16进制的使用
在开发过程中,写文件是常有的事,如果写的内容是文本,随便用一个记事本软件打开即可查看内容是否正确,如果写的是音频文件,就要用音频播放器来查看,如果是视频文件,就要用视频播放器来查看。。。对应的文件就要用对应的软件来查看,但是做为开发,有时候是要查看文件的二进制的,比如我们写一个音频转换器的时候,发现转换后的音频无法播放,就需要查看此音频文件的二进制内容(如何查看文件的二进制可以参考我的另一篇文章,点此跳转),以分析是哪里的数据出了问题,而看二进制时,看0101010100111这种二进制形式的数据是很痛苦的,应该也没人会这么干,因为我们看二进制主要是看这个二进制对应的10进制值或16进制值是多少,其中,以16进制查看是最方便的,因为十六进制的F表示15,它是4个bit能表示的最大值,FF表示255,它是8个bit能表示的最大值,8个bit正好是1个byte(字节),而计算机中是以字节为单位进行存储的,所以用两位16进制值就正好能表示一个字节范围内的所有的值,如果是用10进制,255是一个字节的最大值,256就需要两个字节了,255和256都是三位数,而255用1个字节表示,而256却需要2个字节,所以用10进制来理解二进制是比较麻烦的,而用16进制就比较方便了,用两位16进制值就正好能对应一个字节的二进制值,比如,有如下的二进制:
0111 1111 0000 0001 0000 1111 1111 1111
这里加入了一些空格,是为了让大家看清楚每4位和每8位的分隔,这里共有4个字节,它对应的16进制值如下:
- 0111 > 0x7
- 1111 > 0xF
- 0000 > 0x0
- 0001 > 0x1
- 0000 > 0x0
- 1111 > 0xF
- 1111 > 0xF
- 1111 > 0xF
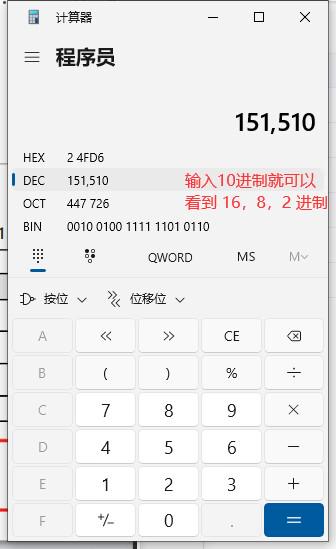
连接起来就是:0x7F010FFF,可以使用Windows自带计算器输入对应的二进制查看结果,如下:
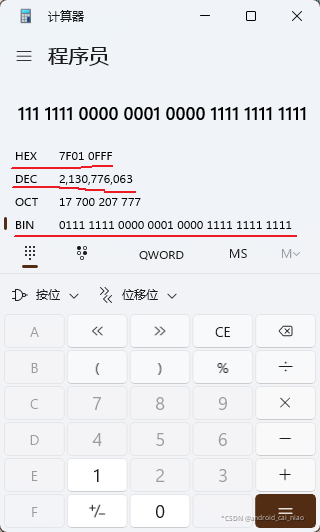
可以看到,当我们输入二进制后,它会自动得出对应的16进制、10进制、8进制的值,16进制值为0x7F010FFF,对应的10进制值为2130776063,可以看到,10进制是很长的,而16进制就比较短,所以16进制写起来也方便一些,而且16进制的每两位对应一个字节,这也方便我们查看每一个字节,比如,我要查看2130776063这个整数它的每一个字节的值是多少,我们知道一个int类型是占4个字节的,所以我们可以使用位移操作来获取每个字节的值,如下:
fun main() {val value: Int = 2130776063val bytes = ByteArray(4)bytes[0] = (value ushr 24).toByte()bytes[1] = (value ushr 16).toByte()bytes[2] = (value ushr 8).toByte()bytes[3] = (value ushr 0).toByte()bytes.forEachIndexed { index, byte ->// 把byte转换为等价的正数int值,以防byte是负数的情况val byteValue = byte.toInt() and 255println("bytes[${index}] = $byteValue")}
}
输出结果如下:
bytes[0] = 127
bytes[1] = 1
bytes[2] = 15
bytes[3] = 255
如上例子,我们以10进制来查看整数2130776063的每一个字节对应的值,但是看了打印结果后,我们也不知道对不对,代码写的有没有问题也不能确定,而如果我们使用16进制来操作的话,结果就很容易查看了,整数2130776063对应的16进制为0x7F010FFF,代码如下:
fun main() {val value: Int = 0x7F010FFFval bytes = ByteArray(4)bytes[0] = (value ushr 24).toByte()bytes[1] = (value ushr 16).toByte()bytes[2] = (value ushr 8).toByte()bytes[3] = (value ushr 0).toByte()bytes.forEachIndexed { index, byte ->// 把byte转换为等价的正数int值,以防byte是负数的情况val byteValue = byte.toInt() and 0xFFprintln("bytes[${index}] = ${Integer.toHexString(byteValue)}")}
