Column-Stores vs. Row-Stores: How Different Are They Really?
论文阐述的就是行存与列存 两者之间到底有什么区别
Abstract
论文首先给出结论:列式存储(Column Stores)比行式存储(Row Stores)在性能上好过一个数量级。而这关键的原因就是:针对只读数据,列存的I/O效率远高于行存。因为他们只需要读取查询中涉及的一些列。
通常我们会想当然的认为对行存数据进行垂直分表、为每一列建索引,就可以在查询时,提高I/O效率,只查询部分列对应的数据,从而达到列存的速度。但是论文通过实验证明这个假设是错的。
论文首先用实验证明了行存相比与列存性能确实差了很多。然后论文分析了列存和行存之间的不同。包含两个方面:查询执行层面及存储层面。总结出列存主要存在以下几个优势:
- 延迟物化(Late materialization)
- 块遍历(Block iteration)
- 列压缩(Column-specific compression techniques)
同时如果行存想要达到列存这种性能优势,不仅要在查询执行层面进行优化,存储层面也需要进行优化。
Introduction
近些年(2008年)出现了很多列存系统,比如MonetDB,C-Store。这些作者说列存相比行存在读频繁的场景下性能可以提升一个数量级。但是这些列式系统的性能测试方式显然过于“传统”,仍然以行式存储下数据结构的设计思路来设计性能测试的方案。于是作者来了一个灵魂发问。
面向列的系统好于面向行的系统,是因为面向列的系统内在基础架构(个人觉得是列式的存储格式)导致的吗?传统的系统能否通过一些面向列的物理设计(通过一些手段来达到列式存储的效果)来达到面向列的系统的性能?
如何解答这个问题:
本文将通过 Star Schema Benchmark (SSBM) 典型的数仓测试拓扑结构,在面向行的系统中,模拟列存的设计范式,来解答上述疑惑。模拟列式范式的设计有:
- 表结构垂直拆分
- 全列索引+所有查询都走索引
- 所有查询都做物化视图
从最终的实验得出,在行式存储上就算以column-oriented方式来设计数据的物理结构,面对分析型场景还是无法与列式存储抗衡。面对分析型场景,列式存储在本质上优于行式存储。
这同时又提出一个新问题:
到底是什么优化使列存在数仓场景下有比行存更好的性能
主要优化如下:
- 延迟物化(Late materialization)
- 块遍历(Block iteration)
- 列压缩(Column-specific compression techniques)
- 隐式连接(invisible join)
第二个问题解决之后,那么随之而来的是第三个问题:
知道是这些优化手段使列存性能好于行存,但是每个优化点到底能带来多少性能上的提升
本文主要就围绕这3个问题展开,主要关注第2、3个问题
列存优势
压缩 Compression
为什么压缩就能带来查询的高效呢?压缩首先带来的硬盘上存储空间的降低,但是硬盘又不值钱。它的真正意义在于:数据占用的硬盘空间越小,查询引擎花在IO上的时间就越少(不管是从硬盘里面把数据读入内存,还是从内存里面把数据读入CPU)。但是这并不意味着压缩比越高,查的就越快,因为数据读入内存之后还需要进行解压。所以我们需要再压缩比和解压速度之间做一个权衡。
同时甚至在一些情况下不需要解压也能对数据进行处理。比如对于采用Run-Length编码方式进行压缩的数据。
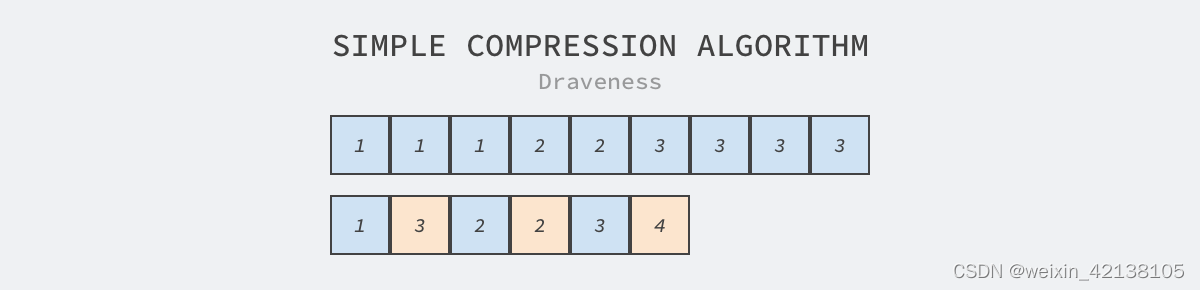
当你需要sum()时,直接1*3+2*2+3*4。当需要count()时,直接3+2+4。同时如果查询语句为where col = '3' 你只需要过滤 总行数/列的基数。当你的数据是有序的时,时间复杂度甚至可以降低至log(总行数/列的基数)。
延迟物化 Late Materialization
首先什么叫物化:实际上就是什么时候把列式的数据转化为行式的数据
select b from R where a = X and d = Y
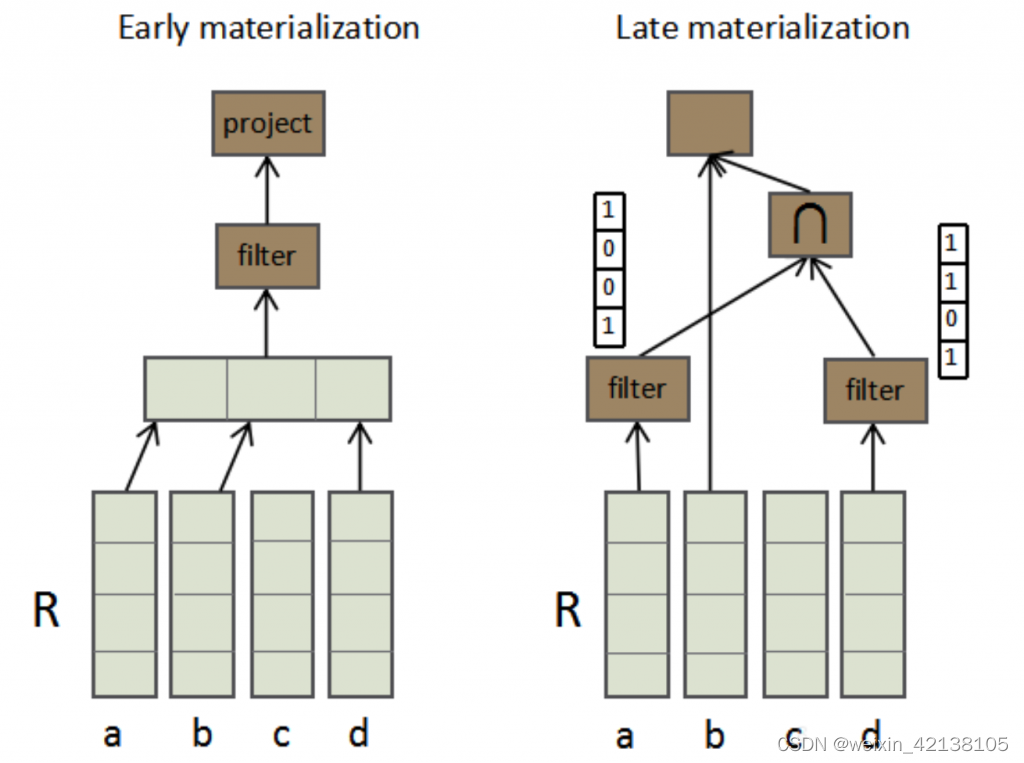
