HashMap集合: 底层是哈希表/散列表的数据结构
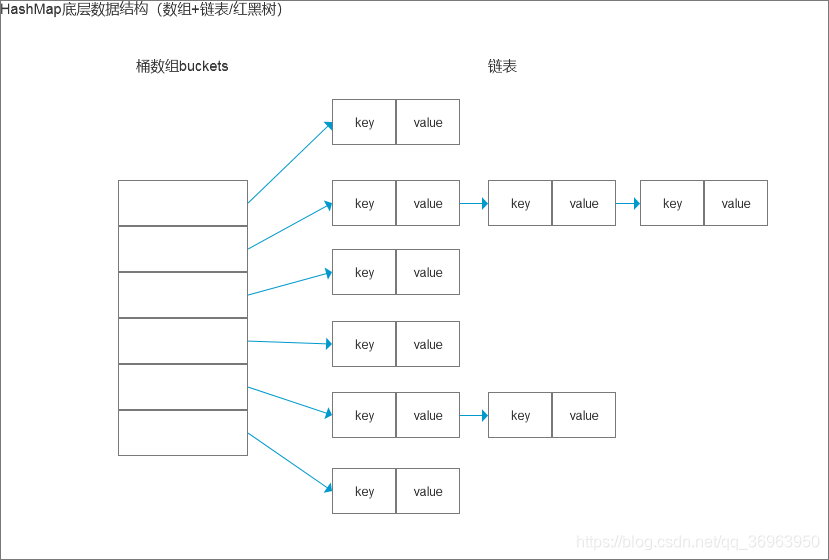
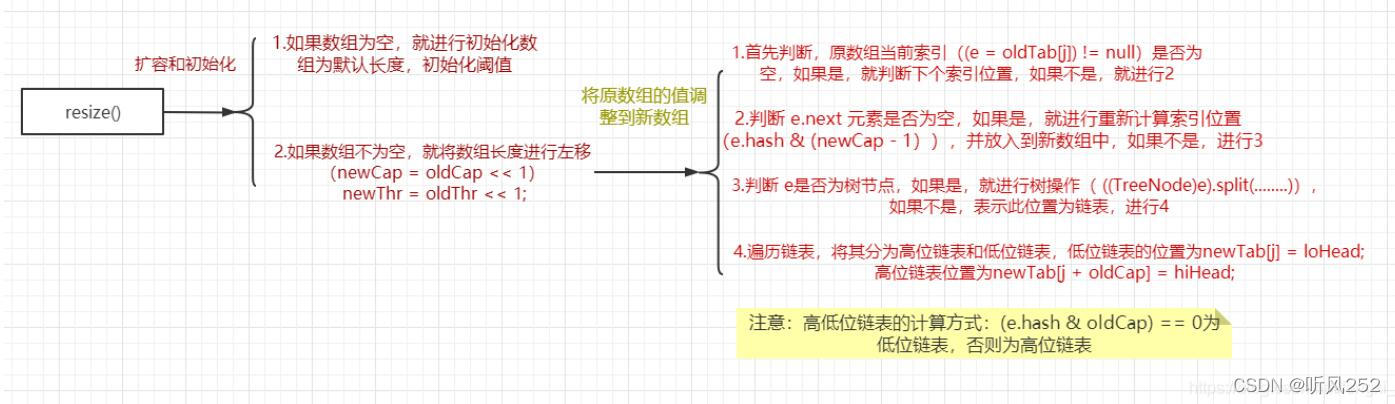
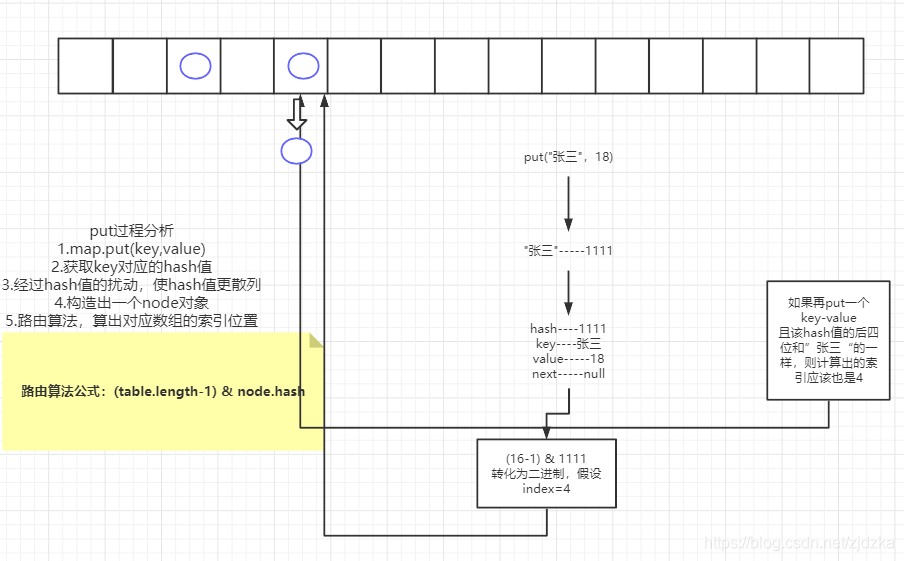
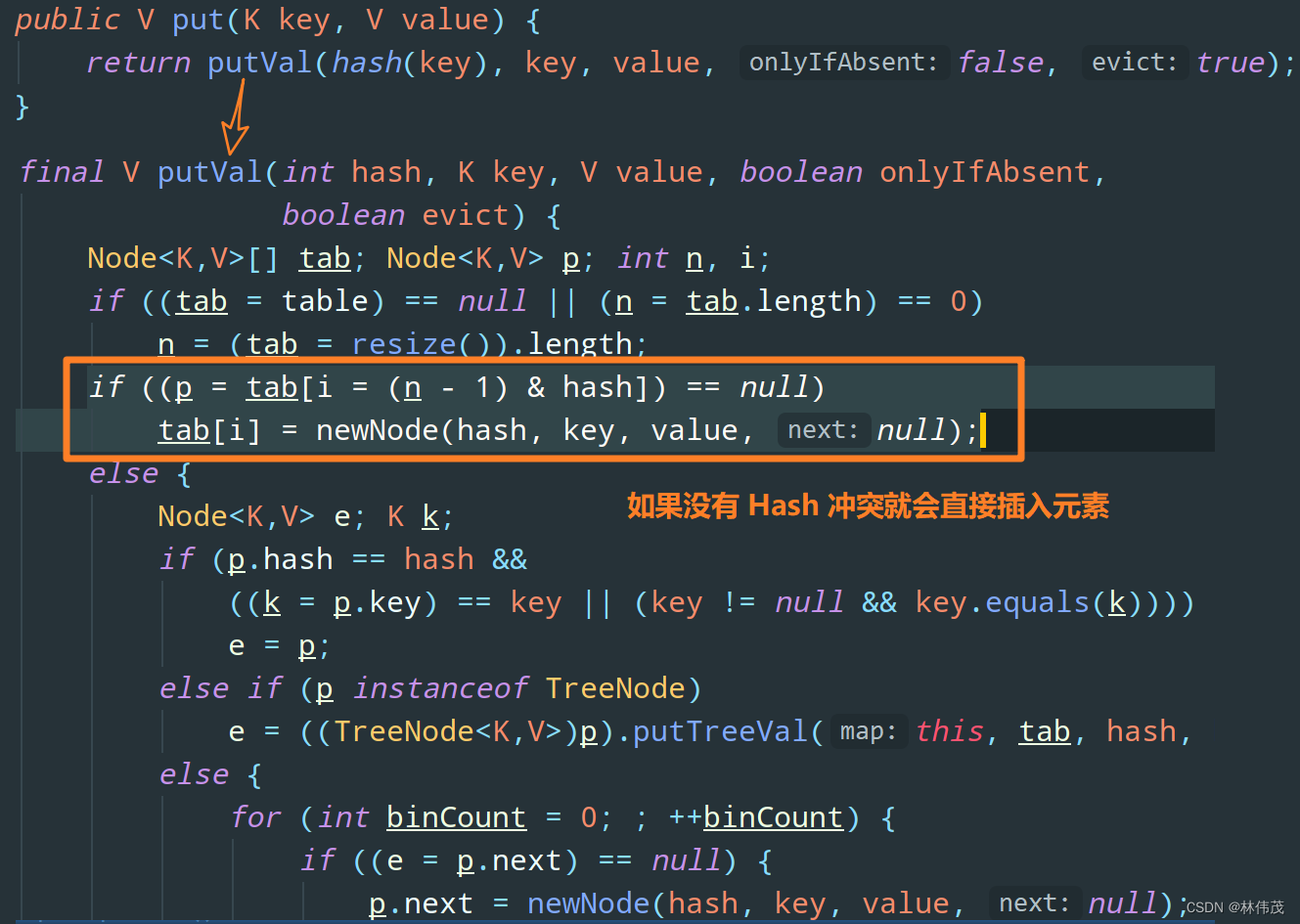
HashMap集合:1、HashMap集合底层是哈希表/散列表的数据结构。2、哈希表是一个怎样的数据结构呢?哈希表是一个数组和单向链表的结合体。数组:在查询方面效率很高,随机增删方面效率很低。单向链表:在随机增删方面效率较高,在查询方面效率很低。哈希表将以上的两种数据结构融合在一起,充分发挥它们各自的优点。3、HashMap集合底层的源代码:public class HashMap{// HashMap底层实际上就是一个数组。(一维数组)Node<K,V>[] table;// 静态的内部类HashMap.Nodestatic class Node<K,V> {final int hash; // 哈希值(哈希值是key的hashCode()方法的执行结果。hash值通过哈希函数/算法,可以转换存储成数组的下标。)final K key; // 存储到Map集合中的那个keyV value; // 存储到Map集合中的那个valueNode<K,V> next; // 下一个节点的内存地址。}}哈希表/散列表:一维数组,这个数组中每一个元素是一个单向链表。(数组和链表的结合体。)4、最主要掌握的是:map.put(k,v)v = map.get(k)以上这两个方法的实现原理,是必须掌握的。5、HashMap集合的key部分特点:无序,不可重复。为什么无序? 因为不一定挂到哪个单向链表上。不可重复是怎么保证的? equals方法来保证HashMap集合的key不可重复。如果key重复了,value会覆盖。放在HashMap集合key部分的元素其实就是放到HashSet集合中了。所以HashSet集合中的元素也需要同时重写hashCode()+equals()方法。6、哈希表HashMap使用不当时无法发挥性能!假设将所有的hashCode()方法返回值固定为某个值,那么会导致底层哈希表变成了纯单向链表。