}
输出结果如下:
bytes[0] = 7f
bytes[1] = 1
bytes[2] = f
bytes[3] = ff
我们说16进制中的每两位对应一个字节,则0x7F010FFF可以分为:7F、01、0F、FF,与上面的打印结果是对应的,这样我们很容易就能得出结论,我们写的代码获取一个int整数的每一个字节的代码是正确的,也就是说我们的代码是可以正确获取到int的每一个字节了。
二进制的操作:Bitwise operations(逐位运算)
逐位操作汇总
- 左移:
shl(signed shift left,有符号左移) - 右移:
shr(signed shift right,有符号右移) - 无符号右移:
ushr(unsigned shift right,无符号右移) and逐位与,两位都为1,结果为1,否则为0or逐位或,其中1位为1,结果为1,否则为0xor逐位异或,只有1位为1,结果为1,否则为0inv()逐位反转,1变0,0变1
Bitwise operations可以翻译为逐位运算,也可以翻译为按位运算,Bitwise operations只能应用于Int和Long类型。
左移
左移很少使用,它就是把二进制向左边移动,左边移出去的就不要了,右边空白的地方就补0,示例图如下:
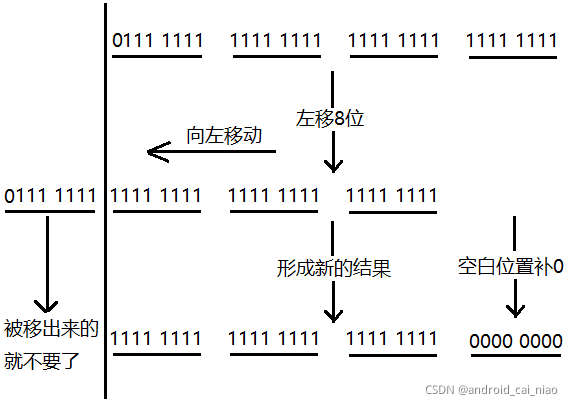
左移8位的简化图如下:
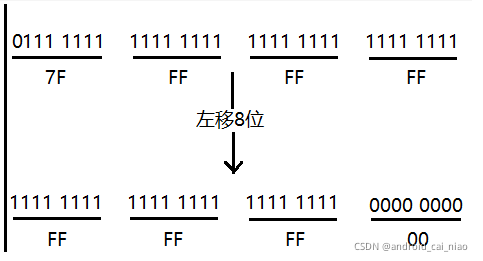
我们前面说了,一般我们不使用二进制形式,太长了,而是使用16进制代替,如上图所示,原值为:0x7FFFFFFF,左移8位后值为:0xFFFFFF00
示例代码如下:
fun main() {val value: Int = 0x7FFFFFFFval newValue: Int = value shl 8 // 左移8位println("原int值为:0x${intToHex(value)}")println("新int值为:0x${intToHex(newValue)}")
}/** 把int转换为16进制形式的字符串 */
fun intToHex(value: Int): String {return String.format("%08x", value.toLong() and 0xFFFFFFFF).uppercase(Locale.getDefault())
}
打印结果如下:
原int值为:0x7FFFFFFF
新int值为:0xFFFFFF00
无符号右移
无符号右移和左移是正好相反的,把二进制位向右移动,右边移出去的就不要了,左边空白的位置就补上0,示例图如下:
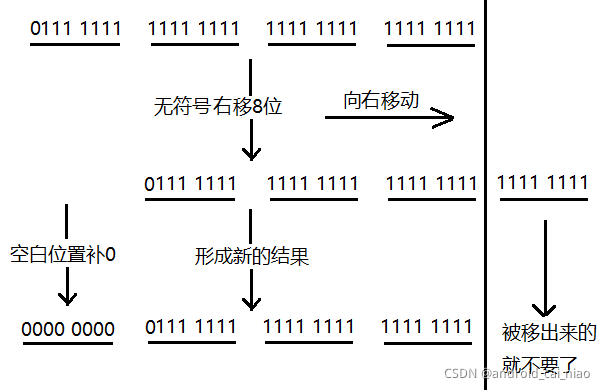
无符号右移8位的简化图如下:
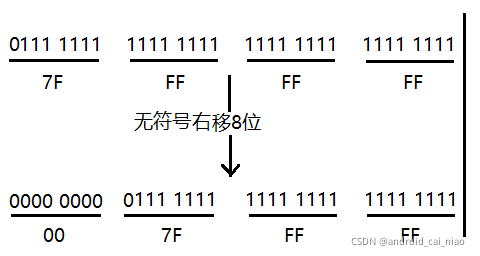
原值的16进制为0x7FFFFFF,无符号右移8位后值为:0x007FFFFF,示例代码如下:
fun main() {val value: Int = 0x7FFFFFFFval newValue: Int = value ushr 8 // 无符号右移8位println("原int值为:0x${intToHex(value)}")println("新int值为:0x${intToHex(newValue)}")
}
运行结果如下:
原int值为:0x7FFFFFFF
新int值为:0x007FFFFF
右移
右移操作也很少使用,无符号右移用的比较多。
右移和和无符号右移很像,都是向右移动,不同点在于,无符号右移时,空白的地方补0,而右移时,空白的地方补符号位。符号位为二进制中最左边的那一位,示例图如下:

这里有个小知识点,我在Kotlin的代码中(Java代码没有实验),无法使用如上的二进制来表示-3,使用对应的16进制也不可以,示例代码如下:
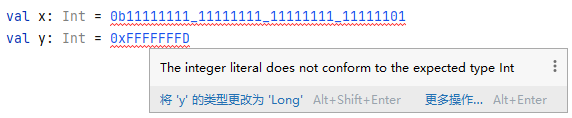
显示的异常信息为:
The integer literal does not conform to the expected type Int
对应的中文翻译如下:
整型字面值不符合预期的Int类型
至于为什么不允许这么写我也搞不懂,或许是因为在代码中,负数是要使用负号的符号来表示,如果没有负号就认为是正数。在代码中-3的表示方式如下:
val x: Int = -0b11
val y: Int = -0x03
如上代码,一个是以二进制的方式表示-3,一个是以16进制的方式表示-3。
-3右移8位的示例图如下:
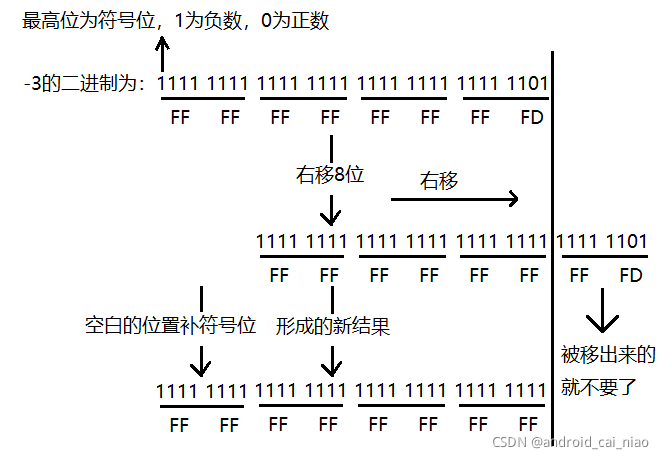
示例代码如下:
fun main() {val value: Int = -0x3val newValue: Int = value shr 8 // 右移8位println("原int值为:0x${intToHex(value)}")println("新int值为:0x${intToHex(newValue)}")
}
运行结果如下:
原int值为:0xFFFFFFFD
新int值为:0xFFFFFFFF
与:and
两个位都是1时结果为1,否则为0,示例如下:
1 and 3 = 1,画图分析如下:
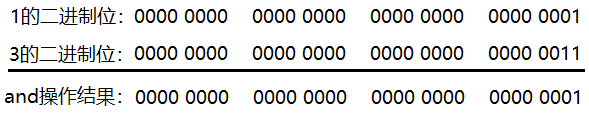
如上图,把1和3的二进制位进行与操作,只有最右边的二进制位都是1,所以两个1与的结果还是1,其它位置的二进制位与操作结果都是0,所以最终结果为00000000000000000000000000000001,对应十进制结果为:1。
或:or
其中1个位为1时结果为1,否则为0,示例如下:
1 or 3 = 3,画图分析如下:
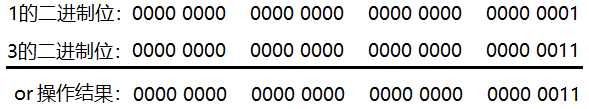
如上图,把1和3的二进制位进行或操作,只要有1的二进制位结果就是1,所以最终结果为00000000000000000000000000000011,对应十进制结果为:3。
异或:xor
只有1个位为1,结果为1,否则为0,示例如下:
1 xor 3 = 2,画图分析如下:
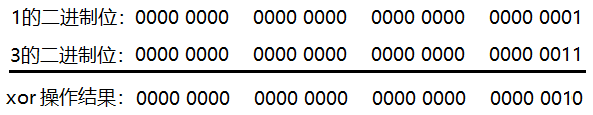
如上图,把1和3的二进制位进行异或操作,结果为00000000000000000000000000000010,对应十进制结果为:2。
反转:inv()
这是一个函数,正如名字的含义,它会把1变为0,把0变为1,示例如下:
fun main() {val number = 0b0000_0000_0000_0000_1111_1111_1111_1111val result = number.inv()println("反转后的二进制为:${Integer.toBinaryString(result)}")
}
运行结果如下:
反转后的二进制为:11111111111111110000000000000000
二进制的常见操作
1. 获取一个整数的最后1个字节的值
比如,获取一个int的最低1个字节的值,比如获取整数123321的最低1个字节的值,可以通过位移操作也可以通过位运算操作来实现,如下:
通过位移操作实现:

如上图,可以看到画红线的为最低1个字节的8个位的数据内容,通过位移操作把高3个字节的内容移出去,只保留最低1个字节的内容,即:1011 1001,对应的十进制值为:185。
通过位运算操作实现:

如上图,通过and 0xFF,同样实现了只保留最低1个字节的数据。
代码实现如下:
fun main() {val number = 123321println(number shl 24 ushr 24)println(number and 0xFF)
}
运行结果如下:
185
185
2. 获取一个整数的低位第2个字节的值
比如,有一个整数为:11694950,它对应的二进制位如下:
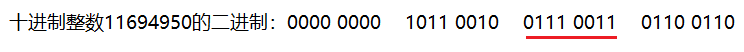
如上图,我们希望获取画红线的字节内容,实现代码如下:
fun main() {val number = 11694950val result = number and 0x0000FF00 shr 8println("需要的二进制内容为:${Integer.toBinaryString(result)},对应的十进制值为:$result")
}
运行结果如下:
需要的二进制内容为:1110011,对应的十进制值为:115
3. 把byte当成无符号整数打印
这个应用和前一个应用(即1. 获取一个整数的最后1个字节的值)是一样的,但是可以加深大家对二进制操作的理解。
在开发当中,byte数据类型也是很常用的,但是在java中,byte是有符号的,表示的数值范围为:-128 ~ 127。byte是没有无符号形式的,如果有无符号的话,则byte可以表示:0 ~ 255。我们在使用一些工具软件查看文件的二进制时,都是以无符号形式查看,所以查看到的内容不会有负数。这是使用了别人的工具来查看,有时候我们需要在代码中打印出这些byte值,也希望以无符号打印,也不希望看到负数,该如何实现呢?
比如:byte类型的-1,它对应的二进制为:1111 1111。二进制的8个1就表示-1,如果是无符号的话,这8个1表示的就是255,所以我们希望打印的时候看到的是255,而不是-1,这同样可以通过位移或与操作实现,实现原理就是把byte转换为int,然后只保留最低1个字节的内容即可,画图如下:
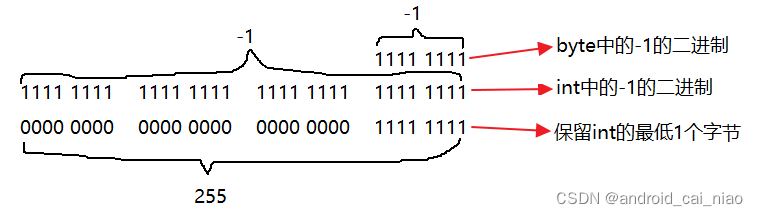
示例代码如下:
fun main() {val aByte: Byte = -1val aInt: Int = aByte.toInt()println(aInt and 0xFF)
}
运行结果如下:
255
在Java中,是要进行这样的操作的,而在Kotlin中,有一个UByte类型,即无符号Byte,可以直接使用,如下:
fun main() {val aByte: Byte = -1println(aByte.toUByte())
}
运行结果如下:
255
4. 获取一个整数的4个字节
把int整数的4个字节分别获取到。有了前面的基础,这里就不多说了,直接上代码,如下:
fun main() {val value: Int = 2130776063val bytes = ByteArray(4)bytes[0] = (value ushr 24).toByte()bytes[1] = (value ushr 16).toByte()bytes[2] = (value ushr 8).toByte()bytes[3] = (value ushr 0).toByte()bytes.forEachIndexed { index, byte ->// 把byte转换为等价的正数int值,以防byte是负数的情况val byteValue = byte.toInt() and 0xFFprintln("bytes[${index}] = $byteValue")}
}用16进制理解输出流的write函数
输出流的write(int b)函数是比较常用的,那它是写出去的是几个字节呢?示例如下:
fun main() {val value: Int = 0x7F010FFFval baos = ByteArrayOutputStream()baos.write(value)val bytes = baos.toByteArray()printBytesWithHex(bytes)
}/** 使用16进制的方式打印字节数组 */
fun printBytesWithHex(bytes: ByteArray) {bytes.forEachIndexed { index, byte ->println("bytes[${index}] = 0x${byteToHex(byte)}")}
}/** 把字byte转换为十六进制的表现形式,如FF、0F */
fun byteToHex(byte: Byte): String {// 2表示总长度为两位,0表示长度不够时用0补齐,x表示以十六进制表示,与上0xFF是预防byte转int前面多补的1清空为0,只保留1个低字节return String.format("%02x", byte.toInt() and 0xFF).uppercase(Locale.getDefault())
}
运行结果如下:
bytes[0] = 0xFF
从结果可以得出结论,write(int b)是把int值的最低位的那个字节的内容写出去了,另外三个字节没有写出去。
假如我就想把一个int的4个字节都写到文件保存起来,怎么办?这时可以使用DataOutputStream,示例如下:
fun main() {val value: Int = 0x7F010FFFval baos = ByteArrayOutputStream()val dos = DataOutputStream(baos)dos.writeInt(value)val bytes = baos.toByteArray()printBytesWithHex(bytes)
}
运行结果如下:
bytes[0] = 0x7F
bytes[1] = 0x01
bytes[2] = 0x0F
bytes[3] = 0xFF
可以看到DataOutputStream的writeInt()函数无非就是把一个int值的4个字节依次写出去而已,也没什么神奇的,了解了这个原理,其实我们也可以通过位操作符取出一个int值的4个字节,然后只使用普通的OutputStream就可以把一个int值写出去了。
很久很久以前,我在使用DataOutputStream的时候,一不小心使用到了ObjectOutputStream,这时就出了问题,因为写出去的int再读取回来时抛异常了,如下:
