文档是从自己的云笔记中复制,格式什么的可能有问题.已修复了一遍.
零.前提
一.安装hadoop
1.1下载并复制hadoop2.6.5
1.2编辑系统配置文件
1.3创建hadoop的tmp临时目录
1.4开始修改配置文件
1.5复制hadoop到其他所有节点上
1.6开始初始化hadoop
1.7 如果服务器重启了,开机时程序的启动顺序
二.安装HAWQ
2.1降低hdfs根目录权限限制
2.2修改系统配置,在所有节点上执行
2.3新建账户postgres,在所有节点上执行
2.4下载安装HAWQ,在所有节点上执行
2.5编辑hawq配置文件,在所有节点上执行
2.6初始化环境变量,在所有节点上执行
2.7设置免密输入,在所有节点上执行
2.8设置hawq关联hadoop ha,在所有节点上执行
2.9建立配套的文件夹,在所有节点上执行
2.10初始化,在server23上执行
2.11建立管理员用户,在server23上执行
2.12添加并初始化standby冗余主节点,在server23上执行
2.13修改访问权限,在server23,server24上执行
附录
安装WAHQ
| 表格内的内容是在xshell里执行 |
红色字体的地方都是需要注意的地方
零.前提
所有服务器都已安装好jdk和zookepper,都已启动,这里安装过程不再阐述
zookeeper-3.5.7
jdk1.8.0_211
一.安装hadoop
| 服务器名\hadoop服务 | NameNode (HA) | DataNode | JournalNode | ResourceManager (HA) | NodeManager |
| server23 (master) | √ | √ | √ | √ | √ |
| server24 (slave) | √ | √ | √ | √ | √ |
| server25 (slave) | √ | √ | √ |
1.1下载并复制hadoop2.6.5
https://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
拷贝hadoop-2.6.5.tar.gz到服务器的/opt下,此次安装例子放在server23上
执行
| cd /opt tar -xzvf hadoop-2.6.5.tar.gz |
1.2编辑系统配置文件
| vim /etc/profile |
添加HADOOP_HOME行并修改PATH行
| export HADOOP_HOME=/opt/hadoop-2.6.5 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH |
配置生效
| source /etc/profile |
验证安装是否成功
| hadoop version |
显示如下为正常

1.3创建hadoop的tmp临时目录
| mkdir -p /opt/hadoopData/tmp mkdir -p /opt/hadoopData/namenode mkdir -p /opt/hadoopData/datanode mkdir -p /opt/hadoopData/journalnode |
1.4开始修改配置文件
| cd /opt/hadoop-2.6.5/etc/hadoop/ |
修改core-site.xml文件,红色字体需要修改和现场一致
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://namenodeCluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoopData/tmp</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>server23:2181,server24:2181,server25:2181</value> </property> <property> <name>ha.zookeeper.session-timeoutms</name> <value>2000</value> </property> </configuration> |
修改hdfs-site.xml文件,红色字体需要修改和现场一致
| <configuration> <property> <name>dfs.nameservices</name> <value>namenodeCluster</value> </property> <!-- NameServer下有nn1,nn2 --> <property> <name>dfs.ha.namenodes.namenodeCluster</name> <value>n1,n2</value> </property> <property> <name>dfs.namenode.rpc-address.namenodeCluster.n1</name> <value>server23:9000</value> </property> <property> <name>dfs.namenode.http-address.namenodeCluster.n1</name> <value>server23:50070</value> </property> <property> <name>dfs.namenode.rpc-address.namenodeCluster.n2</name> <value>server24:9000</value> </property> <property> <name>dfs.namenode.http-address.namenodeCluster.n2</name> <value>server24:50070</value> </property> <!-- 指定NameNode的元素局在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://server23:8485;server24:8485;server25:8485/namenodeCluster</value> </property> <!-- 指定JournalNode在本地的存放位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoopData/journalnode</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.namenodeCluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制,多个机制用换行分割,即每个机制暂用一行 --> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免密码登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoopData/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoopData/datanode</value> </property> </configuration> |
