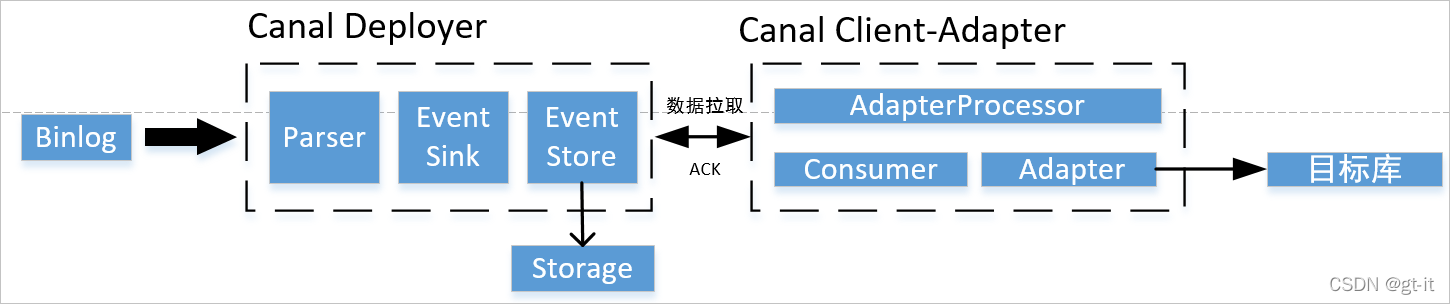
前言:
①canal.adapter-1.1.5 支持一对一单表的增量数据同步ElasticSearch 7;
②对于多表聚合场景的SQL满足不了我们的业务需求。
③采用java canal 接入,可以实现灵活化增量数据准实时同步
文章目录
- 一、java canal 接入
- 1. 依赖导入
- 2. 增加配置
- 3. canal 客户端
- 4. 消息消费/处理模型
- 5. 重建关联索引
- 二、效果验证
- 2.1. 关闭adapter
- 2.2. 修改数据
- 2.3. 数据监控
- 2.4. 索引查询
- 2.5. 关联数据修改
- 2.6. 数据监控
- 2.7. 索引查询
一、java canal 接入
前提:由于咱们是做增量数据同步ElasticSearch 7.15.2,因此项目中需要提前整合好ElasticSearch 7.15.2
1. 依赖导入
<!-- https://mvnrepository.com/artifact/com.alibaba.otter/canal.client --><dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.5</version></dependency><!-- https://mvnrepository.com/artifact/com.alibaba.otter/canal.protocol --><dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.protocol</artifactId><version>1.1.5</version></dependency><!-- https://mvnrepository.com/artifact/com.alibaba.otter/canal.common --><dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.common</artifactId><version>1.1.5</version></dependency>
2. 增加配置
application.properties
# canal服务端ip
canal.alone-ip=192.168.159.134
# destination
canal.destination=example
canal.username=canal
canal.passwoed=canal
canal.port=11111
3. canal 客户端
package com.imooc.dianping.canal;import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.google.common.collect.Lists;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;import java.net.InetSocketAddress;/*** canal 客户端** @author gblfy* @date 2021-11-22*/
@Component
public class CanalClient implements DisposableBean {private CanalConnector canalConnector;@Value("${canal.alone-ip}")private String CANALIP;@Value("${canal.destination}")private String DESTINATION;@Value("${canal.username}")private String USERNAME;@Value("${canal.passwoed}")private String PASSWOED;@Value("${canal.port}")private int PORT;@Beanpublic CanalConnector getCanalConnector() {//canal实例化canalConnector = CanalConnectors.newClusterConnector(Lists.newArrayList(new InetSocketAddress(CANALIP, PORT)), DESTINATION, USERNAME, PASSWOED);//连接canalcanalConnector.connect();// 自定filter 格式{database}.{table}canalConnector.subscribe();// 回滚寻找上次中断的位置canalConnector.rollback();//返回连接return canalConnector;}@Overridepublic void destroy() throws Exception {if (canalConnector != null) {//防止canal泄露canalConnector.disconnect();}}
}客户端有了,接下来,解决消息消费的问题?