这种情况我们成为:散列分布不均匀。什么是散列分布均匀?假设有100个元素,10个单向链表,那么每个单向链表上有10个节点,这是最好的,是散列分布均匀的。假设将所有的hashCode()方法返回值都设定为不一样的值,可以吗,有什么问题?不行,因为这样的话导致底层哈希表就成为一维数组了,没有链表的概念了。也是散列分布不均匀。散列分布均匀需要你重写hashCode()方法时有一定的技巧。7、重点:放在HashMap集合key部分的元素,以及放在HashSet集合中的元素,需要同时重写hashCode和equals方法。8、HashMap集合的默认初始化容量是16,默认加载因子是0.75这个默认加载因子是当HashMap集合底层数组的容量达到75%的时候,数组开始扩容。/*** The maximum capacity, used if a higher value is implicitly specified* by either of the constructors with arguments.* MUST be a power of two <= 1<<30.*/static final int MAXIMUM_CAPACITY = 1 << 30;重点,记住:HashMap集合初始化容量必须是2的倍数,这也是官方推荐的, 这是因为达到散列均匀,为了提高HashMap集合的存取效率,所必须的。





注意:同一个单向链表上所有的节点hosh相同,因为他们的数组下标是一样的。
但是同一个链表上的K和K的equals方法肯定返回的是false,都不相等 【无序不可重复】
package com.company.map;import java.util.HashMap;
import java.util.Map;
import java.util.Set;public class HashMapTest {public static void main(String[] args) {// 测试HashMap集合key部分的元素特点// Integer是key,它的hashCode和equals都重写了。Map<Integer, String> map = new HashMap<>();map.put(1111, "zhangsan");map.put(6666, "lisi");map.put(7777, "wangwu");map.put(2222, "zhaoliu");map.put(2222, "king"); //key重复的时候value会自动覆盖。System.out.println(map.size()); // 4// 遍历Map集合Set<Map.Entry<Integer, String>> set = map.entrySet();for (Map.Entry<Integer, String> entry : set) {// 验证结果:HashMap集合key部分元素:无序不可重复。System.out.println(entry.getKey() + "=" + entry.getValue());}}
}重写equals一定要重写hashcode:
package com.company.bean;import java.util.Objects;public class Student {private String name;public Student() {}public Student(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}// hashCode// equals(如果学生名字一样,表示同一个学生。)/*public boolean equals(Object obj){if(obj == null || !(obj instanceof Student)) return false;if(obj == this) return true;Student s = (Student)obj;return this.name.equals(s.name);}*/@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name);}}package com.company.bean;import java.util.HashSet;
import java.util.Set;/**
1、向Map集合中存,以及从Map集合中取,都是先调用key的hashCode方法,然后再调用equals方法!