修改yarn-site.xml文件,红色字体需要修改和现场一致
分配给node单个容器可申请的最小内存
分配给node单个容器可申请的最小CPU核数
需要和总内存和总核数进行计算,尽量成倍数
| <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>5120</value> </property> <!--启用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--声明两台resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>server23</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>server24</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>server23:2181,server24:2181,server25:2181</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的状态信息存储在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property>
<property> <name>yarn.resourcemanager.address.rm1</name> <value>server23:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>server23:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>server23:8031</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>server24:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>server24:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>server24:8031</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> <!--分配给node单个容器可申请的最小内存 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2560</value> </property> <!--分配给node单个容器可申请的最小CPU核数 --> <property> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>2</value> </property> </configuration> |
修改hadoop环境变量
| vim /opt/hadoop-2.6.5/etc/hadoop/hadoop-env.sh |
修改JAVA_HOME为
| export JAVA_HOME=/opt/jdk1.8.0_211 |
修改yarn环境变量
| vim /opt/hadoop-2.6.5/etc/hadoop/yarn-env.sh |
修改JAVA_HOME为,jdk路径和自己的一致
| if [ "$JAVA_HOME" != "" ]; then #echo "run java in $JAVA_HOME" JAVA_HOME=/opt/jdk1.8.0_211 fi |
1.5复制hadoop到其他所有节点上
| scp -r /opt/hadoop-2.6.5 root@server25:/opt/ scp -r /opt/hadoop-2.6.5 root@server26:/opt/ |
在其他所有节点上执行1.3和1.4 步骤
1.6开始初始化hadoop
创建命名空间,在master节点(server23)上运行,结果如图
| hdfs zkfc -formatZK |

启动journalnode,所有服务器执行
| sh /opt/hadoop-2.6.5/sbin/hadoop-daemon.sh start journalnode |
格式化主NameNode节点,在master节点(server23)上运行,结果如图
| hadoop namenode -format |

启动主NameNode节点,在master节点(server23)上运行
| sh /opt/hadoop-2.6.5/sbin/hadoop-daemon.sh start namenode |
格式化备NameNode节点,在slave节点(server24)上运行
| hdfs namenode -bootstrapStandby |
启动备NameNode节点,在slave节点(server24)上运行
| sh /opt/hadoop-2.6.5/sbin/hadoop-daemon.sh start namenode |
在主备NameNode节点启动ZKFC,在master节点(server23),slave节点(server24)上运行
| sh /opt/hadoop-2.6.5/sbin/hadoop-daemon.sh start zkfc |
启动所有DataNode节点,所有节点上执行
| sh /opt/hadoop-2.6.5/sbin/hadoop-daemon.sh start datanode |
在两个yarn的rm服务器上启动yarn,在master节点(server23),slave节点(server24)上运行
| sh /opt/hadoop-2.6.5/sbin/start-yarn.sh |
完毕,hadoop集群已全部安装完毕,服务已全部启动,你现在拥有一套双namenode,双ResourceManager备份的集群,支持掉线自动切换
1.7 如果服务器重启了,开机时程序的启动顺序
a)所有节点启动zookepper
| sh /opt/zookeeper-3.5.7/bin/zkServer.sh start |
b)主节点启动,在server23上
| sh /opt/hadoop-2.6.5/sbin/start-all.sh |
c)启动备份YARN的RM,在server24上
| sh /opt/hadoop-2.6.5/sbin/start-yarn.sh |
-------------------------------------------------hadoop安装完毕-------------------------------------------------
二.安装HAWQ
此次例子安排配置,在hadoop的基础上,master节点和stanby节点安装在namenode所在的服务器上
| 服务器名\HAWQ服务 | hawq_master 主节点 | hawq_standby 冗余主节点 | hawq_segment 数据节点 |