fun main() {val value: Int = 0x7F010FFFval baos = ByteArrayOutputStream()val oos = ObjectOutputStream(baos)oos.writeInt(value)val bytes = baos.toByteArray()printBytesWithHex(bytes)val bais = ByteArrayInputStream(bytes)val ooi = ObjectInputStream(bais)val intValue = ooi.readInt()println("intValue = 0x$intValue")
}fun intToHex(value: Int): String {return String.format("%08x", value.toLong() and 0xFFFFFFFF).uppercase(Locale.getDefault())
}
运行结果如下:
bytes[0] = 0xAC
bytes[1] = 0xED
bytes[2] = 0x00
bytes[3] = 0x05
Exception in thread "main" java.io.EOFExceptionat java.base/java.io.DataInputStream.readInt(DataInputStream.java:397)at java.base/java.io.ObjectInputStream$BlockDataInputStream.readInt(ObjectInputStream.java:3393)at java.base/java.io.ObjectInputStream.readInt(ObjectInputStream.java:1110)at cn.android666.kotlin.BinaryDemoKt.main(BinaryDemo.kt:16)at cn.android666.kotlin.BinaryDemoKt.main(BinaryDemo.kt)
可以看到,通过ObjectOutputStream写出的int值根本就不是整数0x7F010FFF的4个字节的内容,那打印的4个字节是什么东西啊?而且后面抛了一个异常,并没有打印出我们读取的int值,一个读一个写很简单的事啊,为什么会抛异常,而且也看不到我们写出的int值的内容啊?查看JDK文档发现ObjectOutputStream是用于写对象的,它是不是把一个int当成一个对象写出去了?是有可能的,但是一个写一个读,按道理是不会出异常的啊?几经思考后,我猜是不是ObjectOutputStream还没有把数据写到我们的内存流(ByteArrayOutputStream)中啊?于是,我们先把ObjectOutputStream流关闭,以确保它把所有数据都写出去了,然后再从ByteArrayOutputStream中获取数据,如下:
fun main() {val value: Int = 0x7F010FFFval baos = ByteArrayOutputStream()val oos = ObjectOutputStream(baos)oos.writeInt(value)oos.close() // 关闭ObjectOutputStream,以确保它把所有的数据都写到ByteArrayOutputStream中去了。val bytes = baos.toByteArray()printBytesWithHex(bytes)val bais = ByteArrayInputStream(bytes)val ooi = ObjectInputStream(bais)val intValue = ooi.readInt()println("intValue = 0x${intToHex(intValue)}")
}
运行结果如下:
bytes[0] = 0xAC
bytes[1] = 0xED
bytes[2] = 0x00
bytes[3] = 0x05
bytes[4] = 0x77
bytes[5] = 0x04
bytes[6] = 0x7F
bytes[7] = 0x01
bytes[8] = 0x0F
bytes[9] = 0xFF
intValue = 0x7F010FFF
OK,这次我们看到ObjectOutputStream一共写出了10个字节,最后的4个字节就是我们的整数0x7F010FFF的内容,至于前面的字节是什么东西我就懒得去管它了。
这里我们得到了一个经验:在使用包装流来包装ByteArrayOutputStream的时候,一定要先关闭包装流,再从ByteArrayOutputStream中获取数据,因为包装流在关闭的时候会确保把所有数据都写到ByteArrayOutputStream中去的。
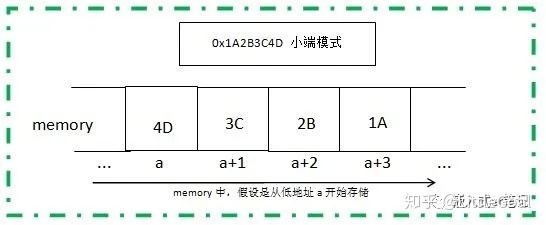
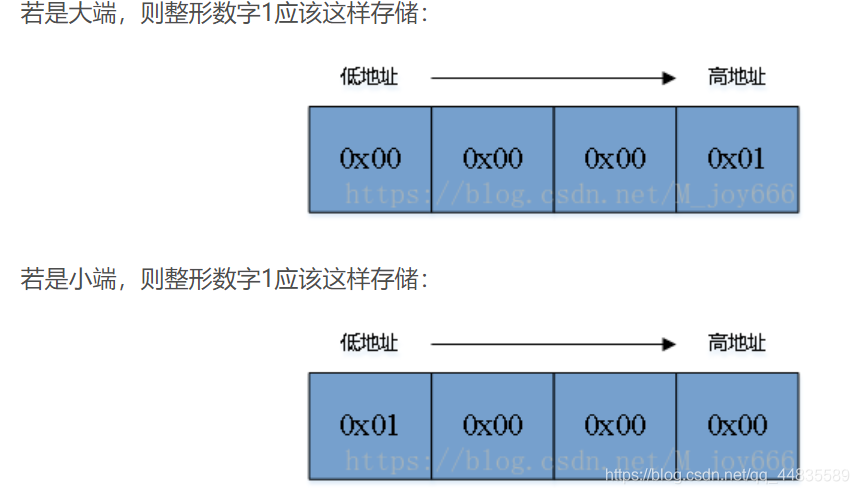
大端、小端
大端小端的百度百科:
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中
按照这个描述比较难以理解,我们首先得搞懂什么是数据的高字节,什么是内存的高地址?
