文章目录
- 问题起源
- 大端
- 小端
- 大端小端优劣
- 符合人类阅读方式
- 数据类型转换
- 符号位的识别
- 参考资料
曾经辨析和了解过大端小端,但是到了实际应用中还是比较模糊。整理一些资料文章,在此记录。
问题起源
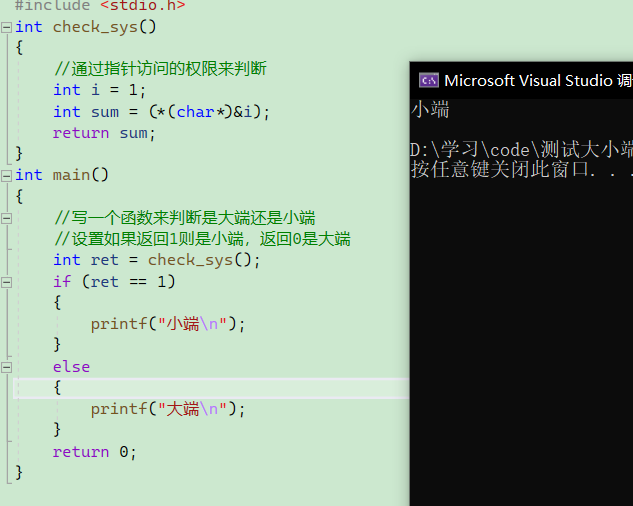
在计算机的使用以及现代很多的嵌入式设备中,我们也通常会用到16bit,32bit和64bit等数据类型。数据都是以一组连续的字节存储的。每一个字节都有一个地址。显然,16bit,32bit和64bit等这些数据将占用多个字节。那当我们说“变量的地址”时,指的是这几个字节中的哪个字节呢?更具体地,如下这段简单地C代码所示,a变量占用4个字节,用取址运算符查看其地址,本机地运行结果是“addr of a = 000000000061FE1C”,返回地地址000000000061FE1C是这4个字节中地哪个呢?
int main(){int a = 123;printf("addr of a = %p",&a);//addr of a = 000000000061FE1Creturn 0;
}
在CSAPP第39页(2.4.1 Adddress and Byte Ordering)中提到:对象地地址就是这些字节地最小地址(with the address of the object given by the smallest address of the bytes used)。(个人理解:对于一个变量,计算机都是从低地址开始读取数据的,所以这也是这个变量的开始地址,但是至于这读到的是什么意思,应该如何解析,就涉及到后面会解释的大端和小端)。也就是说这个变量占用地应该是000000000061FE1C ~ 000000000061FE1F. 可以用以下代码检测,代码参考https://blog.csdn.net/hbsyaaa/article/details/106970226
int main(){int a = 258;unsigned char* ptr1;unsigned char* ptr2;unsigned char* ptr3;unsigned char* ptr4;printf("addr of a = %p\n",&a);//addr of a = 000000000061FE1Cprintf("addr of a = %p\n",&a+1);//addr of a = 000000000061FE00ptr1 = (unsigned char*)&a; //ptr1 = 61fdfc,*ptr1 = 2ptr2 = (unsigned char*)&a+1; //ptr2 = 61fdfd,*ptr2 = 1ptr3 = (unsigned char*)&a+2; //ptr3 = 61fdfe,*ptr3 = 0ptr4 = (unsigned char*)&a+3; //ptr4 = 61fdff,*ptr4 = 0/* wrong code beginptr1 = (unsigned char*)&a; //ptr1 = 61fdfc,*ptr1 = 2ptr2 = (unsigned char*)(&a+1);//ptr2 = 61fe00,*ptr2 = 8ptr3 = (unsigned