| server23 (主) | √ | √ | |
| server24 (从) | √ | √ | |
| server25 | √ |
2.1降低hdfs根目录权限限制
为了hawq的gpadmin用户可在hdfs建立初始化目录,任意节点执行
| hadoop fs -chmod 777 / |
2.2修改系统配置,在所有节点上执行
| vim /etc/sysctl.conf |
添加
| #系统最大线程数 kernel.threads-max=798720 #内核允许分配超过所有物理内存和交换空间总和的内存 vm.overcommit_memory=2 vm.overcommit_ratio=50
kernel.shmmax = 1000000000 kernel.shmmni = 4096 kernel.shmall = 4000000000 kernel.sem = 250 512000 100 2048 kernel.sysrq = 1 kernel.core_uses_pid = 1 kernel.msgmnb = 65536 kernel.msgmax = 65536 kernel.msgmni = 2048 net.ipv4.tcp_syncookies = 0 net.ipv4.conf.default.accept_source_route = 0 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_max_syn_backlog = 200000 net.ipv4.conf.all.arp_filter = 1 net.ipv4.ip_local_port_range = 1281 65535 net.core.netdev_max_backlog = 200000 vm.overcommit_memory = 2 fs.nr_open = 3000000 kernel.threads-max = 798720 kernel.pid_max = 798720 net.core.rmem_max = 2097152 net.core.wmem_max = 2097152 |
刷新配置
| sysctl -p |
修改文件打开数
| vim /etc/security/limits.conf |
添加
| * soft nofile 2900000 * hard nofile 2900000 * soft nproc 131072 * hard nproc 131072 |
退出xshell连接,重新登录
2.3新建账户postgres,在所有节点上执行
输入密码 postgres,加入这个用户是为了数据库登录权限
| useradd postgres passwd postgres |
2.4下载安装HAWQ,在所有节点上执行
https://mirrors.tuna.tsinghua.edu.cn/apache/hawq/2.4.0.0/apache-hawq-rpm-2.4.0.0.tar.gz
拷贝apache-hawq-rpm-2.4.0.0.tar.gz到服务器的/opt下
执行
| cd /opt tar -xzvf apache-hawq-rpm-2.4.0.0.tar.gz |
复制instalPackage文件夹的内容到/opt/hawq_rpm_packages/下
| cd /opt/hawq_rpm_packages/ |
注意:我的安装环境是centos7.3,这里还会差一些包,自己下载
执行安装
| rpm -ivh libntlm-1.3-6.el7.x86_64.rpm rpm -ivh libgsasl-1.8.0-0.99.el6.x86_64.rpm rpm -ivh protobuf-2.5.0-8.el7.x86_64.rpm rpm -ivh thrift-0.9.1-15.el7.x86_64.rpm rpm -ivh boost-atomic-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-system-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-chrono-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-context-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-date-time-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-filesystem-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-regex-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-graph-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-iostreams-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-thread-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-locale-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-math-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-program-options-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-python-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-random-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-serialization-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-signals-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-test-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-timer-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-wave-1.53.0-27.el7.x86_64.rpm rpm -ivh boost-1.53.0-27.el7.x86_64.rpm rpm -ivh json-c-0.11-4.el7_0.x86_64.rpm rpm -ivh net-snmp-libs-5.7.2-43.el7.x86_64.rpm rpm -ivh net-tools-2.0-0.22.20131004git.el7.x86_64.rpm rpm -ivh apache-hawq-2.4.0.0-el7.x86_64.rpm |
安装完毕后,修改gpadmin用户密码为gpadmin
| passwd gpadmin |
切换用户
| su - gpadmin |
2.5编辑hawq配置文件,在所有节点上执行
HAWQ数据库的安装位置在/usr/local/apache-hawq
| vim /usr/local/apache-hawq/etc/hawq-site.xml |
//注意:关于yarn的参数与yarn-site.xml相同
default_hash_table_bucket_number的值是节点node数*6
| <configuration> <property> <name>hawq_master_address_host</name> <value>server23</value> <description>The host name of hawq master.</description> </property>
<property> <name>hawq_master_address_port</name> <value>5432</value> <description>The port of hawq master.</description> </property>
<property> <name>hawq_standby_address_host</name> <value>none</value> <description>The host name of hawq standby master.</description> </property>
<property> <name>hawq_segment_address_port</name> <value>40000</value> <description>The port of hawq segment.</description> </property>
<property> <name>hawq_dfs_url</name> <value>namenodeCluster/hawq_default</value> <description>与hdfs-site.xml的dfs.nameservices值相同 URL for accessing HDFS.</description> </property>
<property> <name>hawq_master_directory</name> <value>/usr/local/apache-hawq/hawq-data-directory/masterdd</value> <description>The directory of hawq master.</description> </property>
<property> <name>hawq_segment_directory</name> <value>/usr/local/apache-hawq/hawq-data-directory/segmentdd</value> <description>The directory of hawq segment.</description> </property>
<property> <name>hawq_master_temp_directory</name> <value>/usr/local/apache-hawq/tmp</value> <description>The temporary directory reserved for hawq master.</description> </property>
<property> <name>hawq_segment_temp_directory</name> <value>/usr/local/apache-hawq/tmp</value> <description>The temporary directory reserved for hawq segment.</description> </property>
<property> <name>hawq_global_rm_type</name> <value>yarn</value> <description>The resource manager type to start for allocating resource. 'none' means hawq resource manager exclusively uses whole cluster; 'yarn' means hawq resource manager contacts YARN resource manager to negotiate resource. </description> </property>
<property> <name>hawq_rm_memory_limit_perseg</name> <value>1GB</value> <description>The limit of memory usage in a hawq segment when hawq_global_rm_type is set 'none'. </description> </property>
<property> <name>hawq_rm_nvcore_limit_perseg</name> <value>4</value> <description>The limit of virtual core usage in a hawq segment when hawq_global_rm_type is set 'none'. </description> </property>
<property> <name>hawq_rm_yarn_address</name> <value>server23:8032</value> <description>如果设置了yarn的ha,这个配置参数会被yarn-client.xml替代,但是该配置不能删除,否则无法启动,与yarn-site.xml的yarn.resourcemanager.address相同</description> </property>
<property> <name>hawq_rm_yarn_scheduler_address</name> <value>server23:8030</value> <description>如果设置了yarn的ha,这个配置参数会被yarn-client.xml替代,但是该配置不能不删除,否则无法启动, 与yarn-site.xml的yarn.resourcemanager.scheduler.address相同</description> </property>
<property> <name>hawq_rm_yarn_queue_name</name> <value>default</value> <description>yarn的队列名,yarn里必须有这个队列The YARN queue name to register hawq resource manager.</description> </property>
