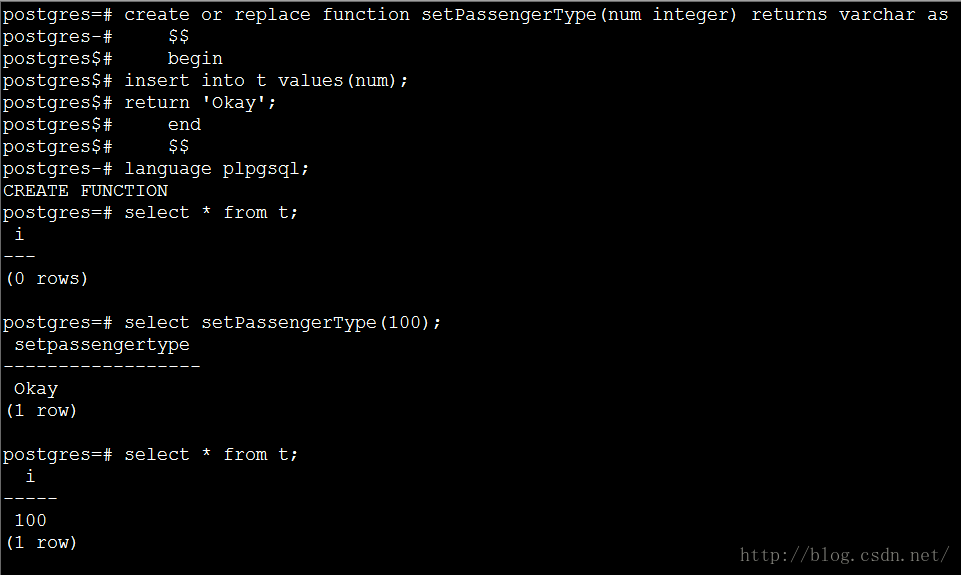
hawq的简介
https://cloud.tencent.com/developer/article/1433137
HAWQ,全称Hadoop With Query(带查询Hadoop)。HAWQ使企业能够获益于经过锤炼的基于MPP的分析功能及其查询性能,同时利用Hadoop堆栈。HAWQ是一个Hadoop原生大规模并行SQL分析引擎,针对的是分析性应用。和其他关系型数据库类似,接受SQL,返回结果集。但它具有大规模并行处理很多传统数据库以及其他数据库没有的特性及功能。
hawq的语法兼容性
HAWQ是100%符合ANSI SQL规范并且支持SQL 92、99、2003 OLAP以及基于Hadoop的PostgreSQL。它包含关联子查询、窗口函数、汇总与数据库、广泛的标量函数与聚合函数的功能。用户可通过ODBC和JDBC连接HAWQ。
hawq是否支持复杂查询
TPC-DS针对具有各种操作要求和复杂性的查询定义了99个模板(例如,点对点、报告、迭代、OLAP、数据挖掘等)。
基准测试是通过TPC-DS中的99个模板生成的111个查询来执行的。依据符合两个要求受支持的查询个数,以下条形图显示了一些基于SQL on Hadoop常见系统的合规等级:1. 每个系统可以优化的查询个数(如,返回查询计划)以及 2. 可以完成执行并返回查询结果的查询个数。
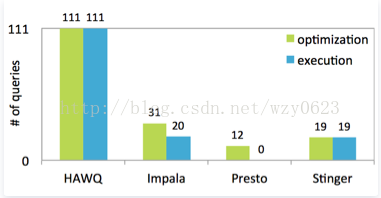
HAWQ的扩展性的SQL支持能力是基于数据仓库的代码库,HAWQ成功完成了全部111个查询。
hawq具有高效的查询优化器
HAWQ吸收了最先进的基于代价的SQL查询优化器,在SQL on Hadoop领域是行业先锋。该查询优化器以针对大数据模块化查询优化器架构中的研究结果为基础而设计。
HAWQ已经过验证,能够快速为涉及超过50个关联表的高要求查询找到理想查询计划,从而成为业内最佳的SQL on Hadoop数据发现与查询引擎。
hawq利用了线性可扩展性,加速Hadoop查询
SQL on Hadoop的主要设计目标是在Hadoop上执行SQL连接时最大程度地降低数据传输的开销。HAWQ采用Dynamic pipelining来解决这一关键要求,使基于HDFS的数据适用于交互式查询。
大数据模块化查询优化器架构中突出的性能分析显示,对于基于Hadoop的分析与数据仓储工作负载,HAWQ要比现有Hadoop查询引擎快一或两个数量级。这些性能改进主要归功于Dynamic pipelining和HAWQ内基于成本的查询优化器的强大功能。这使HAWQ能够帮助企业以显著降低的成本摆脱企业数据仓库工作负载。
一体化深度分析与机器学习功能
HAWQ利用可扩展数据库内分析的开源库MADLib来提供数据分析功能
