想写这篇文章好久了,一直抽不出时间。这两天端午节放假,我和娃都泡在图书馆,在他看书的空闲期,我拿出电脑写下了本文。
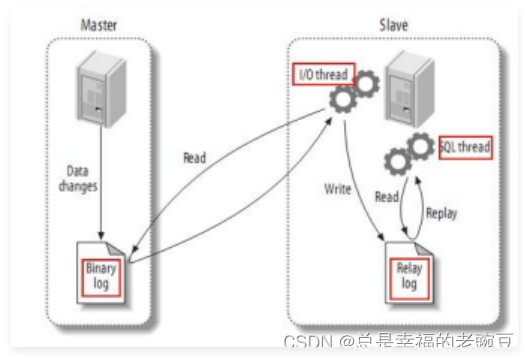
我们都知道,在分布式系统中,分布式 ID 有很多特殊的要求,其中之二就是要求各个 ID 必须全局唯一,且 ID 能够趋势递增。那么 MongoDB 作为一个分布式 NoSQL 数据库,它的 ObjectID 是一段字符串,是 UUID 吗?不同机器生产的 ID 会相同吗?这段字符串排序没有纯数字主键好排吧?等等,带着这样的疑问,我们一起来看看 Mongo 的 ObjectID 到底有何神秘之处!
先来看 mongo 插入一条记录:
db.xttblog.insert({"name":"业余草","age":88,"url":"www.xttblog.com"})
执行上面的语句后,收到Inserted 1 record(s) in 64ms信息就代表插入成功。插入成功后,我们进行查询。
db.getCollection('xttblog').find({})
查询的结果如下图所示:
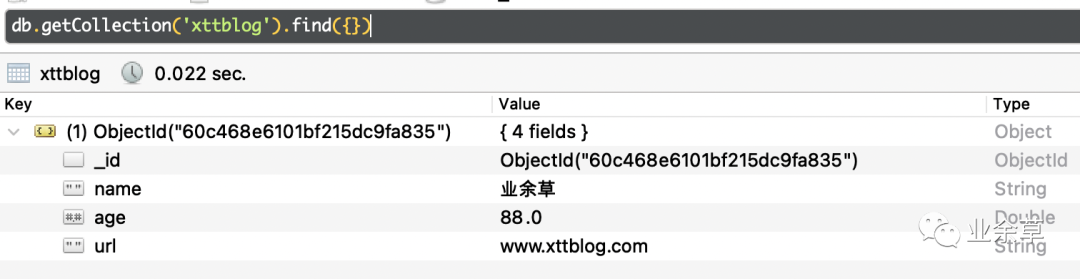
上图中,多出了一个_id,它是 ObjectId 类型。它是一个 24 位的字符串:60c468e6101bf215dc9fa835。
这个 24 位的字符串,虽然看起来很长,也很难理解,但实际上它是由一组十六进制的字符构成,每个字节(byte)占两位的十六进制数字,总共用了 12 字节的存储空间。相比 MYSQL int 类型的 4 个字节,MongoDB 的主键_id确实多出了很多字节。不过按照现在的存储设备,多出来的字节应该不会成为什么瓶颈。只要它能够解决我们的业务问题,我们根本就不在乎这点存储空间。
MongoDB 的这种设计,实际上体现出了它的空间换时间的思想。官网中对 ObjectId 的规范有以下描述:

上面的这个图中,有一个重点信息。
4 字节的 timestamp
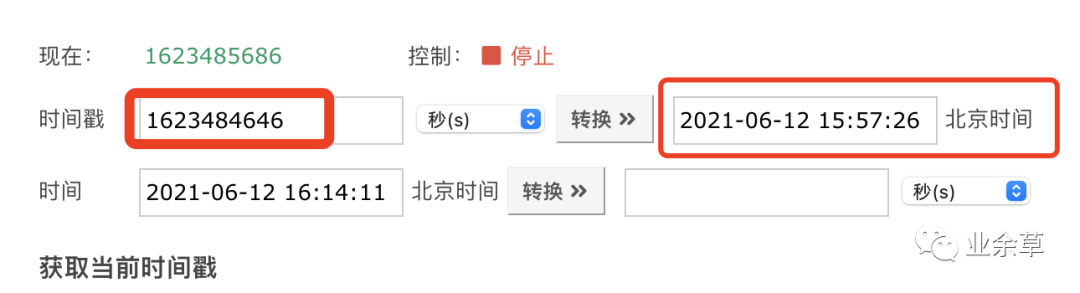
timestamp 就是时间戳。将刚才生成的 ObjectId 的前 4 位进行提取“60c468e6”,然后按照十六进制转为十进制,变为1623484646,这个数字就是一个时间戳,精确到秒。
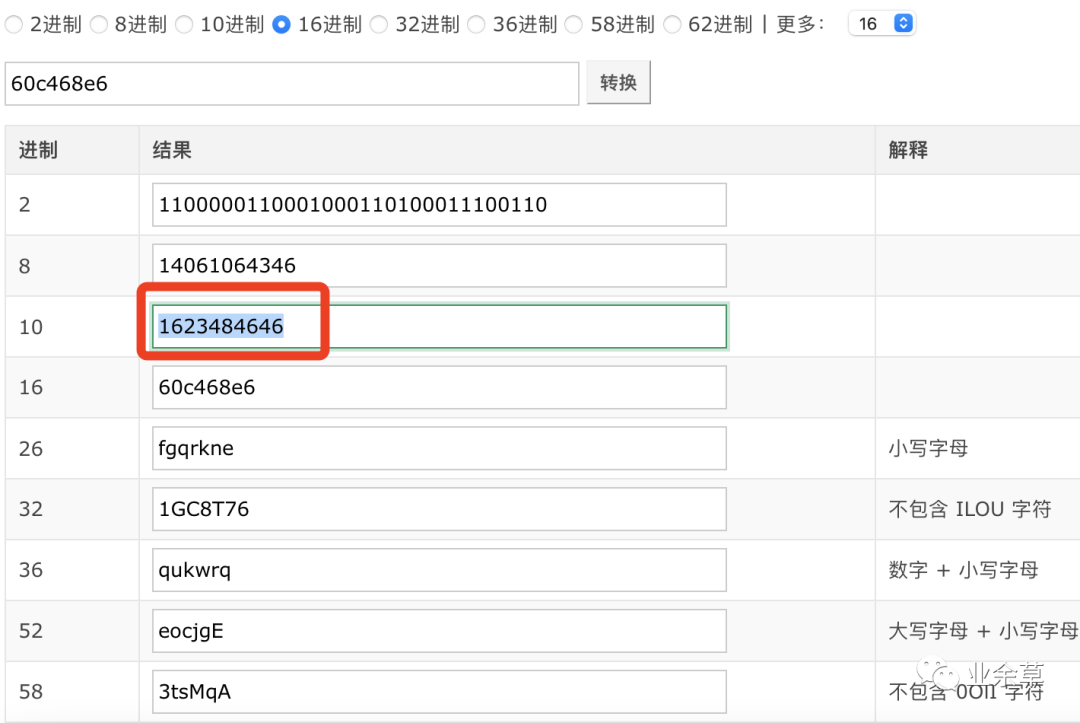