<property> <name>hawq_rm_yarn_app_name</name> <value>hawq</value> <description>The application name to register hawq resource manager in YARN.</description> </property>
<property> <name>hawq_re_cpu_enable</name> <value>false</value> <description>The control to enable/disable CPU resource enforcement.</description> </property>
<property> <name>hawq_re_cgroup_mount_point</name> <value>/sys/fs/cgroup</value> <description>The mount point of CGroup file system for resource enforcement. For example, /sys/fs/cgroup/cpu/hawq for CPU sub-system. </description> </property>
<property> <name>hawq_re_cgroup_hierarchy_name</name> <value>hawq</value> <description>The name of the hierarchy to accomodate CGroup directories/files for resource enforcement. For example, /sys/fs/cgroup/cpu/hawq for CPU sub-system. </description> </property>
<property> <name>hawq_acl_type</name> <value>standalone</value> <description>HAWQ ACL mode. 'standalone' means HAWQ does native ACL check; 'ranger' means HAWQ does priviliges check through Ranger. </description> </property>
<property> <name>hawq_rps_address_port</name> <value>8432</value> <description>The port number of Ranger Plugin Serice. HAWQ RPS address is http://$rps_host(hawq_master_address_host or hawq_standby_address_host):$hawq_rps_address_port/rps For example, http://localhost:8432/rps </description> </property>
<property> <name>default_hash_table_bucket_number</name> <value>6</value> </property>
</configuration> |
2.6初始化环境变量,在所有节点上执行
| source /usr/local/apache-hawq/greenplum_path.sh |
2.7设置免密输入,在所有节点上执行
| hawq ssh-exkeys -h server23 -h server24 -h server25 |
输入密码gpadmin
2.8设置hawq关联hadoop ha,在所有节点上执行
| vim /usr/local/apache-hawq/etc/hdfs-client.xml |
添加HDFS HA的部分,注意:这些配置都与hdfs-site.xml内容相同
| <!-- HA --> <property> <name>dfs.nameservices</name> <value>namenodeCluster</value> </property> <!-- NameServer下有nn1,nn2 --> <property> <name>dfs.ha.namenodes.namenodeCluster</name> <value>n1,n2</value> </property> <property> <name>dfs.namenode.rpc-address.namenodeCluster.n1</name> <value>server23:9000</value> </property> <property> <name>dfs.namenode.http-address.namenodeCluster.n1</name> <value>server23:50070</value> </property> <property> <name>dfs.namenode.rpc-address.namenodeCluster.n2</name> <value>server24:9000</value> </property> <property> <name>dfs.namenode.http-address.namenodeCluster.n2</name> <value>server24:50070</value> </property> <!-- HA --> |
| vim /usr/local/apache-hawq/etc/yarn-client.xml |
添加yarn ha的部分,注意:这些配置都与yarn-site.xml内容相同
| <!-- HA --> <property> <name>yarn.resourcemanager.ha</name> <value>server23:8032,server24:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.ha</name> <value>server23:8030,server24:8030</value> </property> <!-- HA --> |
修改这些配置文件,然后替换到所有节点上
2.9建立配套的文件夹,在所有节点上执行
| mkdir -p /usr/local/apache-hawq/tmp mkdir -p /usr/local/apache-hawq/hawq-data-directory/masterdd mkdir -p /usr/local/apache-hawq/hawq-data-directory/segmentdd |
2.10初始化,在server23上执行
| hawq init cluster |
输入y ,最后成功结果如图

2.11建立管理员用户,在server23上执行
进入psql
| psql -d postgres |
输入