数据联合能力
HAWQ通过名为Pivotal eXtension Framework(PXF)的模块提供数据联合功能。除了常见的数据联合功能外,PXF还利用SQL on Hadoop提供其它具有行业特色的能力:任意大数据集低延迟,可扩展且可自定义,高效
高可用性和容错能力
HAWQ的容错性、可靠性和高可用性三个特点能容忍磁盘级与节点级故障。HAWQ支持各种事务,是SQL on Hadoop方案的首选。
原生Hadoop文件格式支持
HAWQ在Hadoop中支持AVRO、Parquet和本地HDFS文件格式。这在最大程度上减少了数据摄取期间对ETL的需求,并且利用HAWQ实现了 schema-on-read(读时模式)类处理。对ETL和数据移动需求的减少直接有助于降低分析解决方案的拥有成本。
通过Apache Ambari进行原生的Hadoop管理
HAWQ使用Apache Ambari作为管理和配置的基础,合适的Ambari插件可以使得HAWQ像其他的通用Hadoop服务一样被Ambari来管理,所以IT管理团队不再需要两套管理界面,一套管理Hadoop,一套管理HAWQ。
Hortonworks Hadoop兼容
为了更进一步的跟进开放数据联盟ODP的步伐,HAWQ可以与Hortonworks HDP大数据体系无缝兼容,使得企业在已经投资的Hortonworks 大数据平台上感受到业界最先进的SQL on Hadoop方案带来的所有好处,HAWQ也同时支持Pivotal自己的Hadoop发行版Pivotal HD。
HAWQ的其它主要特性
- 弹性执行引擎:可以根据查询大小来决定执行查询使用的节点及Segment个数。
- 支持多种分区方法及多级分区:比如List分区和Range分区。分区表对性能有很大帮助,比如你只想访问最近一个月的数据,查询只需要扫描最近一个月数据所在分区。
- 支持多种压缩方法:snappy,gzip,quicklz,RLE等。
- 动态扩容:动态按需扩容,按照存储大小或者计算需求,秒级添加节点。
- 多级资源或负载管理:和外部资源管理器YARN集成;可以管理CPU,Memory资源等;支持多级资源队列;方便的DDL管理接口。
- 完善的安全及权限管理:kerberos;数据库,表等各个级别的授权管理。
- 支持多种第三方工具:比如Tableau,SAS,较新的Apache Zeppelin等。
- 支持对HDFS和YARN的快速访问库:libhdfs3和libyarn(其他项目也可以使用)。
- 支持在本地、虚拟化环境或者在云端部署。
hawq的基本架构
https://cloud.tencent.com/developer/article/1011684
在一个典型的HAWQ部署中,每个slave节点上会安装有一个HAWQ物理段,一个HDFS的DataNode和一个NodeManager。而HAWQ、HDFS和YARN的主机则安装在(与slave)分离的节点上。
下图提供了一个HAWQ典型部署的高级别架构视图。

HAWQ与Hadoop的资源管理框架YARN紧密结合,为查询提供资源管理。HAWQ在一个资源池中缓存YARN容器,然后利用HAWQ自身的细粒度资源管理,为用户或组在本地管理这些资源。当执行一个查询时,HAWQ根据查询成本、资源队列定义、数据局部化和当前系统中的资源使用情况,为查询分配一组虚拟段。之后查询被分发到相应的物理主机,可能是节点子集或整个集群。每个HAWQ节点上的资源实施器监控着查询对资源的实时使用情况,避免违规的资源使用。
下图提供了构成HAWQ软件组件的另一个视图。

1. HAWQ主节点
HAWQ主节点是系统的入口点,有一个接受客户端连接,并处理SQL命令的数据库进程。HAWQ主节点解析查询,优化查询,向段分发查询,并协调查询执行。
最终用户通过主节点与HAWQ交互。可以使用如psql的客户端程序,或者类似JDBC、ODBC的应用程序接口(APIs)连接到数据库。
“全局系统目录”是一组系统表的集合,包含HAWQ系统自身的元数据,存储在主节点中。主节点本身不含任何用户数据,数据只存储在HDFS上。主节点对客户端连接请求进行鉴权,处理输入的SQL命令,在段间分发任务,协调每个段返回的结果,向客户端程序输出最终结果。
2. HAWQ段
在HAWQ中,段是并行数据处理单元。
每个主机上只有一个物理段,每个段可以为一个查询片段启动多个查询执行器(Query Executors ,QEs)。这使得单一的物理段表现得像多个虚拟段,从而使HAWQ能够更好地利用所有可用资源。一个虚拟段就像是QE的一个容器。每个虚拟段含有为查询片段启动的一个QE。虚拟段的数量被用于确定一个查询的并行度(degree of parallelism,DOP)。
主节点将SQL请求连同相关的元数据信息分发给段进行处理。元数据中包含所请求表的HDFS url地址,段使用该URL访问相应的数据。
3. HAWQ互联
“互联”是HAWQ的网络层。当一个用户连接到数据库并发出了一个查询,每个处理查询的段上会创建多个进程。“互联”指的是段之间的进程间通信,以及通信所依赖的底层网络架构。互联使用标准的以太网交换结构。
缺省情况下,互联使用UDP(User Datagram Protocol)在网络间传输消息。HAWQ软件在UDP的功能之上执行附加的包验证。这就意味着(HAWQ的网络传输)可靠性相当于TCP(Transmission Control Protocol),而在性能和可扩展性上却优于TCP。如果使用TCP互联,HAWQ有一个1000个段实例的扩展上限,而UDP作为当前互联使用的缺省协议,则没有这个限制。
4. HAWQ资源管理器
