问题一: 跨公网部署Otter
参考架构图
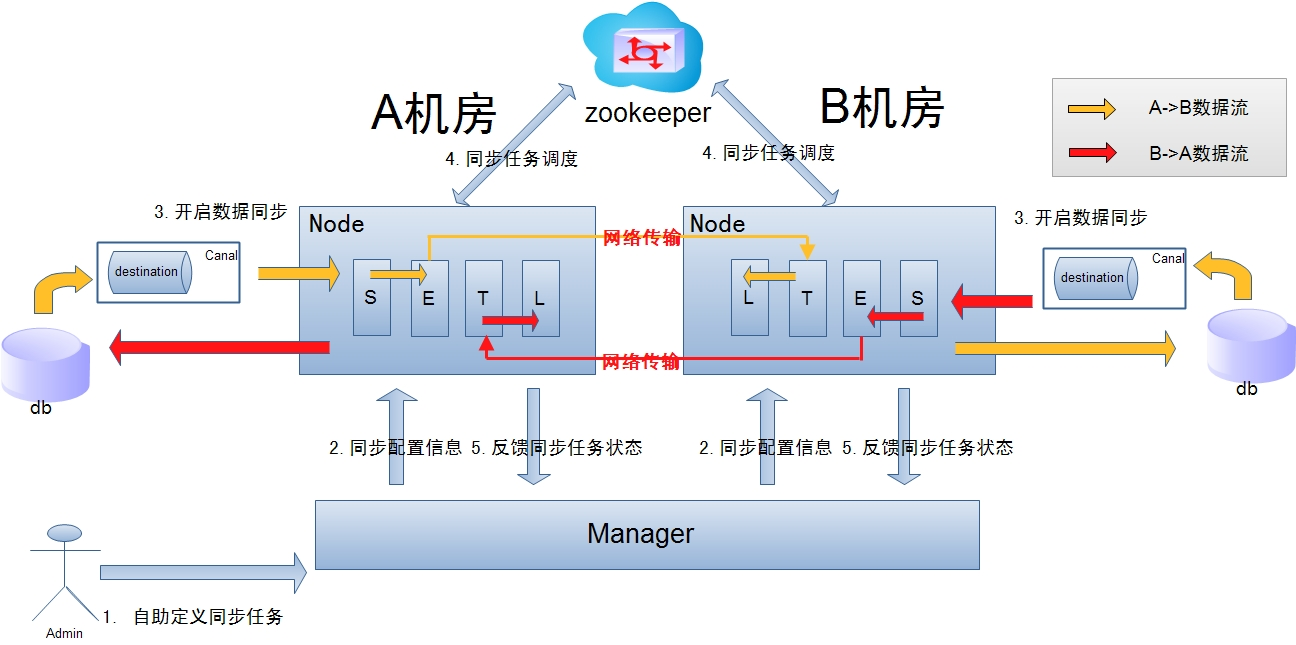
解析
a. 数据涉及网络传输,S/E/T/L几个阶段会分散在2个或者更多Node节点上,多个Node之间通过zookeeper进行协同工作 (一般是Select和Extract在一个机房的Node,Transform/Load落在另一个机房的Node,通过zookeeper watcher ()机制触发客户端node执行回调事件)
上图中:
A-->B同步走的是黄色的流程,S/E在A机房Node,T/L在B机房Node
B-->A同步走的是红色流程,S/E在B机房Node,T/L在A机房Node
b. node节点可以有failover / loadBalancer. (每个机房的Node节点,都可以是集群,一台或者多台机器)
c. Canal是嵌入在Node中的,一般选择在S/E节点上创建Canal,即在离源数据库机房近的一端Node创建Canal,同一节Node可以创建多个Canal实例,但是针对同一个同步,同一时间只会有一个工作节点。
d. 要保证两端Node网络是互通的,Manager和各个资源也要是互通的。
配置
阿里云 1核/2G
腾讯云 1核/2G
百度云 2核/4G
分配:
阿里云 Node Mysql A
腾讯云 Node Mysql B