char*)(&a+2);//ptr3 = 61fe04,*ptr3 = 0ptr4 = (unsigned char*)(&a+3);//ptr4 = 61fe08,*ptr4 = 4end of wrong code */printf("ptr1 = %x,*ptr1 = %d\n", ptr1,*ptr1);printf("ptr2 = %x,*ptr2 = %d\n", ptr2,*ptr2);printf("ptr3 = %x,*ptr3 = %d\n", ptr3,*ptr3);printf("ptr4 = %x,*ptr4 = %d\n", ptr4,*ptr4);}
在写这段代码地时候犯了个错误,如以上代码块中“wrong code begin”到”end of wrong code"部分,从而导致结果不是预期地那样。可以发现,与上面四行正确地相比,错的就是对“&a+#”多加了一组括号。这个错误主要是由于自己对运算优先级以及强制类型转换的错误理解。错误地代码中,由于a是一个int,因此对指针进行+1操作时,增加的时4个字节,得到的结果也是一个指针(地址值),但指向的是后面第4个字节,而不是下一个字节;即地址值从0x61fdfc增加到了0x61fe00。新的指针指向地内存空间中的数据时不确定地,因此会打出一些奇怪地数字。正确地做法不用括号。在正确代码中,&运算符优先级最高,先与a运算,之后进行从左往右的运算,即先把&a的结果进行类型转换,强制转换成一个指向unsigned char类型的指针(注意这个*,这是一个指针类型的强制转换,而不是将int转成char,需要的结果是个指针),从而此时再对这个结果,即unsigned char类型指针进行+1操作,就是指向了下一个字节,这样才能得到想要的结果。
通过上面这个试验也可以看出,&a得到的是其4个字节中占有的“4个连续地址”的最小值。
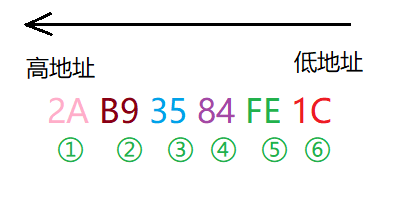
但是这又会带来一个问题:最小地址存放的是这个数的最高字节(most significant byte)还是最低字节(least significant byte)?这里的“最高字节”和“最低字节”指的是一个数的高位和低位。比如一个十进制数123,1是百位,代表的是100,是这个数的最高位;3是个位,表示的就是3,是这个数的最低位。一个二进制数也是一样的,比如一个32位的数“1100 1010 1100 0011 1111 0000 1101 0010”,按照一般人的习惯,从左往右看,最高字节就是“1100 1010”,最低字节就是“1101 0010”。但是计算机不一定这么看。这就涉及到了大端小端的问题。
大端和小端时数据存储的两种不同的形式。不同的CPU、操作系统、甚至应用程序对待数据的存储方式都有所不同。
大端
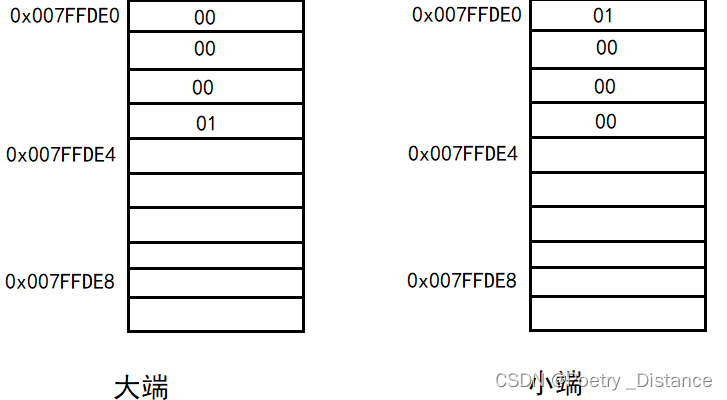
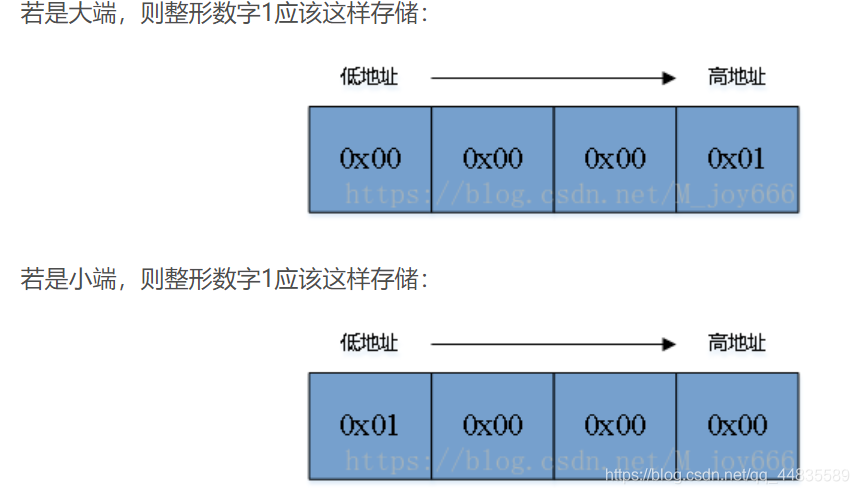
大端存储方式,即“数值的高位在内存低地址” 。
对于“1100 1010 1100 0011 1111 0000 1101 0010”,大端数据存储方式如下

计算机从低地址开始读/写,所以它先读到/写入的是这个数的最高字节(most significant byte comes first)。
小端
