前言:
计算机操作系统中存储信息都是以字节为单位,每个地址单元对应 1 个字节。
1 个字节为 8 bits,对于某些32 位处理器而言,char类型数据占用 1 个字节的空间,short 占用2个字节,int 占用4个字节。而这些字节在内存中的存储顺序,以及字节内存的排列方式,都是人们迫切关注的。当第一个字节出现的时候,第二个字节就需要确定其出现的位置以及其意义。
例如,Internet 协议,例如RFC 791;
再例如,文件格式,例如GIF、JPEG、MPEG等等。
而这些字节一个接着一个的顺序,称之为字节顺序(endianness)。从左往右、从右往左,字节顺序被分为两种:
- 大端字节序;
- 小端字节序;
详细说明:
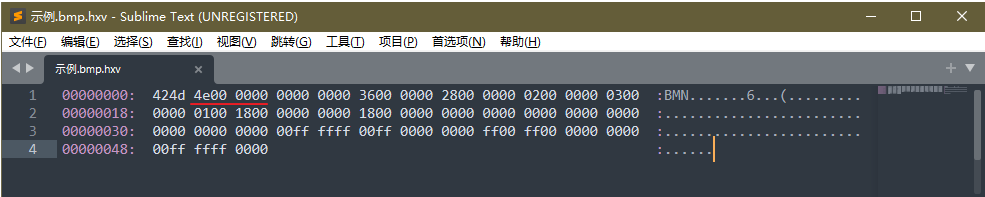
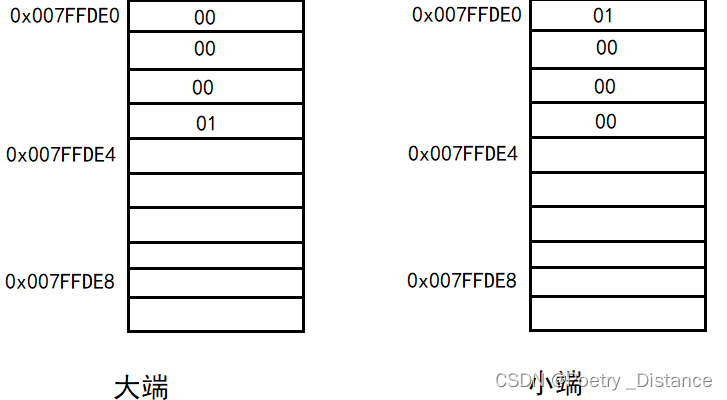
对于一个数x 的值为0x2211,其中0x22 为高字节,0x11 为低字节。
对于大端模型,在文件、协议传输时,会按照读的顺序,先是0x22,接着是0x11。
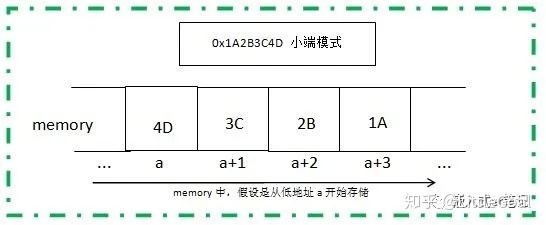
对于小端模型,恰好相反,会将0x22 会接着0x11 之后。
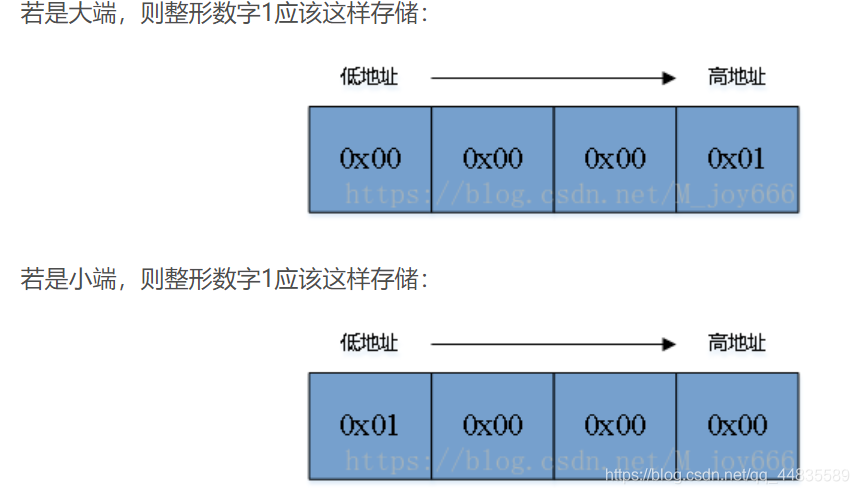
而在计算机中,大端模型会将数据的高字节的保存在内存的低地址中,而数据的低字节保存在内存的高地址中。小端模型相反。
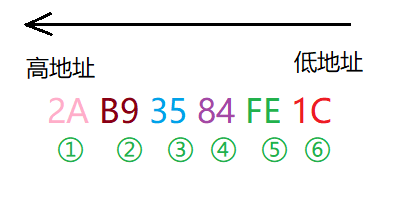
例如对于数0x1234567
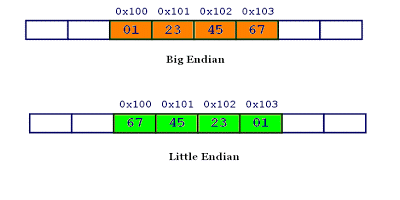
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。
计算机中存储如下:
计算机中先读取低位字节的数,也就是说计算机内部处理中都是小字节序。
计算机中采用的是小端字节序的方式:
If little-endian is so confusing to the human mind, why would anybody ever use it? The answer is that it can be more efficient for logic circuits. Or at least, back in the 1970s, when CPUs had only a few thousand logic gates, it could be more efficient. Therefore, a lot of internal processing was little-endian, and this bled over into external formats as well.
对于网络协议和文件格式都采用的大端字节序的方式:
On the other hand, most network protocols and file formats remain big-endian. Format specifications are written for humans to understand, and big-endian is easier for us humans.
区分:
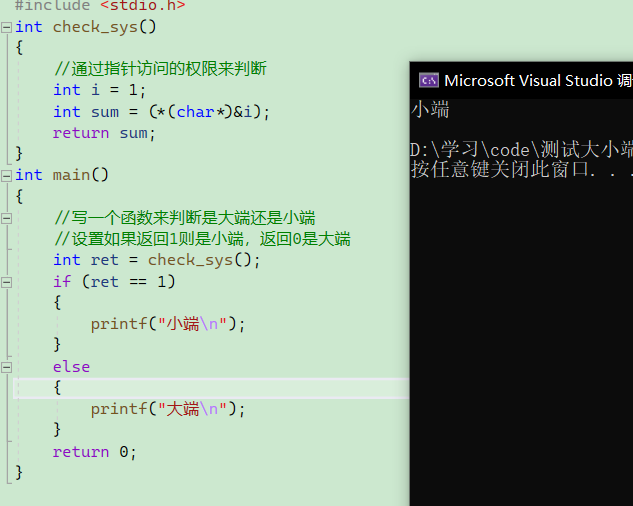
如何判断处理器是大端模式还是小端模式?联合体(union) 的存放顺序是所有成员都从低地址开始存放,利用该特性可以轻松判断CPU 对内存采用大端模式,还是小端模式读写。
如果以下代码的输出结果为true,则为小端模式,否则为大端模式:
int checkCPU(void)
{union x{int a;char b;} c;c.a = 1;return (c.b == 1);
}