我们看263的的节字内存图,如下:

总共两个字节,为了观看方便,我这里加入了一些空格,字节中的每个1对应的10进制值如下:
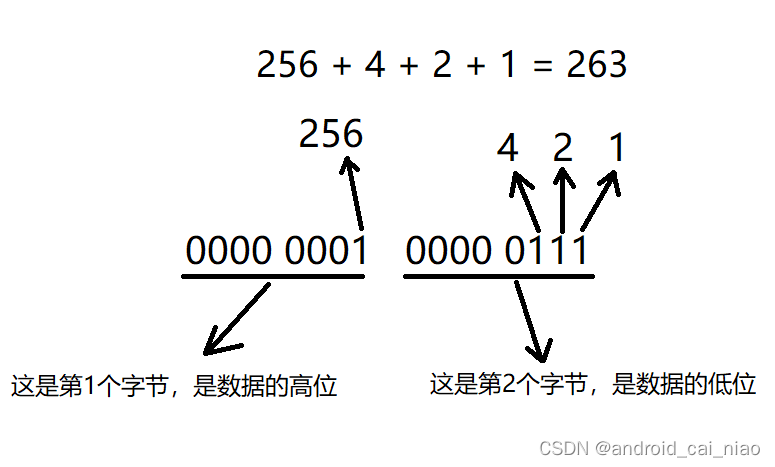
通过这张图片我们就能清楚的了解到,二进制中,左边的是数值的高位,右边是数值的低位,所以,二进制中左边的1表示的数值会比右边的1表示的数值大,这也是为什么把左边的称为高位,把右边称为低位的原因。
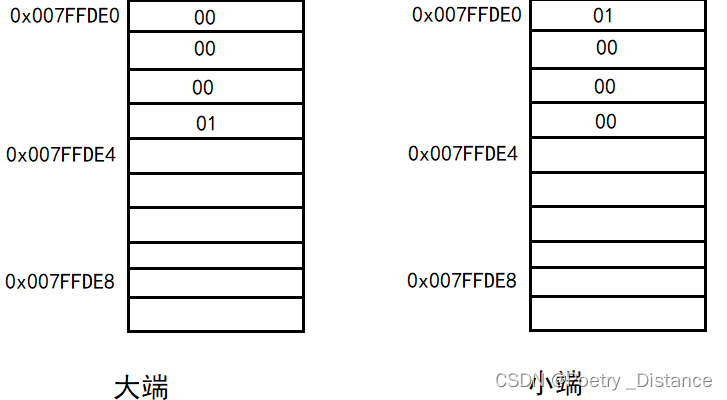
再来看什么是内存的高地址,我们假设创建一个大小为2的byte数组:byte[] array = new byte[2],内存图如下:
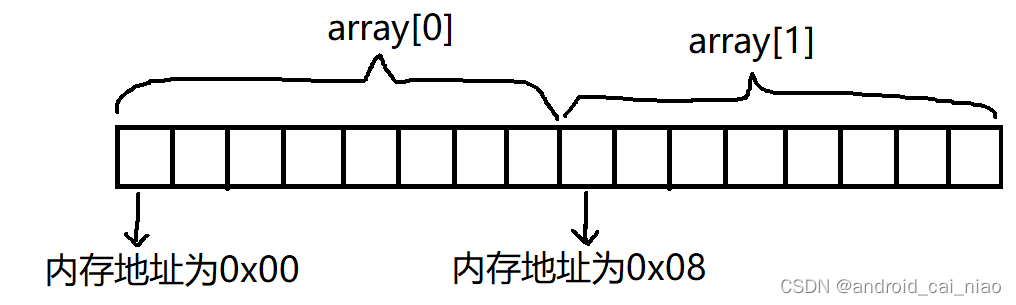
因为内存地址是连续的,假设内存中第一个 bit 的地址是0x00,第二个 bit 的地址则为0x01,因为每个字节有8个位,所以第二个字节的首地址为0x08,从数值大小来看,0x00 小于 0x08,所以我们说0x00是低地址,0x08是高地址。
了解了什么是数据的高字节,什么是内存的高地址,再来看大小端百度百科的定义:
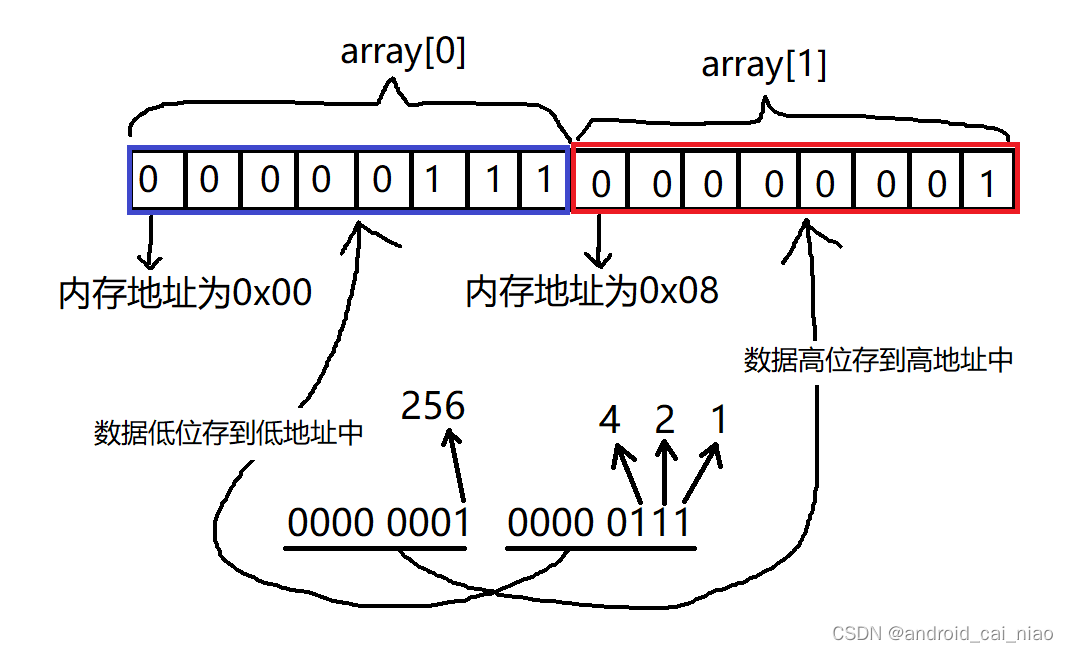
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中
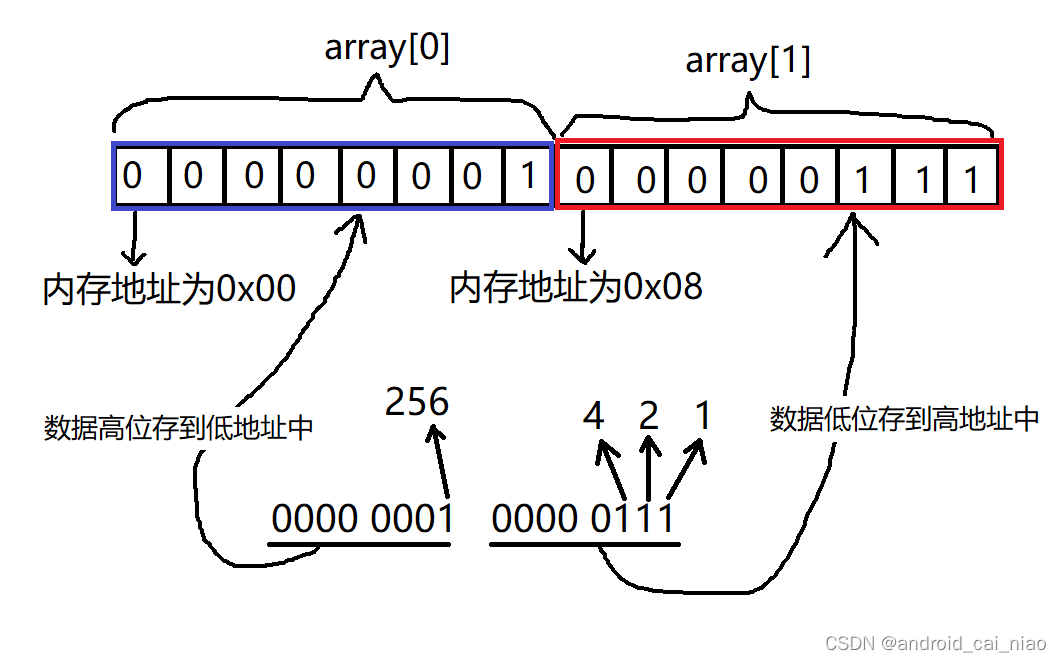
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中
小端存储示例图如下:
大端存储示例图如下:
数值的高位和低位还是比较容易理解的,但是高、低内存地址经常容易分不清,所以最好不要按百度百科的定义去记大小端,容易把自己脑子搞乱了,简单的理解大小端如下:
在保存数值的二进制字节时,如果先保存数值的高位,则是大端,如果先保存数值的低位则是小端。
这样就非常容易记忆了,先保存高位,对应大端,高对应大。先保存低位对应小端,低对应小。
大端、小端一般用于描述整型数据保存到文件时,以什么样的顺序保存,是先保存数据的高位,还是先保存数据的低位。如果这个数据不是一个整形数值,则没有大端、小端保存方式的说法。
代码示例如下:
我们取出一个int值的4个字节,4个字节分别保存了的int的从高位到低位的数据,如下:
fun main() {val value: Int = 0x7F010FFFval bytes = ByteArray(4)bytes[0] = (value ushr 24).toByte() // 取出数据中的最高位的7Fbytes[1] = (value ushr 16).toByte() // 取出数据中的01bytes[2] = (value ushr 8).toByte() // 取出数据中的0Fbytes[3] = (value ushr 0).toByte() // 取出数据中的最低位的FFbytes.forEachIndexed { index, byte ->println("bytes[${index}] = 0x${byteToHex(byte)}")}
}
运行结果如下:
bytes[0] = 0x7F
bytes[1] = 0x01
bytes[2] = 0x0F
bytes[3] = 0xFF
这是使用人们可以正常理解的顺序,从int的高位开始获取数据,从高位到低位的顺序获取的4个字节。
大端:保存时先保存int的高位再保存低位,示例如下:
fun main() {val value: Int = 0x7F010FFFval bytes = ByteArray(4)bytes[0] = (value ushr 24).toByte() // 取出最高位的7Fbytes[1] = (value ushr 16).toByte() // 取出01bytes[2] = (value ushr 8).toByte() // 取出0Fbytes[3] = (value ushr 0).toByte() // 取出最低位的FFval baos = ByteArrayOutputStream()// 大端方式保存int值,先保存高位再保存低位baos.write(bytes[0].toInt()) // 保存最高位的0x7Fbaos.write(bytes[1].toInt()) // 保存0x01baos.write(bytes[2].toInt()) // 保存0x0Fbaos.write(bytes[3].toInt()) // 保存最低位的0xFF// 打印保存后的字节内容baos.toByteArray().forEachIndexed { index, byte ->println("bytes[${index}] = 0x${byteToHex(byte)}")}
}
运行结果如下:
bytes[0] = 0x7F
bytes[1] = 0x01
bytes[2] = 0x0F
bytes[3] = 0xFF
可以看到,大端方式保存的结果和我们的正常逻辑理解是一样,即大端方式的数据比较容易理解:从int的高位数据到低位数据。
小端:保存时先保存int的低位再保存高位,示例如下:
fun main() {val value: Int = 0x7F010FFFval bytes = ByteArray(4)bytes[0] = (value ushr 24).toByte() // 取出最高位的7Fbytes[1] = (value ushr 16).toByte() // 取出01bytes[2] = (value ushr 8).toByte() // 取出0Fbytes[3] = (value ushr 0).toByte() // 取出最低位的FFval baos = ByteArrayOutputStream()// 小端方式保存int值,先保存低位再保存高位baos.write(bytes[3].toInt()) // 保存最低位的0xFFbaos.write(bytes[2].toInt()) // 保存0x0Fbaos.write(bytes[1].toInt()) // 保存0x01baos.write(bytes[0].toInt()) // 保存最高位的0x7F// 打印保存后的字节内容baos.toByteArray().forEachIndexed { index, byte ->println("bytes[${index}] = 0x${byteToHex(byte)}")}
}
运行结果如下:
bytes[0] = 0xFF
bytes[1] = 0x0F
bytes[2] = 0x01
bytes[3] = 0x7F
可以看到,小端的结果是不太容易理解的,因为你要倒过来组合数据,然后再算结果,如上面的结果,我们不能按正常顺序组装成:0xFF0F017F,而是要按倒序来组装成:0x7F010FFF。比如我们查看一个bmp文件时,以16进制方式查看二进制内容,如下:
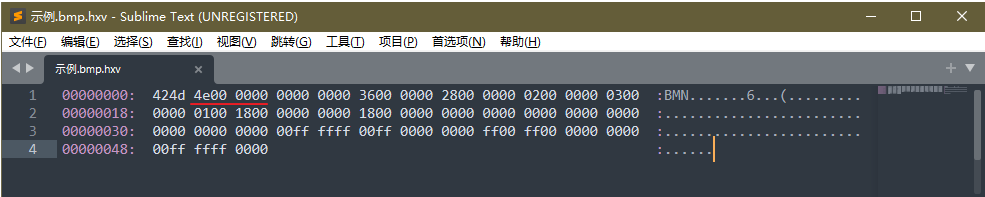
