布,注意这里是具有旋转、放缩特性的一般化的归一化二维高斯分布。
下面以图举例CLPD中的基于高斯分布的样本分配策略:

- 图a中用绿色框出了四个角点组成的四边形,红色为四边形的最小外接矩形
最小外接矩形的参数采用opencv函数cv2.minAreaRect()来获取,输入参数为四个角点的集合矩阵,np.ndarray,size(4, 2),得到一个列表,包含最小外接矩形的中心点、宽高、旋转角度:

解析列表时把角度值转换为弧度制,方便后续旋转矩阵的计算。 - 利用外接矩形的旋转角度、宽度、高度计算出二维高斯高斯中的协方差矩阵:
Σ = R Λ R T \Sigma=R\Lambda R^{T} Σ=RΛRT
其中R为旋转矩阵:
R = [ c o s θ − s i n θ s i n θ c o s θ ] R=\begin{bmatrix} cos\theta & -sin\theta \\ sin\theta & cos\theta\\ \end{bmatrix} R=[cosθsinθ−sinθcosθ]
Λ \Lambda Λ为对角矩阵,这里简单地设定为:
Λ = [ w ∗ r 0 0 h ∗ r ] \Lambda=\begin{bmatrix} w*r & 0 \\ 0 & h*r\\ \end{bmatrix} Λ=[w∗r00h∗r]
其中 r r r为缩放比例,在样本分配时 r r r取1。
注意这里采用的是归一化的二维高斯:
f ( X ) = e x p [ − 1 2 ( X − u ) T Σ − 1 ( X − u ) ] , X = ( x , y ) , u = ( c x , c y ) f(X)=exp[-\frac1 2 (X-u)^T\Sigma^{-1}(X-u)],X=(x,y),u=(cx, cy) f(X)=exp[−21(X−u)TΣ−1(X−u)],X=(x,y),u=(cx,cy)
其中 X = ( x , y ) X=(x,y) X=(x,y)表示预测特征图每个栅格中心(即关键点)的坐标, u = ( c x , c y ) u=(cx, cy) u=(cx,cy)表示上面计算出的最小外接矩形的中心点。
- 计算每个栅格中心点位置在归一化高斯分布中的函数值(高斯得分),即得到图b中展示的结果,为方便显示,(0, 1)的数值已经被映射到(0, 255);
- 这里为限制正样本数量,仅取高斯得分 ≥ \geq ≥ 0.6的关键点做为正样本,其他作为负样本;
- 若一个关键点同时对于多个GT计算出的高斯得分都大于等于0.6,则判定为忽略样本,训练中不做监督。
- 图c中展示的白色区域即是正样本区域,此外每个位置都有一个(0, 1)范围的高斯得分,这个得分命名为高斯权重,后续计算损失时将用以不同样本的配权。
2.4.2 高斯置信度预测
通用目标检测算法中一般会输出两类置信度:分类置信度和定位置信度,本XLPNet算法中因为仅有一类车牌目标需要检测,因此可以直接忽略分类置信度,仅采用定位置信度( C o n f Conf Conf)即可。定位置信度指示了当前预测框的质量好坏,判断一个对象是前景还是背景时,可以直接设定一个阈值 T T T来筛选,认为 C o n f ≥ T Conf\geq T Conf≥T的是前景,否则为背景。而这里的定位置信度在训练时往往就是采用当前预测框与GT真实框的IoU作为标签的,但是咱的CLPD算法回归的是四个角点啊,IoU该如何计算呢?
这里为方便起见,仍然借助归一化的二维高斯分布来解决!
这里我们借助之前得到的GT的最小外接矩形的宽、高、角度等信息,分别以4个角点为中心构建4个相同尺寸、不同位置的归一化高斯分布!

上图展示了其中一个角点上的高斯得分的分布,那么现在我们得到的预测角点就可以对应高斯分布得到一个定位质量的分数,此即为一个角点的定位置信度。
最后:
- CLPD会输出4个角点的置信度得分,亦即置信度网络分支输出的特征图通道数为4。
- 那么最终的预测置信度将一组4个置信度取平均即可。
2.4.3 高斯NMS
看完2.4.2的介绍,这里的非极大值抑制(NMS)就很容易理解了,在主流的框式NMS中将IoU指标替换为高斯置信度得分,即以当前最高置信度的一组预测角点(称为预测四边形)为基准,用上面两小节相同的操作:
- 计算最小外接矩形
- 在4个角点分别生成归一化高斯分布
- 对待抑制的其他预测四边形分别计算每个角点的高斯得分
- 每个预测四边形4个角点高斯得分取平均,得到总的高斯得分
- 大于预设阈值的结果删除掉
- 依次完成后续的抑制过程
最后留下的就是最终我们需要的检测结果了。
2.5 网络结构
2.5.1 Backbone
为契合XLPNet整体轻量化的设计目标,主干网络选用轻量化的卷积网络:EfficientNetv2,当然并非直接使用,而是进行了如下的微调:
- 调整网络的深度和宽度,即每个阶段的网络层数和每层通道数;
- 调整卷积核尺寸,部分kernel size: 3 → \rightarrow → 5;
- 为了方便opencv调用,调整激活函数:SiLU → \rightarrow → HardSwish。
依据上述不同的调整策略,定义了两个不同大小的网络:efficientnetv2_lite和efficientnetv2_s


主干网络选用efficientnetv2为基准来调整,主要是它真的很高效,在运行速度(主要CPU上)和检测精度上可以取得较好的平衡。
此外,CLPD还有PPLCNet和MobileNeXt两个模型可供使用。
2.5.2 Neck
这里以单阶段检测算法OneNet的网络结构作为例子来介绍:

OneNet的Neck部分承自经典的FPN结构,将主干网络输出的四个阶段的特征图逐级向上融合,最终以4倍下采样大小的特征图进行单Detection Head式的检测。
CLPD的Neck部分与OnetNet的区别有以下:
- 采用融合后的8倍下采样特征图进行输出,提升运行速度;
- 上采样使用反卷积+深度可分离卷积(DW)的形式,即在DW中将逐通道卷积部分的常规核换成反卷积核;
- 融合时需要通道的部分,一律使用点卷积(1×1卷积),进一步减少参数量;
- 融合时输出通道数统一到128。
结构细节如下:

2.5.3 Head
从上图已经可以看到最后的Head部分网络分支没有使用解耦头,而是直接联合输出通道数为12(4+8)的预测特征图,其中“4”表4个角点的预测高斯得分,即定位置信度;“8”表示4个角点坐标(x1, y1, x2, y2, x3, y3, x4, y4)。(x1, y1)表示预测的车牌对象的左上角点坐标,其余按顺时针顺序延续。
CLPD的Head具体结构如下:

其中Ghost Module源自GhostNet(链接):

Head部分为提升检测精度,没有直接采用最轻量化的深度可分离卷积,而采用Ghost Module,适当轻量化之余能更好提升检测精度。