equals方法有可能调用,也有可能不调用。拿put(k,v)举例,什么时候equals不会调用?k.hashCode()方法返回哈希值,哈希值经过哈希算法转换成数组下标。数组下标位置上如果是null,equals不需要执行。拿get(k)举例,什么时候equals不会调用?k.hashCode()方法返回哈希值,哈希值经过哈希算法转换成数组下标。数组下标位置上如果是null,equals不需要执行。2、注意:如果一个类的equals方法重写了,那么hashCode()方法必须重写。
并且equals方法返回如果是true,hashCode()方法返回的值必须一样。equals方法返回true表示两个对象相同,在同一个单向链表上比较。那么对于同一个单向链表上的节点来说,他们的哈希值都是相同的。所以hashCode()方法的返回值也应该相同。3、hashCode()方法和equals()方法不用研究了,直接使用IDEA工具生成,但是这两个方法需要同时生成。4、终极结论:放在HashMap集合key部分的,以及放在HashSet集合中的元素,需要同时重写hashCode方法和equals方法。5、对于哈希表数据结构来说:如果o1和o2的hash值相同,一定是放到同一个单向链表上。当然如果o1和o2的hash值不同,但由于哈希算法执行结束之后转换的数组下标可能相同,此时会发生“哈希碰撞”。*/
public class HashMapTest02 {public static void main(String[] args) {Student s1 = new Student("zhangsan");Student s2 = new Student("zhangsan");// 重写equals方法之前是false//System.out.println(s1.equals(s2)); // false// 重写equals方法之后是trueSystem.out.println(s1.equals(s2)); //true (s1和s2表示相等)System.out.println("s1的hashCode=" + s1.hashCode()); //284720968 (重写hashCode之后-1432604525)System.out.println("s2的hashCode=" + s2.hashCode()); //122883338 (重写hashCode之后-1432604525)// s1.equals(s2)结果已经是true了,表示s1和s2是一样的,相同的,那么往HashSet集合中放的话,// 按说只能放进去1个。