百度云 Manager Otter Mysql Zookeeper
环境: jdk1.8 docker1.19 Mysql5.7(Docker版本) Zookeeper3.14 Otter1.14
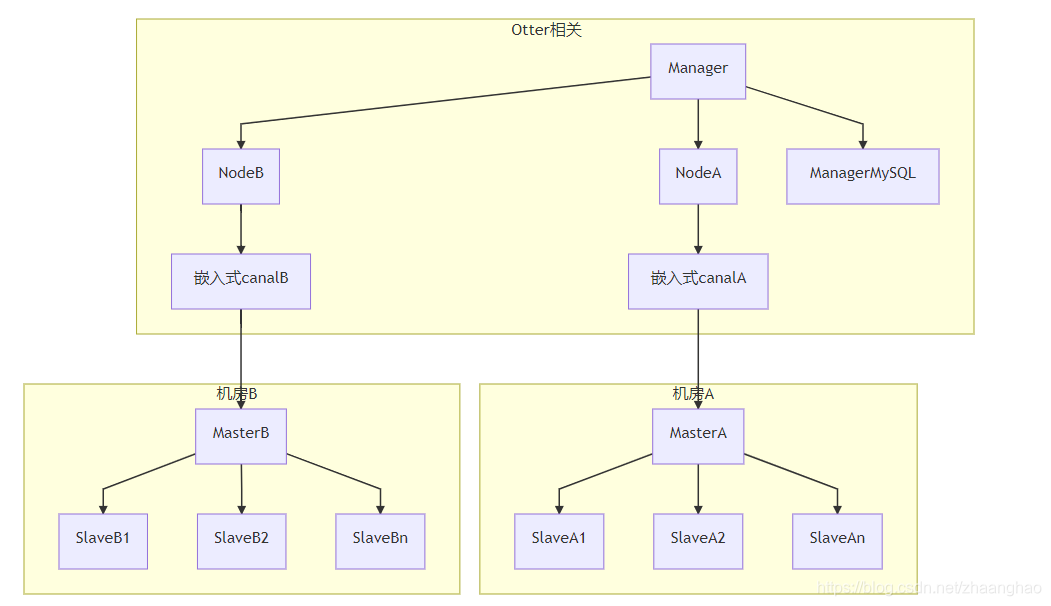
部署结构:
问题二: Otter内部工作模块构件
SETL阶段
解析
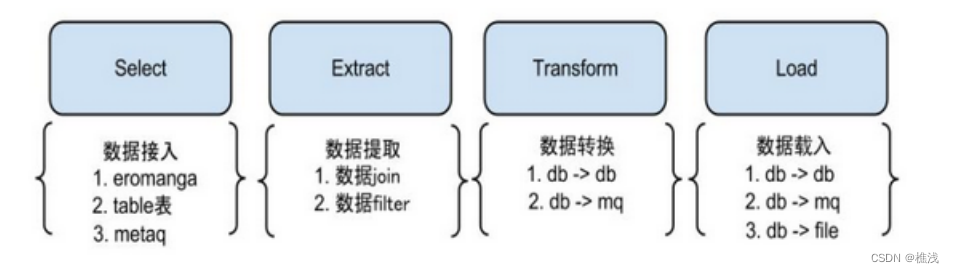
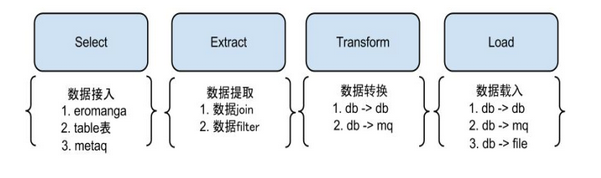
为了更好的支持系统的扩展性和灵活性,将整个同步流程抽象为Select/Extract/Transform/Load,这么4个阶段.
Select阶段: 为解决数据来源的差异性,比如接入canal获取增量数据,也可以接入其他系统获取其他数据等。
Extract阶段: 组装数据,针对多种数据来源,mysql,oracle,store,file等,进行数据组装和过滤。
Transform阶段: 数据提取转换过程,把数据转换成目标数据源要求的类型
Load阶段: 数据载入,具体把数据载入到目标端
自定义拓展
- 数据处理自定义,比如Extract , Transform的数据处理. 目前Select/Load不支持数据自定义处理
- 组件功能性扩展,比如支持oracle日志获取,支持hbase数据输出等.
