这就是字节序问题:数据在计算机内存中存储或者网络传输时各字节的存储顺序
通常来说就分为两种情况:
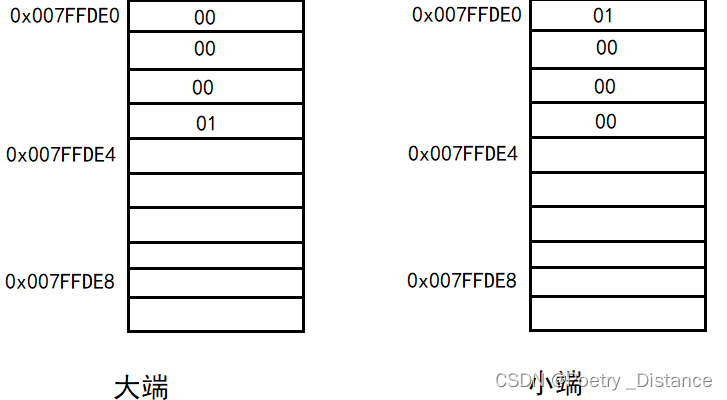
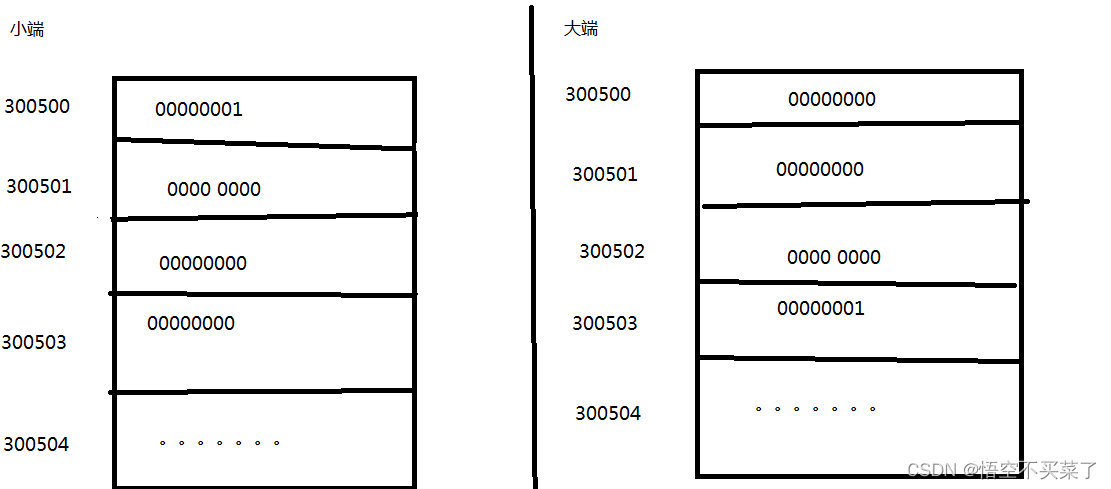
一种是大端(big-endian):高字节(高位)存放在低地址,低字节(低位)存在高地址
另外一种小端(little-endian):高位存放在高地址,低位存放在低地址
这里先来说一下,数据采用大端还是小端与cpu,系统,硬件参数有很大关系,不管什么编程语言,数据都有可能采用大端或者小端来存放,一般来说windows,linux,手机,平板都是采用小端来存存放数据,这种数据存储方式有利用寻址并且数据改写。
下面具体来说一下小端、大端怎么来存放。
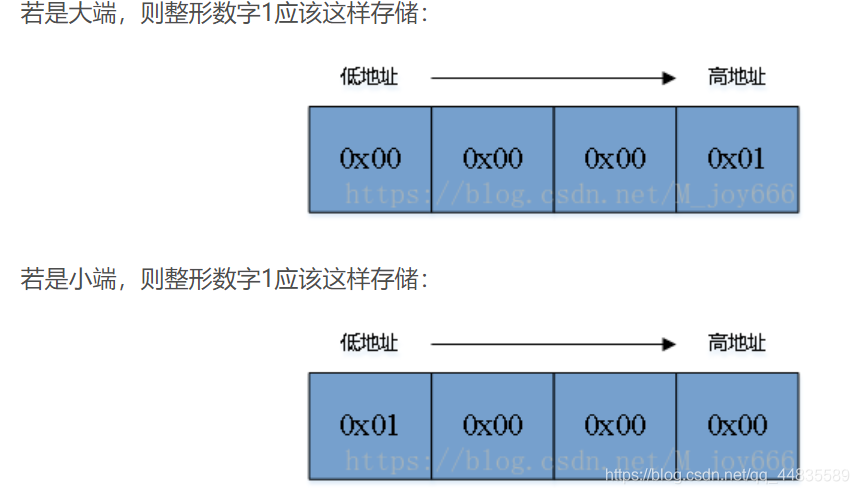
假设现在有一个数据,int num = 1;大家都知道,int 是占用四个字节的,那么对于num来说,它的在内存中的二进制表示就是:
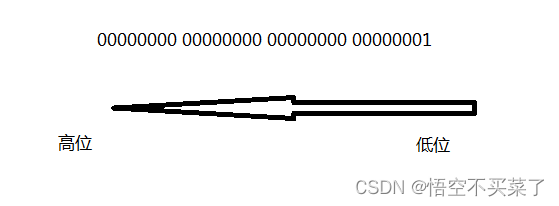
现在来说大端、小端是如何存放的:
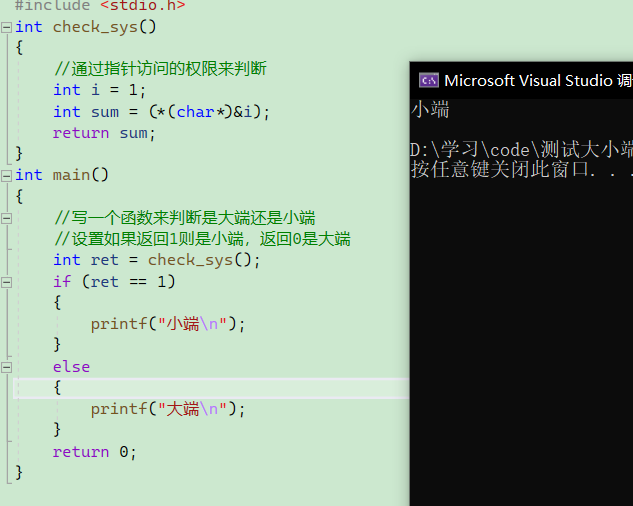
下面用代码来验证一下:
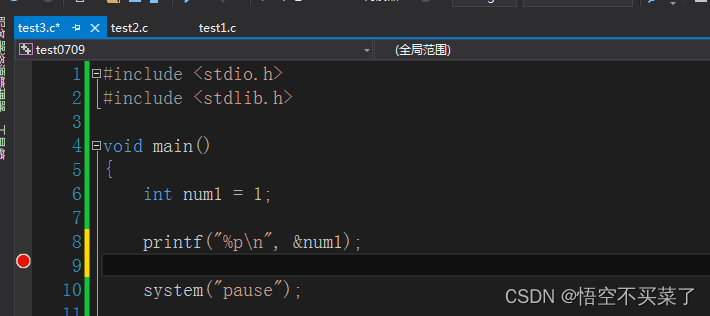 代码其实很简单,上面下了一个断点,我们来获取地址,直观去看一下内存数据如何存放
代码其实很简单,上面下了一个断点,我们来获取地址,直观去看一下内存数据如何存放
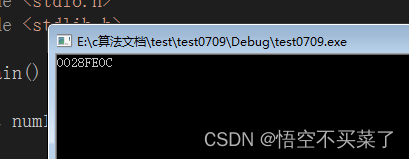
跳转到上面这个内存地址:
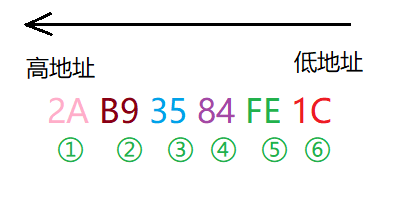
我这里是选择的一列按照十六进制显示:
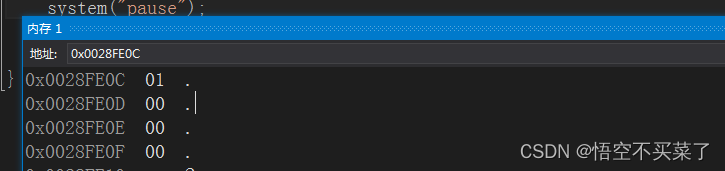 观察一下0x0028FE0C这个起始地址,存放的是01这样的十六进制数据,那么换成二进制,四个二进制数据对应一个十六进制数据,就是00000001,也就是低位存放在低地址,按照小端存放。
观察一下0x0028FE0C这个起始地址,存放的是01这样的十六进制数据,那么换成二进制,四个二进制数据对应一个十六进制数据,就是00000001,也就是低位存放在低地址,按照小端存放。
那么我们换一种方式去看看linux系统又是按照什么方式存储数据
demo.c
#include <stdio.h>
#include <stdlib.h>int main()
{int num1 = 1;char *p_num1 = (char*)&num1;int i = 0;for(;i < 4;i++) {//指针的加减是前进相应的数据类型//比如p_num1+i就会往前走char类型的长度printf("%p %d\n",p_num1+i,*(p_num1+i));}return 0;
}
运行结果:
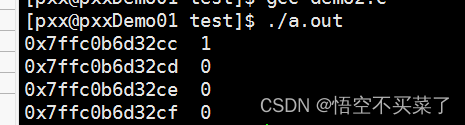
上面我就用了一个char 类型的指针指向了int类型数据的地址起始,为什么char,不用int,因为如果用int,一旦+1,就会指向int这个数据类型的末尾。
上面我们也可以看出,linux也是按照小端字节存放的。
下面我们来说一下java怎么来判断是小端还是大端。
java由于无法操作内存,我们直接调用一个类里面的方法即可

上代码:
package pxx;import java.nio.ByteOrder;public class Demo1 {public static void main(String[] args) {ByteOrder byteOrder = ByteOrder.nativeOrder();System.out.println(byteOrder);}
}
运行结果:
OK,说到这