该节知识点引用机械工业出版社数据结构和算法分析第2章内容
以及极客时间数据结构和算法部分知识点

时间复杂度基础分析
算法执行时间分析
时间复杂度分析更多的是对要编写的代码进行一个事前预估分析的一个过程,通过事前大致分析出算法执行的时间和所需要的空间(空间复杂度分析)从而在事前对代码进行调整优化,确保代码的质量。
与事前分析法对用的是事后分析法,事后分析法通过代码在执行后统计代码执行时间和所需要的的资源,但是该方法存在一个不确定性的问题,不同代码在不同配置的计算机上的执行时间可能会不尽相同,而最终得到的结论也是不同的,会存在偏差。
算法的执行效率大致的来说便是算法执行的时间,这里我们通过大O表示法来衡量算法的优劣,O越低的算法执行时间便越低,通常的时间量有O(1),O(n),log(n),O(n2),O(n3),等。在代码中一条语句的时间复杂度是O(1),那么是不是可以得到一个结论一个相同的代码执行n此(有限次)那么这条代码的时间复杂度便是O(n)。
O(1):一个常量级时间复杂度
int x=0;
O(n):线性级时间复杂度:
int sum=0;
for(int x=0;x<n;x++){sum +=1;
}
上述代码时间复杂度分析:我定义一个常量级时间复杂度为一个un_time,注意我们讨论的n是有限次的n。
-
第一行代码:
int sum = 0执行了一次为1个un_time。 -
第二行代码:
for(int x=0;x<n;x++)x=0自增到n(不满足条件退出循环)一共执行n次拿就是n*un_time。 -
第三行:
sum +=1; 注意这里的执行次数是由for循环控制的,那么是不是可以认为我for循环执行了几次第三行就执行了几次,那么是不是就是n*un_time。 -
现在我们把上述代码的时间复杂度相加便得到整个代码块的时间复杂度(定义为T(n))T(n)=un_time+nun_time+num_time = (2n+1)*un_time
O(n^2):平方级时间复杂度:
int sum = 0;
for(int x=0;x<n;x++){for(int y=0;y<n;y++){sum +=1; }
}
上述代码时间复杂度分析:
-
第一行代码:执行了一次花费了一个un_time。
-
第二行代码:x从0变化到n执行了n次那就是 n*un_time。
-
第三行代码:这里是重点(和第4行一起分析了)当x=0的时候执行n次,x=1执行n次,x=1时执行n次,x=2时执行n次,x=3时执行n次,那么是不是可以推断出当x=n时执行n*n次,4和4加起来就是(2n^2)*un_time次。
-
那么总的时间复杂度就是 T(n) = un_time+n*un_time+(2n^2)*un_time = (2n^2+n+1)*un_time
下面对上述代码进行变形:这次我们尝试分析最后一句的语句进行频度
int sum = 0;
for(int x=1;x<=n;x++){for(int y=1;y<=x;y++){sum +=1;}}
对于上面的代码我们根据O(n2)的时间复杂度分析可以得到一个粗略的值是O(n2)(这里只是一个粗略的估算值,并不是精确值 但是为什么可以取O(n^)后面将会讨论),那么想在 提出的问题是不是计算他的总的时间复杂度而是分析第4行代码的语句执行频度(该行语句的层数是最深的所以执行次数也是最多的,他的执行次数加上2,3行的代码执行次数便是整个代码的精确执行次数)分析:
-
x=1 --> 1次
-
x=2 --> 2次
-
x=3 --> 3次
-
…
-
x=n -->n次
-
可以推出 该语句的执行次数是一个等差数列 a1=1,d=1 通过下述公式计算得语句执行次数为S(n)= (n^2+n)/2;
我们再次对上式进行变形:再次分析sum=sum+1 表达式的语句执行频度
int sum = 0;
for(int x=0;x<=n;x++){for(int y=0;y<=x;y++){sum = sum+1;}
}
我们对上述代码进行分析:
-
x=0 --> 1
-
x=1 --> 2
-
x=2 --> 3
-
x=3 --> 4
-
…
-
x=n --> n+1
我们发现x的变化过程,影响着代码的执行次数 当x=0时代码执行一次,当x=1时代码执行2次那么当x=k(k != n)时代码执行k++次,那么我们将x每次变化的次数相加是不是就能够得到整个执行过程的执行次数,这里我们引用一个数学上的级数公式(下图),我们根据该公式进行求解:


通过对T(n) 的计算得到了sum +=1 的代码执行频度是(n+1)*(n+2)/2
O(n^3):立方级时间复杂度:
int sum = 0;
for(int x=0;x<n;x++){for(int y=0;x<n;y++){for(int k=0;k<n;k++){sum = sum+1; } }
}
我们看到上述代码比平方阶多了一层for循环嵌套,通过对O(n2)的计算或许我们能够很快的就计算出T(n)=un_time+n*un_time+n2un_time+n3*un_time+n3un_time 对表达式进行整理:
我们再次对上述代码进行变形:请计算出sum=sum+1的语句执行频度
int sum = 0;
for(int x=1;x<=n;x++){for(int y=1;y<=x;y++){for(int k=1;k<=y;k++){sum = sum+1;}}
}
我们发现这个变形代码和上面的代码不同的是他的判断结束条件变了,我们尝试跟踪一下他的执行次数(这里我跟踪的是x的值,执行次数是sum=sum+1)
下面这个图片引用CSDN博客的图片:图片中的i是代码中的x ,j是代码中的y
https://blog.csdn.net/qq_37922264/article/details/103583387?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param

-
x=1 --> 1
-
x=2 --> 3
-
x=3 --> 6
-
x=4 --> 10
-
x=i --> i(i+1)/2
根据上述推导可以得到级数公式:

对级数公式进行推导计算:

我们通过对线性阶,平方阶,立方阶,甚至是4次方阶我们计算其时间复杂度是预测计算取最大值(可以说是最坏情况),在我们精确计算出的数据中我们去其中 最大值最为这个算法的执行时间复杂度例如:三次方阶的标椎代码其时间复杂度我们可以估算为是O(n3),有一个问题我们为什么能够将算法的时间复杂度进行一个估算?在线性阶中一个O(1)相对于一个O(n)那么这个O(1)是不是非常的小,那么这个大O(1)我们是不是可以忽略不计(注意在排序中当一个常量级时间*一个log级时间的时间复杂度是不能进行忽略计算的),那么在O(n3)立方阶中我们是不是也可以取最大值作为整个代码块的时间复杂度。
这里有一点需要注意的是在常量阶中不论赋值语句有多少行,if,switch,等语句有多少都是按照一个O(1)来计算的,只要代码不随n的增长而增长这样的代码便可以记做O(1)
下面我们讨论一下对数(log)阶,对数阶相对于线性阶其算法执行效率,执行时间要更占优(但是个人觉得log阶的时间复杂度也是最难分析的)log阶默认的底都为2如有其它参数作为底请进行特殊标记。
O(logn):对数阶:
int x=1;
while(x<=n){x *= 2;
}
从代码中我们可以看出,变量x取值从1开始当x的值大于n时循环结束,那么当x=n 时第三行代码则执行最后一次,通过x的取值变化可以发现他是一个等比数列(2的指数值是该项前面有一个项),那么x的值是不是就是代码的执行次数,2^x = n --> x=logn

假设现在对x值得变化进行一个改变令 x *=3 那么执行次数是不是就变成了:‘’

那么他的时间复杂度是不是就是 T(n)= log3(n)
我们知道,对数之间是可以互相转换的,log3n 就等于 log32 * log2n,所以 O(log3n) = O(C * log2n),其中 C=log32 是一个常量。基于我们前面的一个理论:在采用大 O 标记复杂度的时候,可以忽略系数,即 O(Cf(n)) = O(f(n))。所以,O(log2n) 就等于 O(log3n)。因此,在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,统一表示为 O(logn)
2019年考研算法时间复杂度分析题解析:
题目:设 n 是描述问题规模的非负整数,下列程序段的时间复杂度
x=0;
while(n>=(x+1)*(x+1))
)x=x+l;解析:代码中使用的是while循环所以我们需要观察x和(x+1)2的变化值和当(x+1)2何时等于n时程序第三行最后执行一次(当(x+1)2>n时程序结束),当找到(x+1)2的值等于n时,该项前面有几项就是程序的执行频度(时间复杂度):x --> (x+1)^2
-
0 – > 1
-
1 --> 4
-
2 --> 9
-
3 --> 16
-
4 --> 25
-
5 --> 36
-
…
-
n --> (n+1)^2
我们运用数学归纳法对数据值进行分析:当(x+1)2=4时程序执行了2此,当(x+1)2=9时程序执行了3次,当(x+1)2=5时程序执行了6次,由此我们是不是暂时得到一个结论当我们(x+1)2的值取根号计算得到代码执行次数,由数学推论法中的特殊性得到普遍性,对(x+1)^进行去根号计算可以得 到代码执行次数,应为(x+1)^2等于n所以可以得出算法执行的时间复杂度为:
加法法则
加法法则:总的时间复杂度等于量级最大那段代码的时间复杂度
//代码片段一
int sum1 = 0;
for(int x=0;x<1000;x++){sum1 +=1;
}//代码片段二
int sum2 = 0;
for(int x=0;x<n;x++){sum2 += 1;
}//代码片段三
int sum3 = 0;
for(int x=0;x<n;x++){for(int y=0;y<n;y++){sum +=1;}
}
现在我们是不是能够很快的计算出整个代码块的时间复杂度?代码片段一:O(1),代码片段二:O(n),代码片段三:O(n^2),这里有点需要注意的是代码片段一中的代码循环个了1000次是一个常量级执行时间和n没有关系所以时间复杂度是O(1),这里再次强调一下即使代码片段循环执行10000次,20000次他都是一个常量级时间跟n没有关系,n是一个变化的值他可能是100000或者是1000或者是一个无限大的值当n的值越大的时候对算法的执行时间影响就越大,当我们回到时间复杂度分析的概念来说他分析的是算法的执行效率和数据规模之间的关系,其中体现的是数据规模的变化对算法执行效率的影响而常量值是确定的值,所以在计算算法时间复杂度是O(1)常量级时间复杂度可以忽略不计。
现在我们将上述三个代码段的时间复杂度抽象为公式:
我们对上述公式运用加法法则进行计算:
结论:算法总的时间复杂度等于量级最大的那段代码的时间复杂度。
乘法法则
乘法法则:嵌套代码的复杂度等于嵌套内外层代码复杂度的乘积
//代码片段一
int cal(int n){int sum = 0;for(int x=0;x<n;x++){sum += f(x); }
}//代码片段二
int f(int n){int fel = 0;for(int x=0;x<=n;x++){fel +=x;}return fel;
}
现在我们能够很快分析出代码片段一和代码片段二的算法执行的时间复杂度:T1(n) = O(n) ;T2(n) = O(n) ,现在我们假设T1(n) = G(n),T2(n) = C(n),由乘法法则我们可以得到以下的抽象公式:
由上述公式我们可以得到上述算法执行的时间复杂的是O(n^2),当我们在计算多个函数的嵌套的时间复杂度时需要一层一层 去解析函数,不能以一个常量的时间复杂度去计算。
总结:嵌套代码的复杂度等于嵌套内外层代码复杂度的乘积
内容小结
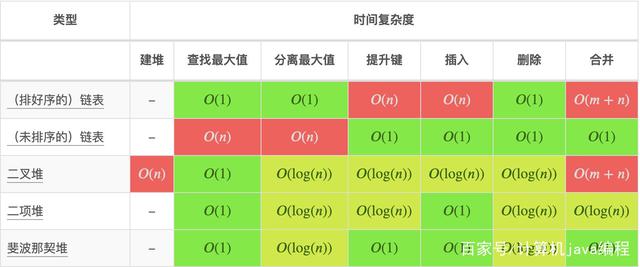
复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度是用来分析数据规模算法执行效率之间的关系,越高阶的算法时间复杂度越低,算法的时间复杂度可以粗略的表示。我们常用的算法时间复杂度主要有(从左到右排列表示其大小):
时间复杂度分析图:
图片引用自即极客时间的数据结构和算法之美的课程图片(画得比较好看)

摊还分析法和平均分析法
上面几节我们分析了算法执行的时间复杂度,现在我们将要讨论一下算法执行的最好情况,最坏情况了,平均情况,均摊情况。对算法的最好情况,最坏情况的分析主要是对数据规模,以及数据分布特性的分析,应为数据分布的不同导致的算法时间复杂度的不同。
最好情况
我们先看下面这段代码:
//代码片段一
int[] array = new int[]{1,5,3,7,9,0};
public int search(int key){int pos = 0;for(int x=0;x<array.length;x++){if(array[x] == key){pos = x;break;}}return pos;
}
在代码片段一中定义了一个search函数其功能主要是在array数组中查找值为key的数据,当查找到该数据后便返回该数据在array数组中的位置,然后调用break结束循环。
这时我们讨论一个问题:当我们要查找数据1在array中的位置对应的函数参数是search(1),此时我们先观察数据1在数组中并且在位置0处,当for循环的x值为0的时候就能查找到该元素并且结束循环保存x的值,我们发现此时for循环只执行了一次那么整个代码的时间复杂度是不是就是O(1)。
由上述分析我们可以得到一个结论:最好时间复杂度就是,在理想情况下这段代码执行的时间复杂度(这个理想的时间复杂度会跟随数据的规模和分布特性而发生改变)。
最坏情况
最坏时间复杂度我们借助最好时间复杂度的代码片段一进行分析:
假设现在我们要查找数据0(假设数组中的数据是唯一的没有重复值),对应的代码search(0),我们观察数据0位于数组的最后一位,当使用for循环查找数据元素便需要遍历n次才能找到数据0的位置,那么可以推出此时的时间复杂度是O(n)。
总结:最坏时间复杂度就是,在最糟糕的情况下,执行这段代码的时间复杂度。
平均情况
我们分析过最好,最坏时间复杂度,但是两者都是处于一种极端情况,发生的概率不大。为了更好的表示程序执行的时间复杂度我们引入平均情况时间复杂度。我希望代码的时间复杂度趋于一种稳定状态不是最好也是最差。
我们要查找数据元素key在数组中的位置,有n+1种情况,该元素在0-n-1种和元素不在数组中,那么我们将所有可能发生的情况除以总情况数是不是就可以得到整个查找过程的时间复杂度?下面我们来分析一下:
在O标记法中我们可以省略掉系数,低阶,产量及时间那么得到的最终结果值是0(n)
但是这个结果并不是准确的,虽然整个查找过程有n+1中情况但是每个情况发生的概率是不一样的,下面我们来分析一下:
-
查找成功和查找不成功的情况分别是:1/2的1/2;
-
查找成功是在0-n-1的概率是:1/n;
-
根据概率乘法得到查找成功的概率是:1/2n,不成功的概率是:1/2 结合所有情况可以得到如下公式:
根据上述公式得到的T(n)的值就是平均情况时间复杂度的值,我使用O表示法省略去系数,低阶,常亮值得到的依然是O(n)。
均摊情况
均摊时间复杂度和平均时间复杂度两者看起来很像但是是两个概念有细微的差别。大部分情况下我们不需要分析程序的最好,最坏,平均时间。而平均时间复杂度只有在特殊的情况下才会使用,均摊时间复杂度是在更特殊的情况下使用,对数据的要求更高。
下面我们分析一段代码来解释这一个过程:
代码引用自极客时间数据结构和算法之美的代码块(这个代码块能够更好的体现均摊时间情况)。
// array表示一个长度为n的数组
// 代码中的array.length就等于n
int[] array = new int[n];
int count = 0;
void insert(int val) { if (count == array.length) { int sum = 0; for (int i = 0; i < array.length; ++i) { sum = sum + array[i]; } array[0] = sum;count = 1; } array[count] = val; ++count;
}上述代码片段执行数据插入数组的一个功能,当数组为空时直接插入数组中,当数组满时先遍历数组计算整个数组中元素的和并将计算的结果存储入数组下标0位中,然后重置count变量,当还有数据插入时循环往复的执行上述步骤。
我们先来分析一下这个代码片段的平均时间复杂度:
这个代码块执行的过程总共有n+1中情况。当数组为空的情况下是我所期望的理想情况即都能够在O(1)的时间复杂度情况下完成插入操作,但是当数组满时这个是最坏情况我们需要花费O(n)的时间复杂度区遍历数组并且对数组进行求和操作,这里有一点需要注意的是每个情况发生的概率都是一样的(我只从插入数据的角度去观察,每次插入的过程都是一样的),可以得到如下的分析公式:
我观察一下insert插入函数和find查找函数的不同:
-
find查找函数在极端情况下是0(1),而insert函数在大多数情况下是O(1),只有在极少数情况下是O(n)
-
对于insert插入函数来说O(1)发生的概率是非常有规律的中是在n-1个O(1)后有一个O(n),然后在有n-1个O(1),后再是O(n),这个过程是循环有序有规律的,而find函数充满了不确定性可能是O(1)也可能是O(n)也可能是平均情况。
针对这种情况我们可以使用均摊时间复杂度进行分析,我们观察insert函数每一次操作O(n)操作后面都有n-1个O(1)操作,所有可以吧耗时较多的那次操作均摊到n-1次耗时低的操作上,那么这组连续的操作的均摊时间复杂度就都是O(1)了。
总结一下均摊时间复杂度分析:均摊时间复杂度分析要求对某一数据结构有一连续的操作,而且在该操作中大部分的情况下都是时间复杂度低的操作,只有少部分的操作是耗时操作,而且这些操作之间存在一个连续关系,这个时候我们就能够尝试将这一小部分的耗时操作均摊到耗时低的操作上面。一般情况下均摊时间复杂度就是最好时间复杂度。