消息消费的过程,就是轮训跑批的过程。可以简单理解为我们对应消息的消费,类似于canal客户端不断地从canal.deployer当中不断拉取mysql数据库中bin_log同步过来的消息,而消息消费完成之后,去告知canal.deployer,这条消息已经ack确认消费过了,之后,就不用推送给我了。使用这种方式,来完成消息消费的动作。
4. 消息消费/处理模型
接入消息消费模型CanalScheduling
package com.imooc.dianping.canal;import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import com.imooc.dianping.dal.ShopModelMapper;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;/*** canal 消息消费模型** @author gblfy* @date 2021-11-22*/
@Component
public class CanalScheduling implements Runnable, ApplicationContextAware {//记录日志private final static Logger logger = LoggerFactory.getLogger(CanalScheduling.class);private ApplicationContext applicationContext;@Autowiredprivate ShopModelMapper shopModelMapper;@Resourceprivate CanalConnector canalConnector;@Autowiredprivate RestHighLevelClient restHighLevelClient;@Override//每个100毫秒 唤醒线程执行run方法@Scheduled(fixedDelay = 100)public void run() {//初始化批次IDlong batchId = -1;try {//批次/1000条int batchSize = 1000;Message message = canalConnector.getWithoutAck(batchSize);//1000条批次的ID 当获取的batchId=-1代表没有消息batchId = message.getId();List<CanalEntry.Entry> entries = message.getEntries();// batchId != -1 (内部消费有消息的)// entries.size() > 0有对应的内容//当batchId != -1 并且entries.size() > 0说明mysql bin_log发生了多少条数据的变化if (batchId != -1 && entries.size() > 0) {//逐条处理entries.forEach(entry -> {//处理类型: bin_log已ROW方式处理的消息if (entry.getEntryType() == CanalEntry.EntryType.ROWDATA) {//消息解析处理publishCanalEvent(entry);}});}//消息解析完毕后,告知批次消息已经消费ack确认完成canalConnector.ack(batchId);} catch (Exception e) {e.printStackTrace();//将本次消息回滚,下次继续消息canalConnector.rollback(batchId);}}/*** 消息解析处理函数** @param entry*/private void publishCanalEvent(CanalEntry.Entry entry) {//事件类型 只关注INSERT、UPDATE、DELETECanalEntry.EventType eventType = entry.getHeader().getEventType();//获取发生变化的数据库String database = entry.getHeader().getSchemaName();//获取发生变化的数据库中的表String table = entry.getHeader().getTableName();CanalEntry.RowChange change = null;try {//记录这条消息发生了那些变化change = CanalEntry.RowChange.parseFrom(entry.getStoreValue());} catch (InvalidProtocolBufferException e) {e.printStackTrace();return;}change.getRowDatasList().forEach(rowData -> {List<CanalEntry.Column> columns = rowData.getAfterColumnsList();//主键String primaryKey = "id";CanalEntry.Column idColumn = columns.stream().filter(column -> column.getIsKey()&& primaryKey.equals(column.getName())).findFirst().orElse(null);//将Columns转换成mapMap<String, Object> dataMap = parseColumnsToMap(columns);try {indexES(dataMap, database, table);} catch (IOException e) {e.printStackTrace();}});}/*** 将Columns转换成map** @param columns* @return*/Map<String, Object> parseColumnsToMap(List<CanalEntry.Column> columns) {Map<String, Object> jsonMap = new HashMap<>();columns.forEach(column -> {if (column == null) {return;}jsonMap.put(column.getName(), column.getValue());});return jsonMap;}private void indexES(Map<String, Object> dataMap, String database, String table) throws IOException {logger.info("发生变化的行数据:{} ", dataMap);logger.info("发生变化的数据库:{} ", database);logger.info("发生变化的表:{} ", table);// 限定处理出具库范围 支处理数据库名称为dianpingdb的消息if (!StringUtils.equals("dianpingdb", database)) {return;}/*** 我们要关注表数据范围* 当seller表、category表、shop 表发生变化,都buildESQuery* 当着3个参数中任意一个参数发生变化,我只需要将发生变化的ID传入,重建与此ID关联的索引*/List<Map<String, Object>> result = new ArrayList<>();if (StringUtils.equals("seller", table)) {result = shopModelMapper.buildESQuery(new Integer((String) dataMap.get("id")), null, null);} else if (StringUtils.equals("category", table)) {result = shopModelMapper.buildESQuery(null, new Integer((String) dataMap.get("id")), null);} else if (StringUtils.equals("shop", table)) {result = shopModelMapper.buildESQuery(null, null, new Integer((String) dataMap.get("id")));} else {//不关注其他的表return;}for (Map<String, Object> map : result) {IndexRequest indexRequest = new IndexRequest("shop");indexRequest.id(String.valueOf(map.get("id")));indexRequest.source(map);//更新索引restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);}}@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.applicationContext = applicationContext;}
}5. 重建关联索引
package com.imooc.dianping.dal;import com.imooc.dianping.model.ShopModel;
import org.apache.ibatis.annotations.Param;import java.math.BigDecimal;
import java.util.List;
import java.util.Map;public interface ShopModelMapper {//当着3个参数中任意一个参数发生变化,我只需要将发生变化的ID传入,重建与此ID关联的索引List<Map<String,Object>> buildESQuery(@Param("sellerId")Integer sellerId,@Param("categoryId")Integer categoryId,@Param("shopId")Integer shopId);