(HashSet集合特点:无序不可重复)Set<Student> students = new HashSet<>();students.add(s1);students.add(s2);System.out.println(students.size()); // 这个结果按说应该是1. 但是结果是2.显然不符合HashSet集合存储特点。怎么办?}
}JDK1.8后
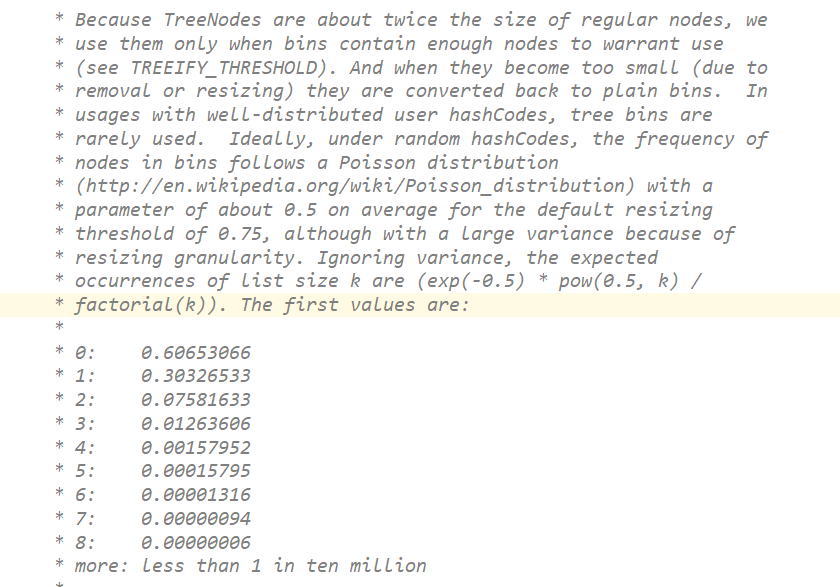
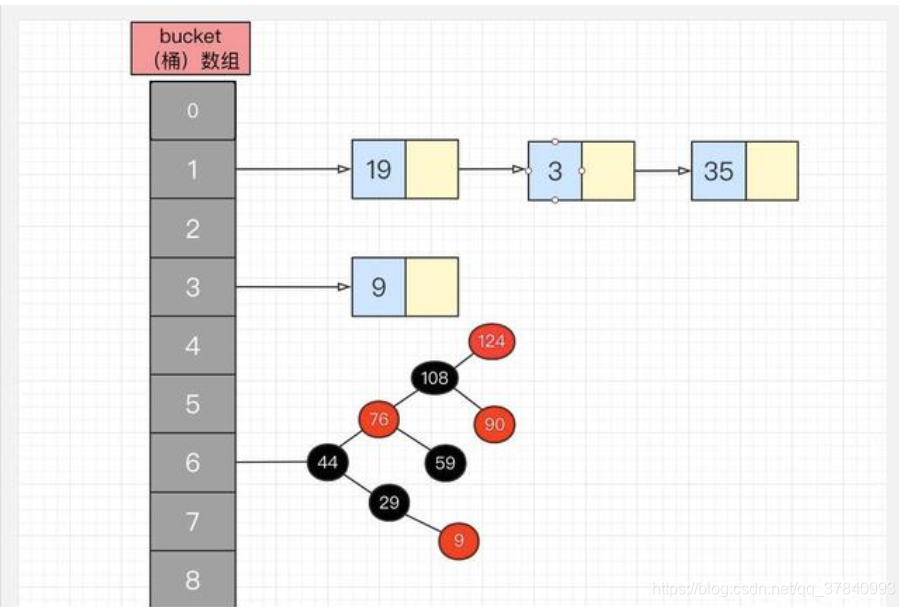
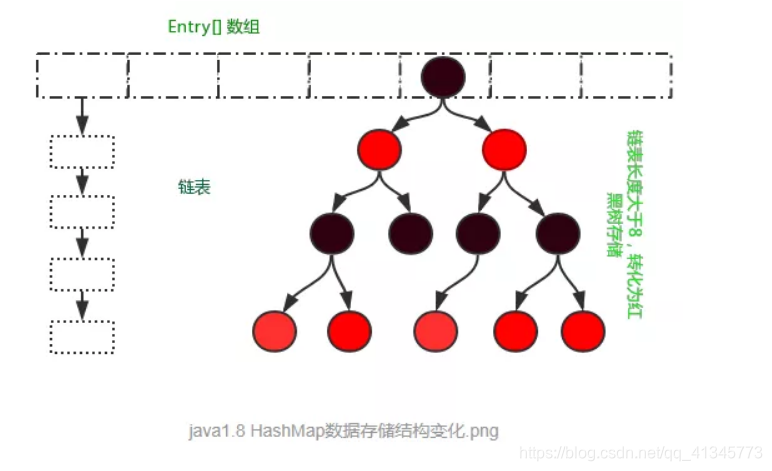
jdk1.8后HashMap中,如果哈希表单向链表中元素超过
8个,单向链表会变成红黑树数据结构,当红黑树上的节点小于6时,会重新把红黑树变成单向链表数据结构
/*** The bin count threshold for using a tree rather than list for a* bin. Bins are converted to trees when adding an element to a* bin with at least this many nodes. The value must be greater* than 2 and should be at least 8 to mesh with assumptions in* tree removal about conversion back to plain bins upon* shrinkage.*/
static final int TREEIFY_THRESHOLD = 8;/*** The bin count threshold for untreeifying a (split) bin during a* resize operation. Should be less than TREEIFY_THRESHOLD, and at* most 6 to mesh with shrinkage detection under removal.*/
static final int UNTREEIFY_THRESHOLD = 6;
红黑树: