论文链接
https://arxiv.org/abs/2011.10680
摘要
目前的低精度量化算法往往具有从浮点值到量化整数值的来回转换的隐藏代价。这种隐藏的成本限制了通过量化神经网络所实现的延迟改进。为了解决这个问题,我们提出了HAWQ-V3,一个新的混合精度纯整数量化框架。HAWQ-V3的贡献如下:(i)一个只有整数的推理,其中整个计算图只执行整数乘法、加法和位移动,不需要任何浮点运算甚至整数除法;(ii)一种新的硬件感知混合精度量化方法,其中比特精度是通过解决一个整数线性规划问题来计算的,该问题平衡了模型扰动和其他约束之间的权衡,例如,内存占用和延迟;(iii)TVM中4位统一/混合精度量化的直接硬件部署和开源贡献,实现平均速度为1。统一4位⇥,与统一8位⇥相比,ResNet50在T4gpu上;(iv)在ResNet18/50和Inceptionv3上对所提出的方法进行广泛的评估,对于有/没有混合精度的各种模型压缩级别。对于ResNet50,我们的INT8量化达到了77.58%的精度,比之前的仅整数工作高出2.68%,我们的混合精度INT4/8量化可以减少INT8延迟23%,仍然达到76.73%的精度。我们的框架和TVM的实现都是开源的。
1.引言
我们贡献主要如下:
1.我们开发了HAWQ-V3,一个混合精度的仅整数量化框架,具有仅整数乘法、加法和位移的静态量化。重要的是,在整个推理过程中没有执行浮点运算和整数除法计算。这包括批处理范数层和剩余连接,它们在之前的仅整数量化工作中通常保持在浮点精度(Dongetal.,2019)。虽然将这些操作保持在浮点状态有助于准确性,但这在仅硬件的芯片是不支持的。我们表明,忽略这一点并尝试部署在只有整数的硬件上使用浮点剩余的模型会导致超过90%的不匹配(图G.1)。HAWQ-V3通过使用一种新的方法来执行纯整数算法中的残差连接,从而完全避免了这种情况。详见第3.3节和附录G。
2.我们提出了一种新的硬件感知的混合精度量化公式,它使用一个整数线性规划(ILP)问题来找到最佳的位精度设置。ILP求解器最小化模型扰动,同时观察特定于应用程序的模型大小、延迟和总位操作的约束。与当代的工作(Hubaraetal.,2020)相比,我们的方法是硬件感知的,并使用直接的硬件测量来找到一个在延迟和精度之间的最佳平衡的位精度设置。详见第3.4节和附录一。
3.为了验证我们的方法的可行性,我们使用ApacheTVM(Chen等人,2018)将量化的仅整数模型用于INT8、INT4和混合精度设置。据我们所知,我们的框架是第一个为TVM添加INT4支持的框架。通过分析不同层的延迟,我们表明,与ResNet50的T4GPU上的INT8相比,INT4可以实现平均1.47倍的加速。详见第3.5节和表2节。
3.方法
均匀量化

3.1.量化矩阵的乘法和卷积

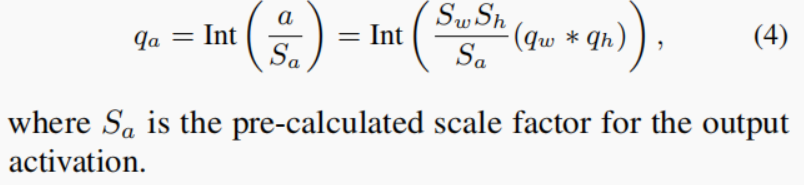
SwSh/Sa可以通过整数乘法移位实现:

3.2. BN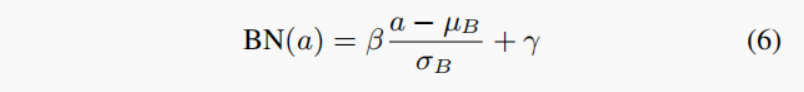
其中,µB和σB为a的均值和标准差,而β,γ为可训练参数。在推理过程中,这些参数(包括统计数据和可训练参数)都是固定的,因此BN操作可以与卷积相融合(见附录D)。然而,一个重要的问题是,量化BN参数往往会导致显著的精度下降。因此,许多先前的量化方法将BN参数保持在FP32精度中。这使得这种方法不适用于纯整数的硬件。虽然使用这些技术有助于提高准确性,但HAWQ-V3完全避免了这种情况。我们将BN参数与卷积融合,并用仅整数方法对它们进行量化(请见图1,我们比较了BN和卷积的模拟量子化和HAWQ-V3)。