延迟物化有以下几个优点:
- 很多select和aggregation操作,不需要整行数据,过早物化造成性能损失
- 如果数据是被压缩过的,那么过早物化需要解压数据,但很多操作可以直接下推到压缩数据上的
- 对操作系统缓存的利用率会更好。因为如果变成Row,会有很多其他类型的数据污染Cache Line
- 针对定长的列做块迭代处理,可以当成一个数组来操作,可以利用CPU的很多优势;相反,行存中列类型往往不一样,长度也不一样,还有大量不定长字段,难以加速;
块迭代 Block Iteration
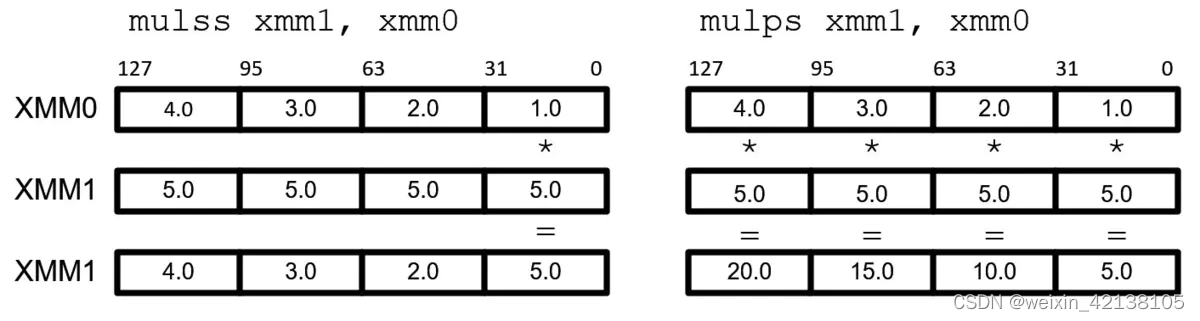
每列的数据存储在一起,可以认为这些数据是以数组的方式存储的,基于这样的特征,当该列数据需要进行某一同样操作,可以使用SIMD进一步提升计算效率,即便运算的机器上不支持SIMD, 也可以通过一个循环来高效完成对这个数据块各个值的计算。
SIMD即"single instruction, multiple data"(单指令流多数据流)
隐式链接 Invisible Join
SELECT c.nation, s.nation, d.year,
sum(lo.revenue) as revenue
FROM customer AS c, lineorder AS lo,
supplier AS s, dwdate AS d
WHERE lo.custkey = c.custkey
AND lo.suppkey = s.suppkey
AND lo.orderdate = d.datekey
AND c.region = 'ASIA'
AND s.region = 'ASIA'
AND d.year >= 1992 and d.year <= 1997
GROUP BY c.nation, s.nation, d.year
ORDER BY d.year asc, revenue desc;
方案一: 传统大表 join 小表
缺点:开始就进行了join,无法享受延迟物化带来的好处