小端存储方式,即“数值的低位在内存低地址” 。
对于“1100 1010 1100 0011 1111 0000 1101 0010”,小端数据存储方式如下

计算机从低地址开始读/写,所以它先读到、写入的是这个数的最低字节(least significant byte comes first)。
大端小端优劣
符合人类阅读方式
通常说“大端更符合人的阅读方式”,主要是出于“人类通常先识别到最高位,再看最低位”的习惯来说的,因为大端存储时,计算机也是“先看到(处理)数值的最高位”。另外,在很多图示中,比如本文中上面两个“大端数据存储方式”和“小端数据存储方式”两幅图,为了表现出“大端符合人类的习惯”,其实在画图时也有一个前提:在表示“地址”的部分也是按照“从左到右,从小的地址到大的地址”来画的。如果反过来话,也就不能说“符合人类阅读习惯”了。
数据类型转换
(本节参考:https://fishc.com.cn/forum.php?mod=viewthread&tid=75394&extra=page%3D1%26filter%3Dtypeid%26typeid%3D571)
对于数值int num = 0x1234,并且还是按照“从左到右,地址由低到高”的惯例:
- 按照小端存储方式,计算机存储顺序为 0x34120000;如果要将其转换为long,则只需要在它“后面”(高地址处)补0,变成0x34120000 00000000即可。(这里是需要将一个32位的数变成一个64位的数,这多出来的32位往哪儿放、放什么,才能使值不变?显然应该在这个数的高位填充32个0。对于一个按照小端存储方式的数以及人类习惯的阅读书写规则“从左到右,地址由低到高”,它的高位就在它的“右面”,所以书写时,在后面加上0,而在计算机的角度,就是在高地址填充0)
- 按照大端存储方式,计算机存储顺序为 0x00001234;如果要将其转换为long,由于4是这个数值的最低位,所以还是要把它放在存储区域的最高地址,因此不能直接在后面补0;而且由于类型转换之后,变量的地址不能改变,因此不能再这个数值前面(即当前最低地址之前更低的地址)直接补0,否则按照“对象地地址就是这些字节地最小地址”,这个变量的地址就被改变了。所以要进行相应类型转换,只能通过两个步骤进行:
(1)先将原来的数向右移动8个字节
(2)再将这移出来的地方(低地址)用0补齐
符号位的识别
(本节参考:https://fishc.com.cn/forum.php?mod=viewthread&tid=75394&extra=page%3D1%26filter%3Dtypeid%26typeid%3D571)
对于有符号的变量,在其二进制表示中,数值的最高位就是符号位。
- 如果大端存储方式,由于书写表达时数值时,比较符合大部分人的阅读习惯,最左边的这个数就是符号位,方便人来判断这个数值的正负。
- 但是如果使用小端存储方式,就不便于人直接判断这个数值的正负了
参考资料
- https://fishc.com.cn/forum.php?mod=viewthread&tid=75394&extra=page%3D1%26filter%3Dtypeid%26typeid%3D571
- https://blog.csdn.net/hbsyaaa/article/details/106970226
- CSAPP