自由之门:
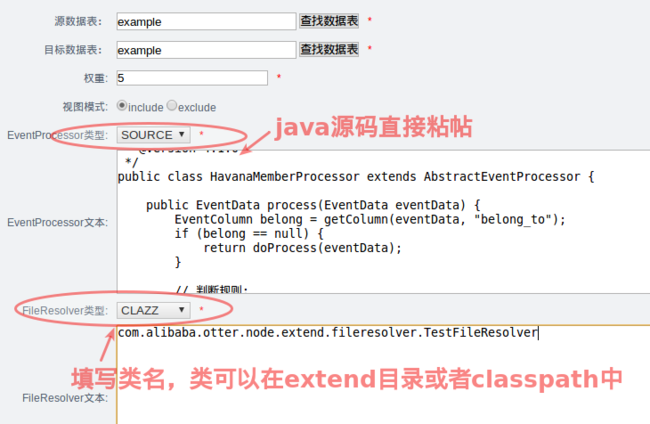
EventProcessor : 自定义数据处理,可以改变一条变更数据的任意内容
FileResolver : 解决数据和文件的关联关系(主要解决异地文件同步路径问题)
组件拓展目前这块扩展性机制不够,设计时只预留了接口,但新增一个功能实现,需要通过硬编码的方式去进行,下载otter的源码,增加功能支持,修改spring配置,同时修改web页面,方便使用。
调度模型
解析
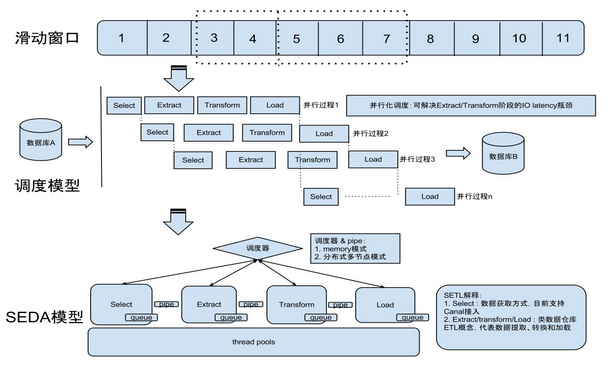
- otter通过select模块串行获取canal的批数据,注意是串行获取,每批次获取到的数据,就会有一个全局标识,otter里称之为processId.
- select模块获取到数据后,将其传递给后续的ETL模型. 这里E和T模块会是一个并行处理
- 将数据最后传递到Load时,会根据每批数据对应的processId,按照顺序进行串行加载。 ( 比如有一个processId=2的数据先到了Load模块,但会阻塞等processId=1的数据Load完成后才会被执行)
简单一点说,Select/Load模块会是一个串行机制来保证binlog处理的顺序性,Extract/Transform会是一个并行,加速传输效率.
并行度
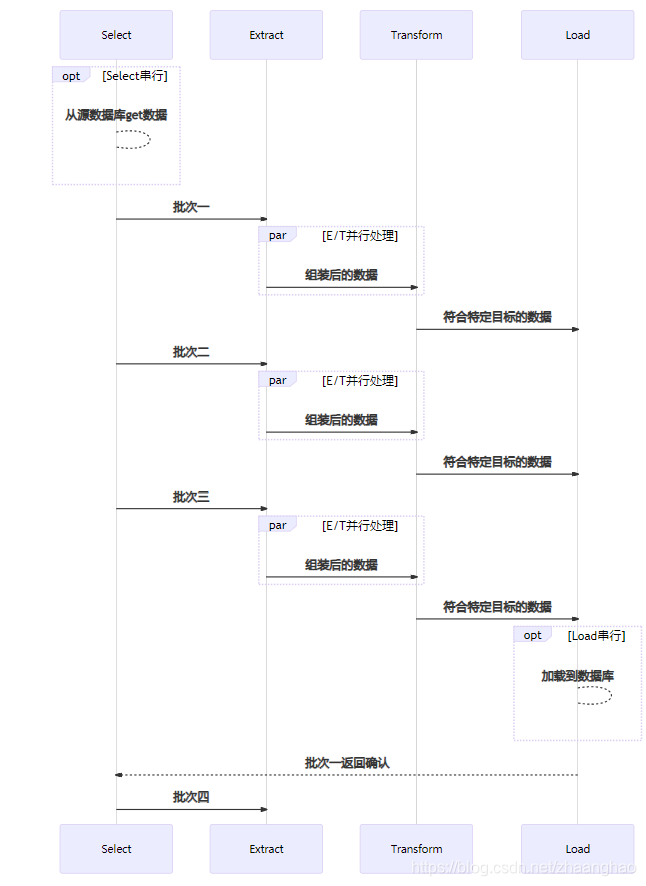
类似于tcp滑动窗口大小,比如整个滑动窗口设置了并行度为5时,只有等第一个processId Load完成后,第6个Select才会去获取数据。
并行度为三:
SelectExtractTransformLoad从源数据库get数据opt[Select串行]批次一组装后的数据par[E/T并行处理]符合特定目标的数据批次二组装后的数据par[E/T并行处理]符合特定目标的数据批次三组装后的数据par[E/T并行处理]符合特定目标的数据加载到数据库opt[Load串行]批次一返回确认批次四SelectExtractTransformLoad
SEDA模型(分阶段事件驱动)
把数据处理划分成各个阶段,由中央控制器调度。
对应到代码中:
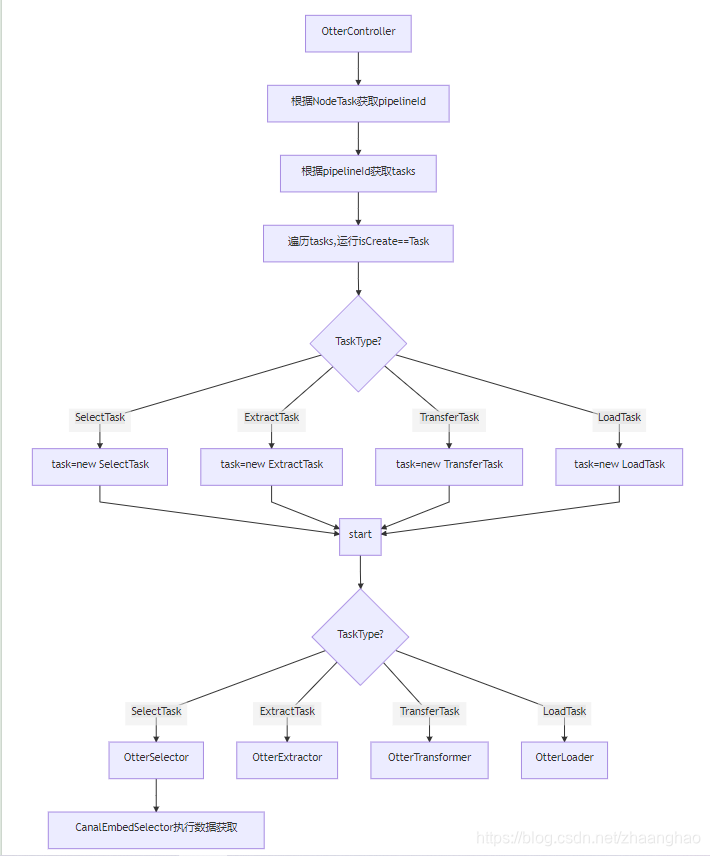
解析
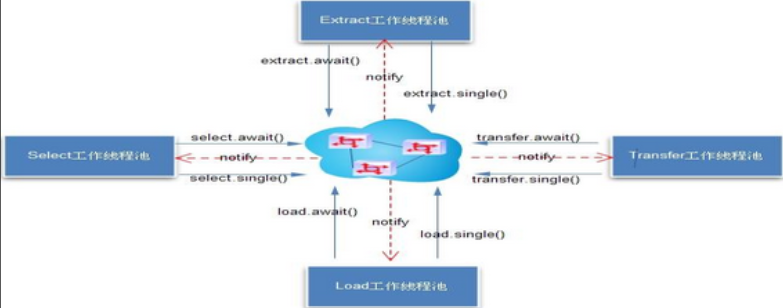
将并行化调度的串行/并行处理,进行隐藏,抽象了await/single的接口,整个调度称之为仲裁器。(有了这层抽象,不同的仲裁器实现可以解决同机房,异地机房的同步需求)
模型接口:
await模拟object获取锁操作
notify被唤醒后提交任务到thread pools
single模拟object释放锁操作,触发下一个stage
这里使用了SEDA模型的优势:
共享thread pool,解决流控机制
划分多stage,提升资源利用率(异地可以协同工作)
统一编程模型,支持同机房,跨机房不同的调度算法(同机房耗时操作主要是数据处理,跨机房耗时操作主要是数据传输和回滚)
在pipe中,通过对数据进行TTL控制,解决TCP协议中的丢包问题控制. SEDA主要还是为了解决传统并发模型的缺点(锁机制,不易于控制,耦合度高),通过将服务器的处理划分各个Stage,利用queue连接起来形成一个pipeline的处理链,并且在Stage中利用控制器进行资源的调控。
有了一层SEDA调度模型的抽象,S/E/T/L模块之间互不感知,几个模块之间的数据传递,需要有一个机制来处理,这里抽象了一个pipe(管道)的概念.