这里要讨论的另一个重要问题是,我们发现在(Jacobetal.,2018)中使用的BN折叠是次优的。在他们的方法中,BN层和CONV层被融合在一起,而BN运行的统计数据仍在不断更新。这个动作不使用BN,然后使用BN(如中所示(ally需要计算每个卷积层两次,一次是Jacob等人,2018,图C8))。然而,我们发现这是不必要的,并降低了准确性。相反,在HAWQ-V3中,我们遵循一种更简单的方法,首先保持Conv和BN层的展开,并允许BN统计数据进行更新。经过几个时代之后,我们就冻结了BN层中的运行统计数据,并折叠了CONV和BN层(详情请参见附录D)。正如我们将在第4节中展示的,与(Jacobetal.,2018)相比,这种方法具有更好的准确性。
3.3.残差连接
残差连接(Heetal.,2016)是许多神经网络架构中的另一个重要组成部分。与BN类似,残余连接的量化会导致精度下降,因此,一些预先量化工作执行FP32精度的操作(Choi等人,2018;Wang等人,2019;Zhang等人,2018)。人们有一个普遍的误解,认为这可能不是一个大问题。然而,这实际上导致了信号的完全丢失,特别是对于低精度的量化。这样做的主要原因是量化不是一个线性操作,即Q(a+b)6=Q(a)+Q(b)(a,b是浮点数)。因此,在FP32中执行累积,然后进行量化与累积量化值是不一样的。因此,不可能在仅智能的硬件中部署在FP32中保持剩余连接的量化方法(我们对此提供更详细的讨论在附录F中,并量化由此产生的误差,可以超过90%)。
我们在HAWQ-V3中避免了这种情况,并使用INT32作为残差分支。我们执行以下步骤,以确保加法运算可以发生在二元运算中。让我们将通过残差连接的激活表示为r=Srqr。此外,让我们将残余添加前的主分支的激活表示为m=Smqm,以及通过a=Sa*qa表示残差和后的最终输出。然后我们将有:
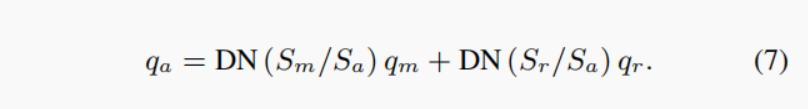
注意,使用这种方法,我们只需要执行qm的二元缩放,并将结果与二元缩放的qr相加。所有这些操作都可以用只使用整数算术进行。我们还应该注意到,在我们的方法中,所有的刻度都是静态已知的。这些步骤如图2所示,对于有/没有降采样的剩余连接。对连接层也采用了类似的方法(见附录E)。
3.4. 混合精度和整数线性规划
将所有层统一量化为低位宽(例如INT4)可能会导致显著的精度下降。然而,低精度是有可能受益的量化通过保持敏感层子集高精度。其基本思想是保持敏感层在较高的精度,而不敏感层在较低的精度。HAWQ-V3的一个重要组成部分是,我们直接考虑特定于硬件的指标,如延迟,以选择位精度配置。这一点很重要,因为当从INT8精度量化到INT4精度时,层的延迟并不一定会减半。事实上,正如我们在第4节中讨论的,有一些特定的层配置在量化到低精度时不会获得任何速度,有些超线性地从量子化中获益。3因此,量化前者不会导致任何延迟的改进,而且只会影响准确性。因此,最好保持这些层的精度较高,即使它们的灵敏度较低。当将精度和延迟量化到低精度时,应该考虑到精度和延迟之间的这些权衡。重要的是,这些权衡是特定于硬件的,因为延迟通常与模型大小和/或FLOPS无关。然而,我们可以通过直接测量在目标硬件平台上以量化精度执行一个层的延迟来考虑这一点。这种权衡如图3所示(稍后在图I.1中进行了量化)。我们可以使用一个整数线性规划(ILP)问题来形式化寻找具有最优权衡的位精度设置的问题定义。

我们在Python中使用开源的PULP库(Roy&Mitchell,2020)来解决ILP,其中我们发现,对于本文中测试的所有配置,ILP求解器可以在给定灵敏度度量的不到1秒内找到解决方案。为了进行比较,基于RL的方法(Wangetal.,2019)可能需要数十个小时来找到正确的位精度设置。同时,可以看出,我们的ILP求解器可以很容易地用于多个约束。然而,由(Dongetal.,2020)提出的帕累托边界的复杂性在多重约束条件下呈指数级增长。在第4.2节中,我们展示了具有不同约束条件的结果。
我们还应该提到,当代的工作(Hubaraetal.,2020),也提出了一个ILP公式。然而,我们的方法是硬件感知的,我们直接部署和度量硬件中每个层的延迟。
3.5.硬件部署
模型尺寸本身并不是衡量神经网络效率(速度和能耗)的一个好指标。事实上,一个小的模型很有可能会有更高的延迟,并消耗更多的能量来进行推断。FLOPs也是如此。原因是模型大小和flop都不能解释缓存丢失、数据本地性、内存带宽、硬件利用不足等。为了解决这个问题,我们需要部署和直接测量延迟。
我们的目标是 Nvidia Turing Tensor Cores of T4 GPU进行部署,因为它同时支持INT8和INT4的精度,并已被增强用于深度学习网络推理。唯一可用的API是WMMA内核调用,它是一个用于在INT4的张量核上的INT4精度中执行矩阵-矩阵操作的微内核。然而,也没有现有的编译器可以使用WMMA指令将一个量化到INT4的NN映射到张量核。为了解决这一挑战,我们工作的另一个贡献是扩展TVM(Chen等人,2018),以支持具有/没有与INT8混合精度的INT4推理。这一点很重要,所以我们可以验证混合精度推理的速度好处。为了实现这一点,我们必须在图级IR和操作符调度中添加新的特性,以使INT4推理效率高。例如,当我们执行诸如内存规划、常数折叠和操作符融合等优化时,在图级IR上,涉及到4位数据.然而,在可字节寻址的机器上,单独操作4位数据会导致存储和通信的效率低下。相反,我们将8个4位元素打包到一个INT32数据类型中,并作为一个块执行内存移动。在最后的代码生成阶段,数据类型和所有内存访问将为INT32进行调整。通过采用类似于弯刀的调度策略(NVIDIA,2020),我们对TVM中的8位和4位数据的张量核实现了一种新的直接卷积调度。我们为线程大小、块大小和循环顺序等配置设置了旋钮,这样TVM中的自动调谐器就可以搜索最佳的延迟设置。
另一个重要的一点是,我们已经完成了直接测试训练的权重,并避免使用随机权值进行速度测量。这一点很重要,因为神经网络训练框架中的量化算法(在我们的例子中是PyTorch)中的量化算法可能会忽略硬件实现之间的小差异,后者不使用TVM进行前向和向后传播。为了避免这类问题,我们确保TVM和PyTorch之间的结果在每一层和阶段都与机器精度匹配,并且在只使用整数运算执行硬件时验证了最终的top-1精度。.在附录G中,我们展示了ResNet50在INT4的特征图的错误积累和,它在PyTorch中使用假量化,并部署在TVM中。
4.结果
在本节中,我们首先讨论INT8、INT4和混合精度INT4/8的各种模型(ResNet18/50和Incepeptiotv3)的结果。随后,我们研究了ILP公式的不同用例,以及相应的模型大小、延迟和准确性之间的权衡。附录h中提供了关于实施和设置的详细讨论。对于所有的实验,我们确保报告并与FP32中已知的基线神经网络模型的最高精度进行比较(即,我们使用强基线进行比较)。这一点很重要,因为使用较弱的基线精度可能会导致误导性的量化精度。
4.1.低精度的仅整数量化结果
我们首先从ImageNet上的ResNet18/50和Inceptionv3量化开始,并比较HAWQV3与其他方法的性能,如表1所示。


4.2.在不同的约束条件下得到的混合精度结果


从这些结果中可以得出几个非常有趣的观察结果。(i)模型大小与BOP之间的相关性较弱,这是预期的。这意味着一个更大的模型尺寸并不意味着更高的BOP,反之亦然。例如,比较ResNet18的中型和高bops。后者的总容量更低,尽管体积更大(实际上也更快)。(ii)模型的大小与精度没有直接相关。例如,对于ResNet50,High-BOPS的模型尺寸为22MB,精度为76.76%,而HighSize的模型尺寸较小,为21.3MB,但精度较高,为77.58%。
总之,尽管直接使用INT4量化可能会导致较大的精度下降,但与INT8的结果相比,我们可以通过更快的推理来显著提高精度。这给从业者提供了比INT8量化更广泛的选择。最后,我们应该提到的是,ResNet18/50和Inceptionv3的所有结果的准确性和速度已经通过在执行时直接测量它们来验证通过TVM在硬件中实现了量化精度。因此,这些结果实际上是从业者将观察到的,而这些并不是模拟的结果。
5. 总结
在这项工作中,我们提出了HAWQ-V3,一个新的低精度的仅整数量化框架,其中整个推理只通过整数乘法、加法和位移来执行。特别是,在整个推理中没有使用FP32算术甚至整数除法。我们给出了均匀和混合精度INT4/8的结果。对于后者,我们提出了一种基于硬件感知的ILP方法,该方法在模型扰动和应用程序特定约束之间寻找最优权衡,如模型大小、推理速度和总bop之间进行权衡。ILP问题可以非常有效地解决,在这里所有考虑的模型。我们表明,与之前的仅使用整数的方法(Jacobetal.,2018)相比,我们的方法可以实现高达5%的更高的精度。最后,我们通过扩展TVM来支持INT4和INT4/8推理,直接在硬件上实现了低精度的量化模型。我们通过将每一层的激活与我们的PyTorch框架(达到机器精度)进行匹配,验证了所有的结果,包括验证了模型的最终精度。框架、TVM实现和量化模型都是开源的(HAWQ,2020)。