HAWQ资源管理器从YARN获取资源,并响应资源请求。资源被HAWQ资源管理器缓存,以支持低延时查询。HAWQ资源管理器也能够以独立模式运行。在这种部署中,HAWQ自己管理资源而不需要YARN。
5. HAWQ目录服务
HAWQ目录服务存储全部元数据,例如UDF/UDT信息,表信息,安全信息和数据文件位置信息等。
6. HAWQ容错服务
HAWQ容错服务(FTS)负责接收从segment发来的心跳信息,并负责检测段是否失效。
7. HAWQ分发器
HAWQ分发器将查询计划分发到选择的段的子集上,并协调查询的执行。分发器和资源管理器是HAWQ的主要组件,分发器负责查询的动态调度。资源管理器负责执行查询资源需求。
hawq性能
https://www.codercto.com/a/100426.html
-
HAWQ环境

- 测试数据
数据存放路径:/data1~12/iplog,一个盘20G,6台 服务器 每台都是240G,一共1440GB;每台服务器12个盘装载4个分区(小时)数据,每个盘装载4个分区的1/12的数据,4个文件,每个文件大小5G,2500w条记录,一条记录200Byte。
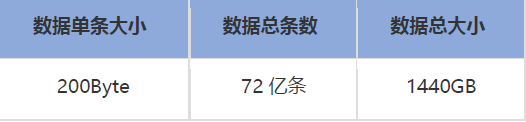
- 测试SQL
测试挑选4个实际典型SQL,大致如下:

测试明细:
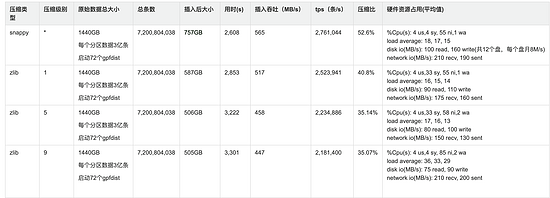
结果图形展示:
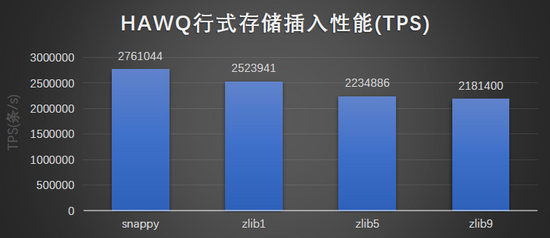
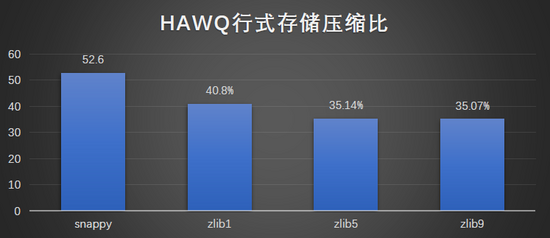
-
行式存储查询性能:
测试明细:
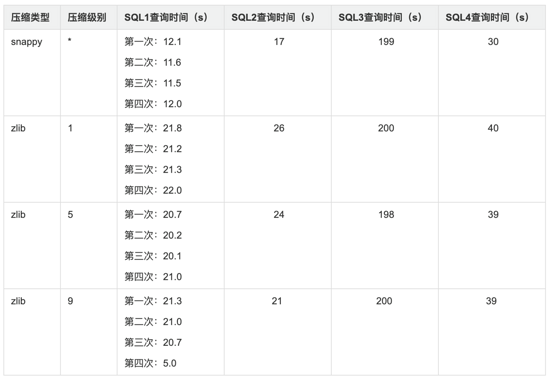
结果图形展示:
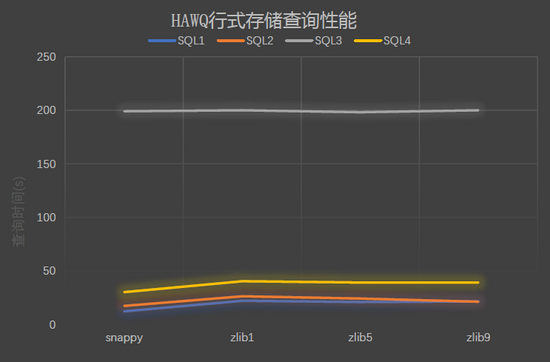
-
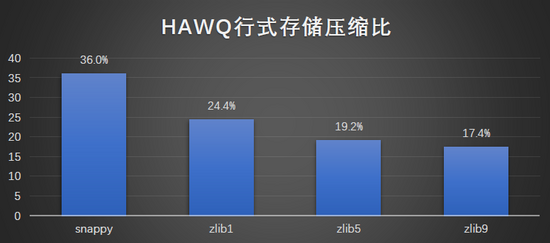
列式存储与压缩:
测试明细:
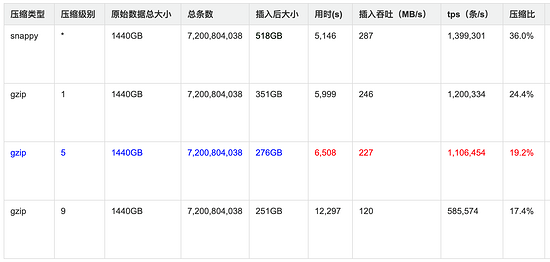
结果图形展示:
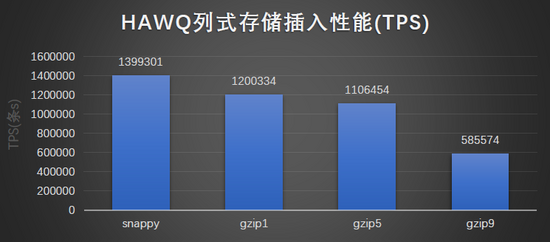
-
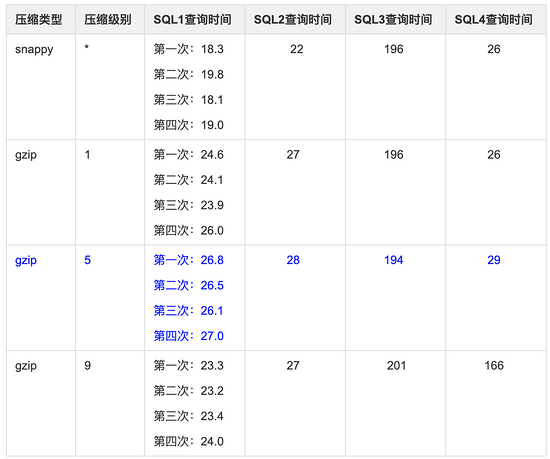
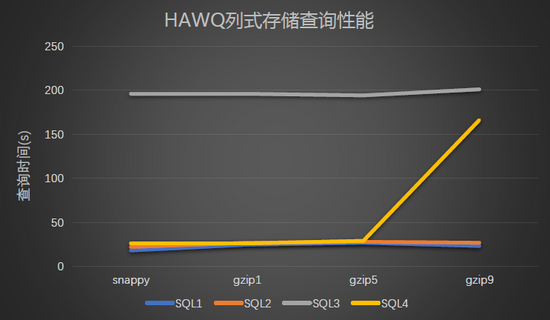
列式存储查询性能:
测试明细:
结果图形展示:
https://blog.csdn.net/wzy0623/article/details/71544580
HAWQ提供的TPC-DS性能比较图,可以看到HAWQ平均比Impala快4.55倍。

HAWQ与Hive查询性能对比图。对于不同查询,HAWQ比Hive快4-50倍。