通过时间戳的转换,我们就能看清它的真面目了。最终是一个完整的日期时间格式,如下图所示。
Machine
ObjectId 规范中,还描述了,有一个占 3 个字节的 Machine(机器)。也就是说,字符串60c468e6101bf215dc9fa835中的第 9 到 15 位,101bf2这三个字节是所在主机的唯一标识符,一般是机器主机名的散列值,这样就确保了不同主机生成不同的机器的 hash 值,确保在分布式中不造成冲突,这也就是说在同一台机器生成的 ObjectId 中间(第9到15位)的字符串都是一模一样的原因。
PID
规范中中还描述了,还有两个字节的 process id(进程 ID)。上面的 Machine 是为了确保在不同机器产生的 ObjectId 不冲突,而 pid 就是为了在同一台机器不同的 mongodb 进程中产生的 ObjectId 不冲突。那么接着截取 4 位字符,15dc就是产生 ObjectId 的进程标识符。
实际上,你也可以把这个 16 进制的字符串15dc转换成 10 进制,然后在机器上通过 ps 命令看看,mongodb 的进程 pid 是不是相同的。
INC
规范中还描述了,最后 3 字节是 counter,也就是通过 INC 自增计数器实现的。前面的九个字节是保证了一秒内不同机器不同进程生成 ObjectId 不冲突,最后面的这三个字节9fa835是一个自动增加的计数器,用来确保在同一秒内产生的 ObjectId 也不会发生冲突,允许 256 的 3 次方等于 16777216 条记录的唯一性。也就是说每秒钟可以产生 16777216 个 ID,足够我们使用了,如果还不够,我们可以分机器,分集群。或者让客户端产生 ObjectId(客户端生成 ObjectId 我们后面再单独来讨论)。
总结
现在我们来做个总结,ObjectId 的前 4 个字节时间戳,记录了文档创建的时间;接下来 3 个字节代表了所在主机的唯一标识符,确定了不同主机间产生不同的 ObjectId;后 2 个字节的进程 id,决定了在同一台机器下,不同 mongodb 进程产生不同的 ObjectId;最后通过 3 个字节的自增计数器,确保同一秒内产生 ObjectId 的唯一性。
ObjectId 的这个主键生成策略,很好地解决了在分布式环境下高并发情况主键唯一性问题,非常值得我们学习和借鉴。
现在文章开头 3 个问题的答案,你已经知道了吧。欢迎留言评论说说你的想法!