方案二: 延迟物化
这个方式可以规避一开始做 join 的行为,具体方法为:
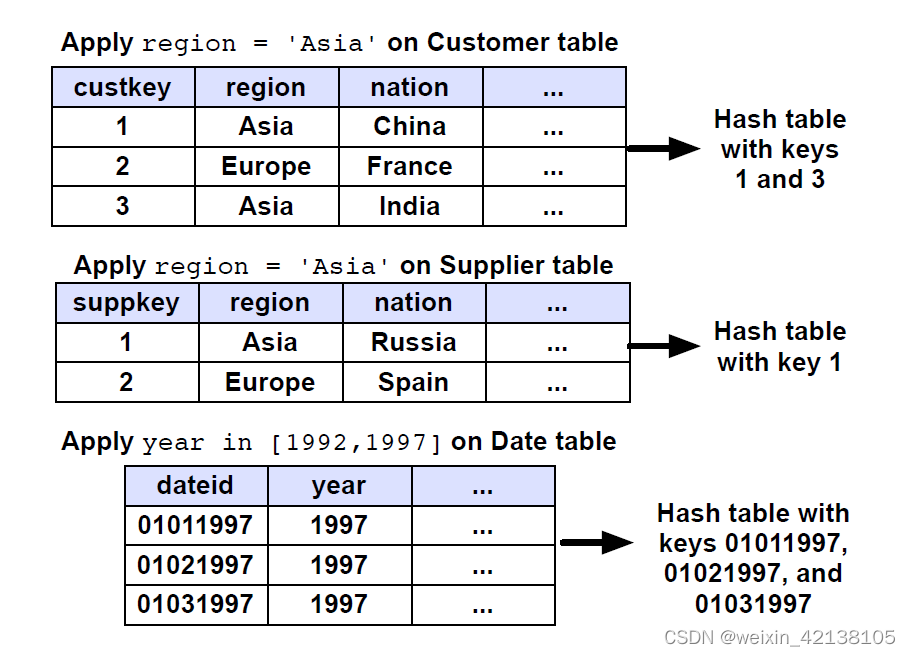
- 用 c.region = ‘ASIA’ 过滤 custom 表,并拿到满足条件的 custom key 的集合,同时记录 custom 表中满足条件的记录的位置
- 用 1 中获得的 custom key 来过滤 orderline 表,并拿到满足条件的记录的位置
- 遍历 2 中获得的位置列表,提取 suppplier key、order date 和 revenue 并且借助 custom key 和 1 中获取到的位置信息,提取 custom 表中的 c.nation 字段
- supplier 和 date 表的 join 类似处理
方案三: 隐式join
-
在每个维度表上应用对应的过滤条件,得到每个维度表(dimension table)满足条件的记录的 key,同时这个 key 也应该是事实表(the fact table)的外键(foreign key)。
-
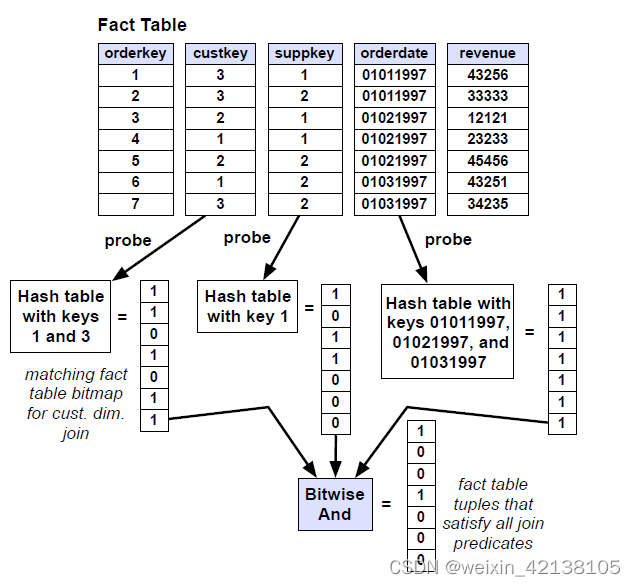
遍历事实表的各个外键列,使用 1 中得到的 key 来判断是否满足条件,生成一个满足条件的记录的位置信息的 bitmap ,并将这些 bitmap 做 AND 操作,生成最终过滤结果的 bitmap
-
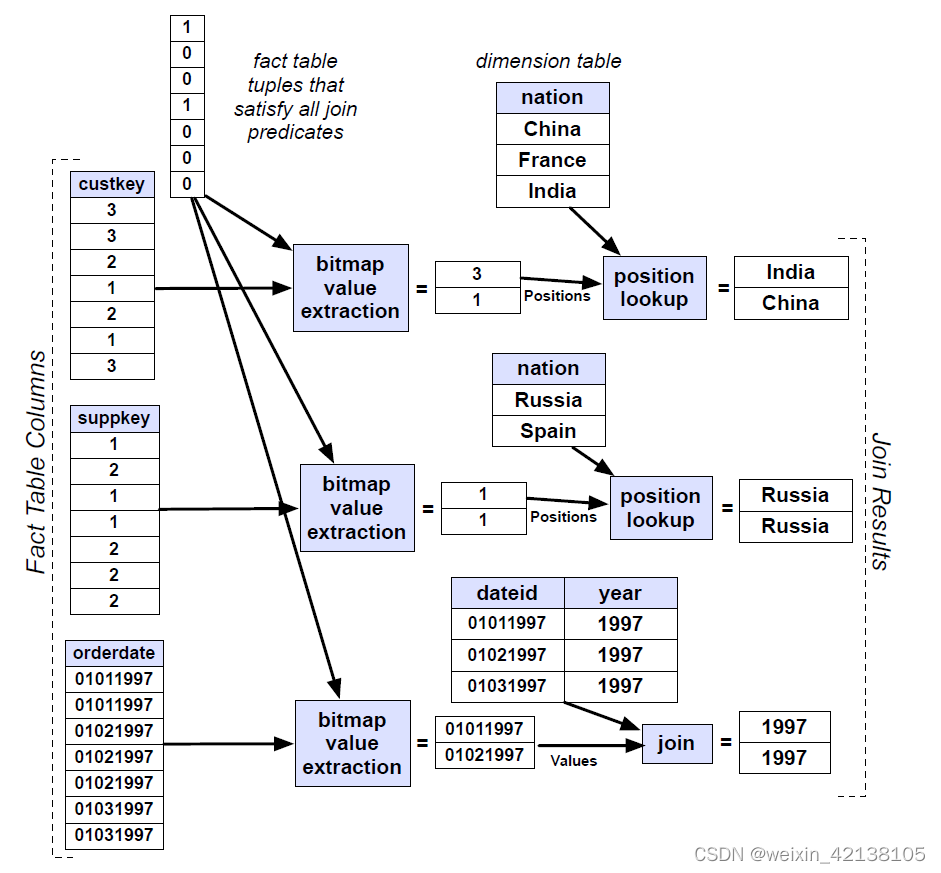
利用 2 中得到的 bitmap 依次提取各个维度表的外键,使用维度表的键来提取维度表中查询所需要的其他列。如果维度表的键是排过序的、从 1 开始连续的值,意味着维度表里面的列可以通过类似访问数组一样的方式提取出来(这一点会比传统的延迟物化方法快很多)。
优化点性能提升
- 隐式join提升性能 50-75%
- 块迭代提升性能 5%-50%。差距比较大的主要看有没有压缩
- 压缩平均提升两倍性能
- 延迟物化提升接近3倍性能
如果把这些优化措施都删除,性能跟行存差不多