| create ROLE postgres with login; alter role postgres with password 'postgres'; alter role postgres with SUPERUSER; |
输入退出psql
| \q |
2.12添加并初始化standby冗余主节点,在server23上执行
| hawq init standby -s server24 |
2.13修改访问权限,在server23,server24上执行
修改master节点和standby节点的文件
| vim /home/gpadmin/hawq-data-directory/masterdd/pg_hba.conf |
添加一行,作用是允许postgres用户使用密码可访问数据库,注意这里,centos系统必须建立一个叫做postgres的用户,useradd一个,否则nacvicat登陆说密码不对
| host all postgres 0.0.0.0/0 md5 |
重启集群,生效配置
| hawq restart cluster |
2.14 如果服务器重启了,数据库开机时程序的启动顺序
| su - gpadmin source /usr/local/apache-hawq/greenplum_path.sh hawq start cluster |
-------------------------------------------HAWQ安装完毕-----------------------------------------
附录
psql查询指令
| psql -d postgres \l //显示所有的库 \c postgres //连接xx库 \dt //显示所有的表 \dn 显示当前数据库的所有模式 |
清空表数据
| TRUNCATE TABLE tb_ai_exception_valuedata_test1 |
查看hawq集群状态,只能在主节点上执行
| hawq state |
有连接时强行关闭hawq
| hawq stop master -M immediate |
查询失败
一.org.postgresql.util.PSQLException: ERROR: failed to acquire resource from resource manager, 3 of 3 segments are unavailable, exceeds 25.0% defined in GUC hawq_rm_rejectrequest_nseg_limit. The allocation request is rejected. (pquery.c:804)
默认值是0.25 ,意思是3个segment如果有3*0.25=1个掉线了,就拒绝查询
--检查segment在线情况
SELECT * FROM gp_segment_configuration;
可看到有segment掉线

或者可以通过hawq state 也可查看
查看yarn的web界面,可看到相应节点的nodemanager已掉线,重启nodemanager
| sh /opt/hadoop-2.6.5/sbin/yarn-daemon.sh start nodemanager |
此次再深层原因为yarn启动容器过多,内存扛不住,resoucemanager爆了,因为有ha自动切换成了别的节点,但是该server的nodemanager没有连接上新的rm,
再深的原因,猜测是容器启动这个需要优化
还是这个错误.所有节点掉线
yarn的rm访问不通,重启rm失败,nm启动了.rm的log显示zookepper连接不同
连接sh /opt/zookeeper-3.5.7/bin/zkCli.sh
ls / 果然不能显示

错误原因应该是zookepper接收到数据,,必须数据同步到磁盘后才回复消息,导致时间超时,rm连接失败,死掉
zookepper死掉,yarn连接不上,最终导致hawq不能查
建议将zoo.cfg的,配置参数加倍
tickTime=4000
initLimit=20
syncLimit=10
如还出现问题,forceSync=no 强制关闭同步
如果hawq初始化失败
| //可以删掉hdfs上的文件 hadoop dfs -rm -r /hawq_default //删除掉hawq的初始化文件 rm -rf /usr/local/apache-hawq/hawq-data-directory/* |
如果初始化启动时报错
PID file "/home/gpadmin/hawq-data-directory/masterdd/postmaster.pid" does not exist
可能是内部的postgres没有启动好,ps -ef |grep postgres 把postgres kill 掉,重新init
zookepper启动命令
| sh /opt/zookeeper-3.5.7/bin/zkServer.sh start |
scp复制命令,例子
| scp -r hadoop-2.6.5 root@server25:/opt/ |
kafka启停命令
| sh /opt/kafka_2.12-2.5.0/bin/kafka-server-stop.sh |
目前已配置使用的端口
50070 hdfs web端口
8485 JournalNode
9000 namenode
8088 yarn web端口
8032 yarn rm
8031 yarn resource-tracker
8030 yarn rm scheduler
8432 hawq rps
5432 hawq
2181 zookepper
10020 mapreduce.jobhistory
19888 mapreduce.jobhistory web
查看总资源队列
SELECT * FROM pg_resqueue_status

segmem 每个虚拟段的内存限额
segcore 每个虚拟段的cpu核数限额
segszie 队列能够为查询分配的虚拟段数
inusemem 当前运行的语句使用的总内存
inusecore 当前运行的语句使用的总核数
rsqholders 并发执行的语句数量
pg_default是pg_root的子队列
修改pg_default队列占比为100%
alter resource queue pg_default with (memory_limit_cluster=100%,core_limit_cluster=100%);
因为已经创建了一个用户 postgres
alter role postgres
查看自己的角色在哪个资源队列
SELECT rolname ,rsqname FROM pg_roles ,pg_resqueue WHERE pg_roles.rolresqueue = pg_resqueue.oid;
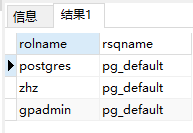
这个hawq安装说明是参考各种博客和官网编写出来了,各种参阅博客上写的基本都有一些莫名的问题或者遗漏一些关键点,此次安装基本把所有的安装坑都踩过了.
所有服务全部使用HA高可用,yarn资源分配
验证了大量查询和插入,使用过程中hawq使用非yarn模式更抗压力.