如上图,画红线的位置是bmp文件格式要求的用于保存文件大小的位置,而且要求是按小端的方式保存的,如果我们不知道小端的话,只知道那个位置的数据是表示文件大小的,则有可能会按正常顺序组装出这样一个16进制数:0x4E000000,它对应的十进制为:1308622848,这是错误的,这是一个很小的文件,不可能有这么大的。如果我们理解了小端,就知道要按倒序来组装为16进制:0x0000004E,可以简写为:0x4E,它对应的十进制为:78,也就是说这个bmp文件的大小为78字节,这才是正确的!
总结:
- 大端:保存时先保存int的高位再保存低位(正常顺序的理解方式)
- 小端:保存时先保存int的低位再保存高位(需要倒序来理解)
有时候经常会搞乱大端小端哪个先存哪个,用一个比较简单的方法,看名字就行,如下:
- 大端:大与高对应,则是先存数据的高位
- 小端:小与低对应,则是先存数据的低位
另外的小知识点:声明一个变量,运行代码时,变量是保存在栈内存中的,比如一个int类型的变量,它默认是以小端的方式保存还是以大端的方式保存在栈内存呢?根据和我们公司的大神交流,看到他在VSCode中可以直接查看运行的C代码的程序的栈内存地址,可以直接查看程序中变量的内存,C中的变量是以小端的模式存储在栈内存中的,Java也是一样。一般Windows系统下的文件中的数据都是以小端模式保存的,这里说的数据是指整形数据,比如bmp文件和wav文件,它们的文件头中有表示数据长度的头信息,都是以小端方式存储的。
另外可查阅ByteOrder的JDK文档,ByteOrder.nativeOrder() 可获取底层平台的本机字节顺序,即获取大小端。另外它还有两个常量,如下:
ByteOrder.BIG_ENDIAN表示 big-endian 字节顺序的常量。按照此顺序,多字节值的字节顺序是从最高有效位到最低有效位的。ByteOrder.LITTLE_ENDIAN表示 little-endian 字节顺序的常量。按照此顺序,多字节值的字节顺序是从最低有效位到最高有效位的。
ByteOrder用于ByteBuffer,所以,如果要指定以大端或是小端来保存数值时,可以使用ByteBuffer,以便可以指定大、小端。关于ByteBuffer的使用可以查看我的另一篇文章:https://androidblog.blog.csdn.net/article/details/109855062
使用ByteBuffer来指定大小端存储,示例如下:
fun main() {val buffer = ByteBuffer.allocate(8)buffer.order(ByteOrder.LITTLE_ENDIAN) // 设置以小端的方式存在整数值val intA = 0x11223344val intB = 0x0ABBCCDD // 最前面为什么不用AA,因为用AA超出Int最大值了会变成Long类型buffer.putInt(intA)buffer.putInt(intB)buffer.array().forEach {print("${byteToHex(it)} ")}
}fun byteToHex(byte: Byte) = String.format("%1$02X", byte)
输出结果为:
44 33 22 11 DD CC BB 0A
如果要写到文件,则需要使用Channel类来把ByteBuffer写出去。
在调用ByteBuffer的putInt或putLong函数时大小端才会生效,如果是put一个Byte进去,或者put一个byte数组进去,它是不会修改你的顺序的,因为它不存在大小端说法,只有你在put一个多字节的整数时才会有大小端说法。