我在Google Chrome Web Store上发布了一个案例hahaOCR,该扩展程序可以帮助用户识别出图片中的文字信息,并以文本形式显示,大家可以在chrome网上应用商店中找到我发布的应用程序,如图所示:

该扩展程序支持用户通过文件上传按钮上传图片,请看演示效果:


接下来,我们将在本文中详细讲解该案例所涉及的文件(图片)处理模块。
参考资料
- MDN Web Docs:https://developer.mozilla.org/zh-CN/docs/Web/API/FileReader
1. FileReader概述
该对象允许Web应用程序异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容,使用File或Blob对象指定要读取的文件或数据。其中File对象可以是来自用户在一个<input/>元素上选择文件后返回的FileList对象,也可以是来自拖拽操作生成的DataTransfer对象,还可以是来自一个HTMLCanvasElement上执行 mozGetAsFile()方法后返回的结果;Blob对象表示一个不可变、原始数据的类文件对象,它的数据可以按文本或二进制的格式进行读取,也可以转换成 ReadableStream来用于数据操作,Blob表示的不一定是JavaScript原生格式的数据,File接口基于Blob,继承了Blob的功能并将其扩展使其支持用户系统上的文件。
2. FileReader属性
为了更加直观的解释FileReader的三个属性,我们来看一段简单的代码:
<input type="file" id="file" onchange="readFile(this.files[0])">
window.readFile = (file) => {console.log(file)console.log(file.type)var reader = new FileReader()console.log(reader)
}
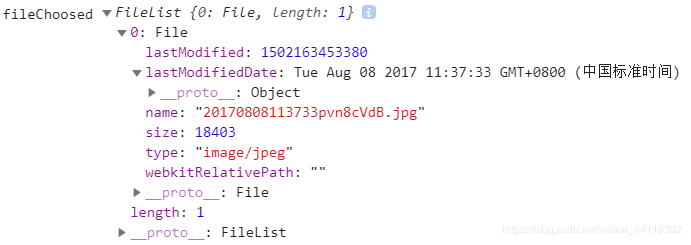
上述代码中,我们定义了一个文件上传按钮,我们只对用户上传的第一个文件进行处理,当用户完成上传操作之后,我们来看一下控制台输出的信息:

我们在上述代码中指定了三个console,第一个console输出了用户所上传文件的相关信息;第二个console输出了用户所上传文件的type;第三个console输出了FileReader实例的相关信息,请看解释:
-
FileReader.error(只读属性)
该属性表示在读取文件时发生的错误,图1中显示error值为null,表示在读取用户所上传文件时没有出错。 -
FileReader.readyState(只读属性)
该属性表示FileReader状态的数字,请看取值:
| 常量名 | 值 | 描述 |
|---|---|---|
| EMPTY | 0 | 还没有加载任何数据 |
| LOADING | 1 | 数据正在被加载 |
| DONE | 2 | 已完成全部的读取请求 |
图1中显示readyState值为0,因为我们并没有加载任何数据,尽管我们完成了图片的上传,但我们并没有指定任何方法来读取该图片文件。
- FileReader.result(只读属性)
该属性表示文件的内容,仅在读取操作完成之后才有效,数据的格式取决于使用哪个方法来启动读取操作,图1中result值为null,因为我们并没有指定读取当前所上传文件的方法,接下来,我们通过FileReader.readAsDataURL()方法来读取一下该图片,请看代码:
window.readFile = (file) => {var reader = new FileReader()console.log(reader)reader.readAsDataURL(file)reader.onload = (res) => {console.log(res)}
}
请看控制台信息:

上述代码中,我们通过FileReader.readDataAsURL()方法读取用户所上传的图片文件,当读取完成后,其result属性中将包含一个data:URL格式的Base64字符串以表示所读取文件的内容,关于读取用户所上传文件的更多方法,请参考第三小节。
3. FileReader方法
接下来,我们来看一下FileReader接口的几个方法:
| 方法 | 描述 |
|---|---|
| FileReader.abort() | 终止读取操作,在返回时,该属性的值为DONE |
| FileReader.readAsArrayBuffer() | 开始读取指定的Blob中的内容,一旦完成,result属性中保存的是被读取文件的ArrayBuffer数据对象 |
| FileReader.readAsBinaryString() | 开始读取指定的Blob中的内容,一旦完成,result属性中将包含所读取文件的原始二进制数据 |
| FileReader.readAsDataURL() | 开始读取指定的Blob中的内容,一旦完成,result属性中将包含一个data:URL格式的Base64字符串以表示所读取文件的内容 |
| FileReader.readAsText() | 开始读取指定的Blob中的内容,一旦完成,result属性中将包含一个字符串以表示所读取的文件内容 |
如上表所示,对于不同的文件我们可以采取不同的方法来完成读取操作,接下来,我们通过FileReader.readAsText()方法来读取一个文本,请看代码:

window.readFile = (file) => {var reader = new FileReader()console.log(reader)reader.readAsText(file)reader.onload = (res) => {console.log(res)}
}
请看演示效果:

4. FileReader事件
我们继续来看FileReader接口的几个事件处理方法:
| 方法 | 描述 |
|---|---|
| FileReader.onabort() | 处理abort事件,该事件在读取操作被中断时触发 |
| FileReader.onerror() | 处理error事件,该事件在读取操作发生错误时触发 |
| FileReader.onload | 处理load事件,该事件在读取操作完成时触发 |
| FileReader.onloadstart | 处理loadstart事件,该事件在读取操作开始时触发 |
| FileReader.onloadend | 处理loadend事件,该事件在读取操作结束时(成功或失败)触发 |
| FileReader.onprogress | 处理progress事件,该事件在读取Blob时触发 |
如上表所示,我们可以在用户上传文件的不同阶段指定不同的处理逻辑,请看代码:
<div class="example"><div class="file-select"><label for="avatar">Choose a profile picture:</label><input type="file"id="avatar" name="avatar"accept="image/png, image/jpeg"></div><img src="" class="preview" height="200" alt="Image preview..."><div class="event-log"><label>Event log:</label><textarea readonly class="event-log-contents" rows="20" cols="50"></textarea></div></div>
上述代码中,我们定义了一个文件上传按钮,具体来说是图片上传按钮;接着我们还定义了一个<img/>标签,其src属性值为空;最后,我们定义了一个文本输入框,用来显示不同事件处理程序读取图片文件的相关信息。
const fileInput = document.querySelector('input[type="file"]');
const preview = document.querySelector('img.preview');
const eventLog = document.querySelector('.event-log-contents');
const reader = new FileReader();function handleEvent(event) {console.log(event)eventLog.textContent = eventLog.textContent + `${event.type}: ${event.loaded} bytes transferred\n`;if (event.type === "load") {preview.src = reader.result;}
}function addListeners(reader) {reader.addEventListener('loadstart', handleEvent);reader.addEventListener('load', handleEvent);reader.addEventListener('loadend', handleEvent);reader.addEventListener('progress', handleEvent);reader.addEventListener('error', handleEvent);reader.addEventListener('abort', handleEvent);
}function handleSelected(e) {eventLog.textContent = '';const selectedFile = fileInput.files[0];if (selectedFile) {addListeners(reader);reader.readAsDataURL(selectedFile);}
}fileInput.addEventListener('change', handleSelected);
上述代码中,我们仅对用户上传的第一个图片文件进行处理(通过readAsDataURL方法读取);我们还通过EventTarget.addEventListener方法将FileReader指定的6种监听器(事件处理程序)注册到reader上;最后当触发load事件时,将读取成功之后的内容,即data:URL格式的Base64字符串赋值给空<img/>标签的src属性,并最终显示在页面中,请看演示效果:

5. 案例实战
最后,我们来看一下本文最开始提到的hahaOCR案例中的文件处理模块,实现该逻辑功能的思路其实很简单:用户通过按钮或拖拽操作上传图片,上传成功之后调用接口将图片中的文字信息显示在<textarea/>中,接下来,我们来看一下实现该功能的代码:
//此处是手动选择文件
$('#input').change(function() {event.preventDefault();var filesToUpload = document.getElementById('input').files;var img_file = [];for (var i = 0; i < filesToUpload.length; i++) {var file = filesToUpload[i];if (/image\/\w+/.test(file.type) && file != "undefined") {img_file.push(file);}}var reader = new FileReader();var AllowImgFileSize = 2100000; //上传图片最大值(单位字节)( 2 M = 2097152 B )超过2M上传失败var imgUrlBase64;if (img_file) {//将文件以Data URL形式读入页面imgUrlBase64 = reader.readAsDataURL(file);reader.onload = function (e) {if (AllowImgFileSize != 0 && AllowImgFileSize < reader.result.length) {alert( '上传失败,请上传不大于2M的图片!');return;}else{$.ajax({type: 'post',url: '***', //这里是数据请求接口dataType: 'json',data: {"showapi_appid": '***', //这里需要改成自己的appid"showapi_sign": '***', //这里需要改成自己的应用的密钥secret"base64":reader.result,},error: function(XmlHttpRequest, textStatus, errorThrown) {alert("操作失败!");},success: function(result) {var res = result.showapi_res_body.texts[0];console.log(res)$("#exampleFormControlTextarea1").val(res)}});}}}hahaOCR.prototype.getImageFile(img_file, filesToUpload.length);
});
上述代码中,我们限定了用户所上传图片文件的大小,并在文件上传成功时调用接口来对所上传的图片文件进行识别,识别成功之后,将图片中文字信息显示在<textarea/>中。
6. 文章最后
以上就是本文的所有内容,小伙伴们学会了嘛?快去实践一下吧!更多详情请关注我的更多开源作品:
1. 微信公众号(hahaCoder)

2. 微信小程序(hahaAI)

3. Github
链接地址:https://github.com/TURBO1002