原理:
stage | pipe | stage
基于pipe实现:
in memory (两个stage经过仲裁器调度算法选择为同一个node时,直接使用内存传输)
rpc call (传递的数据<1MB) (异地)
file(gzip) + http多线程下载 (文件,大量数据)
在pipe中,通过对数据进行TTL控制,解决TCP协议中的丢包问题控制. (TTL>n重传)
仲裁器算法
主要包括: 令牌生成(processId) + 事件通知.
令牌生成:
- 基于AtomicLong.inc()机制(原子性自增),(纯内存机制,解决同机房,单节点同步需求,不需要多节点交互)
- 基于zookeeper的自增id机制,(解决异地机房,多节点(一般是双节点)协作同步需求)
事件通知: (简单原理: 每个stage都会有个阻塞队列,接收上一个stage的single信号通知,当前stage会阻塞在该block queue上,直到有信号通知)
- block queue + put/take方法,(同Node纯内存机制存取数据)
- block queue + rpc + put/take方法 (两个stage对应的node不同,需要rpc调用,需要依赖负载均衡算法解决node节点的选择问题)
- block queue + zookeeper watcher () (zookeeper事件客户端回调)
负载均衡算法:
- Stick : 类似于session stick技术,一旦第一次选择了node,下一次选择会继续使用该node. (有一个好处,资源上下文缓存命中率高)
- Random : 随机算法
- RoundRbin : 轮询算法
注意点:每个node节点,都会在zookeeper中生成Ephemeral节点(零时节点),每个node都会缓存住当前存活的node列表,node节点消失,通过zookeeper watcher机制刷新每个node机器的内存。然后针对每次负载均衡选择时只针对当前存活的节点,保证调度的可靠性。
问题三: 名词表
| 名词 | 解释 | 备注 |
|---|---|---|
| Pipeline | 从源端到目标端的整个过程描述,主要由一些同步映射过程组成 | |
| Channel | 同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成 | |
| DataMediaPair | 根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等 | |
| DataMedia | 抽象的数据介质概念,可以理解为数据表/mq队列定义 | |
| DataMediaSource | 抽象的数据介质源信息,补充描述DateMedia | |
| ColumnPair | 定义字段映射关系 | |
| ColumnGroup | 定义字段映射组 | |
| Node | 处理同步过程的工作节点,对应一个jvm | |
| SEDA模型 | Staged Event-Driven Architecture(把一个请求处理过程分成几个Stage,不同资源消耗的Stage使用不同数量的线程来处理,Stage间使用事件驱动的异步通信模式。) | |
| stage | 程序流程的各个阶段(这里指数据的S/E/T/L) | |
| processId | 处理批次ID,保证串行顺序 | |
| get/ack/rollback | 获取/确认/回滚 | |
| zookeeper watcher () | zookeeper 事件回调机制 | |
| zookeeper Ephemeral 节点 | zookeeper session创建的一个零时节点 | |
| TTL | 代表数据在网络中长时间没有响应被丢弃时经过的最大的路由器数量 | |
| failover | 故障转移 |