}
<select id="buildESQuery" resultType="java.util.Map">select a.id,a.name,a.tags,concat(a.latitude,',',a.longitude) as location,a.remark_score,a.price_per_man,a.category_id,b.name as category_name,a.seller_id,c.remark_score as seller_remark_score,c.disabled_flag as seller_disabled_flagfrom shop a inner join category b on a.category_id = b.id inner join seller c on c.id=a.seller_id<if test="sellerId != null">and c.id = #{sellerId}</if><if test="categoryId != null">and b.id = #{categoryId}</if><if test="shopId != null">and a.id = #{shopId}</if></select>
二、效果验证
2.1. 关闭adapter
cd /app/canal/canal.adapterbin/stop.sh
2.2. 修改数据
修改dianpingdb数据库中shop表中ID=1的数据中name的值
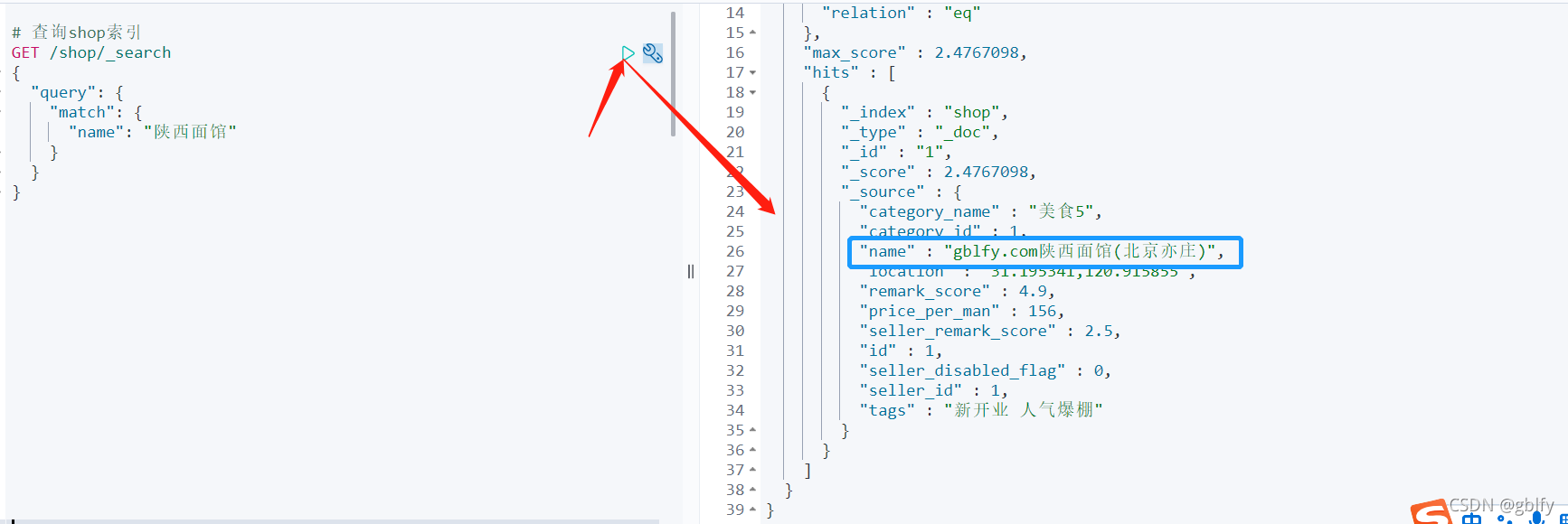
将陕西面馆(北京亦庄) 调整为gblfy.com陕西面馆(北京亦庄),提交事务!
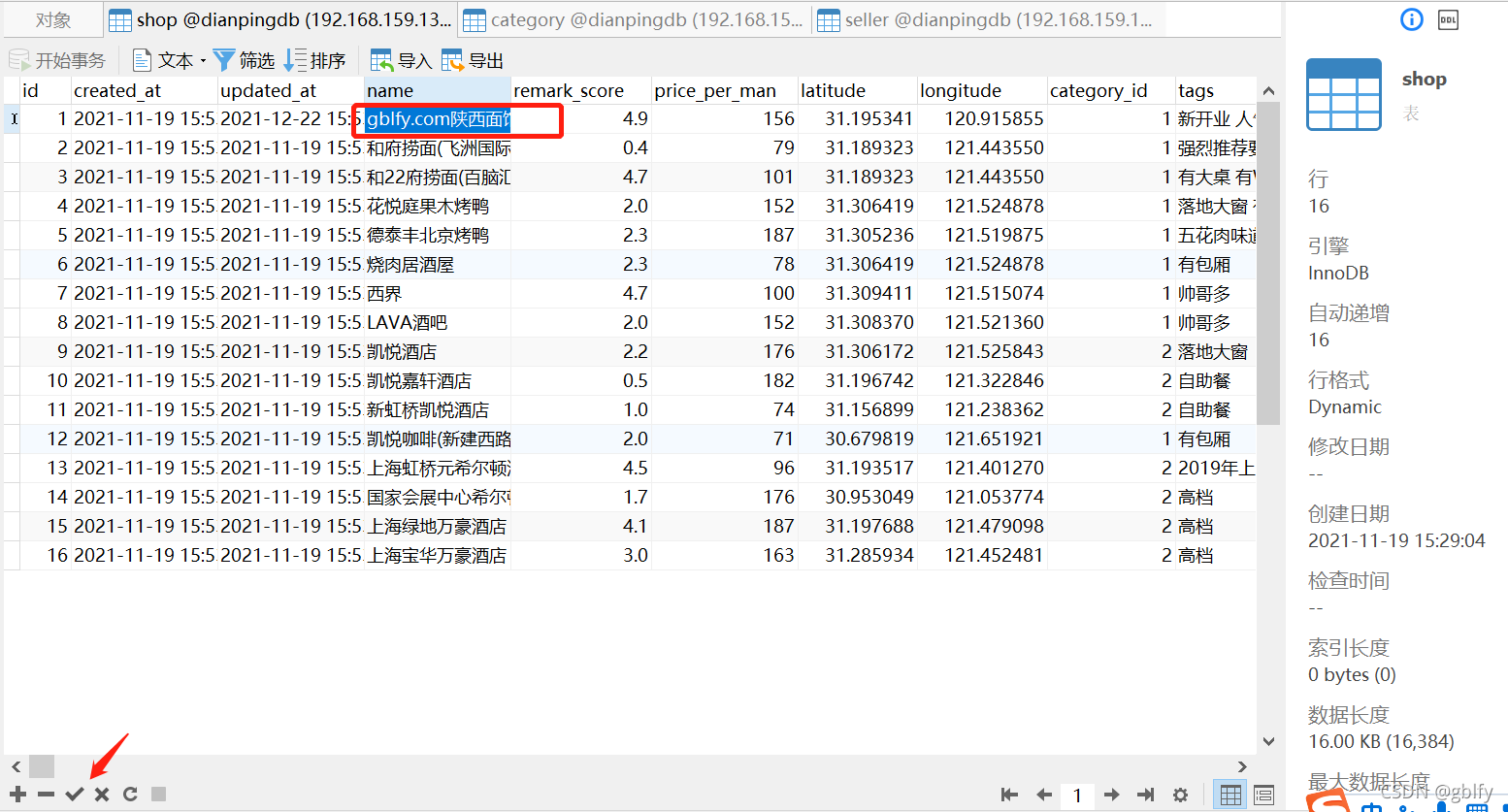
2.3. 数据监控
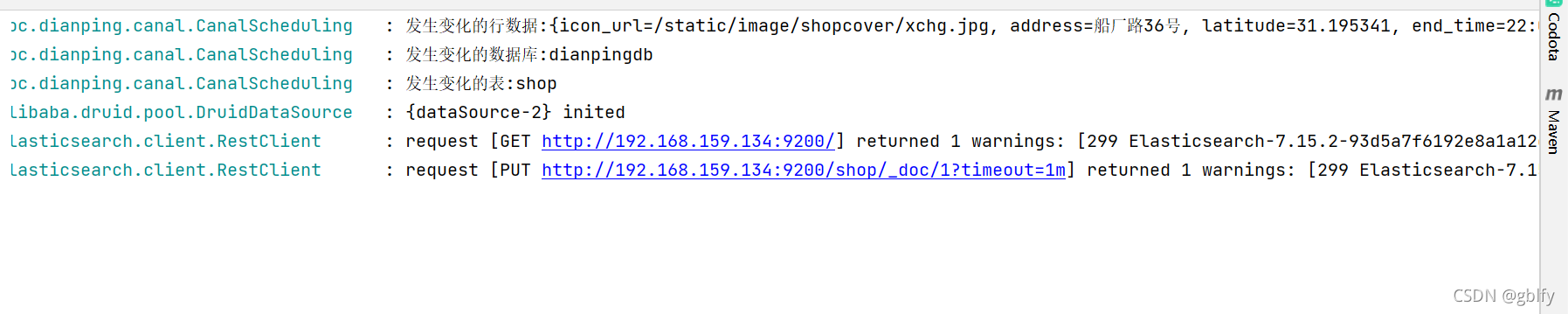
2021-11-23 16:19:21.338 INFO 3792 --- [ scheduling-1] c.imooc.dianping.canal.CanalScheduling : 发生变化的行数据:{icon_url=/static/image/shopcover/xchg.jpg, address=船厂路36号, latitude=31.195341, end_time=22:00, created_at=2021-11-19 15:53:52, tags=新开业 人气爆棚, start_time=10:00, updated_at=2021-12-22 15:53:52, category_id=1, name=gblfy.com陕西面馆(北京亦庄), remark_score=4.9, price_per_man=156, id=1, seller_id=1, longitude=120.915855}
2021-11-23 16:19:21.356 INFO 3792 --- [ scheduling-1] c.imooc.dianping.canal.CanalScheduling : 发生变化的数据库:dianpingdb
2021-11-23 16:19:21.356 INFO 3792 --- [ scheduling-1] c.imooc.dianping.canal.CanalScheduling : 发生变化的表:shop
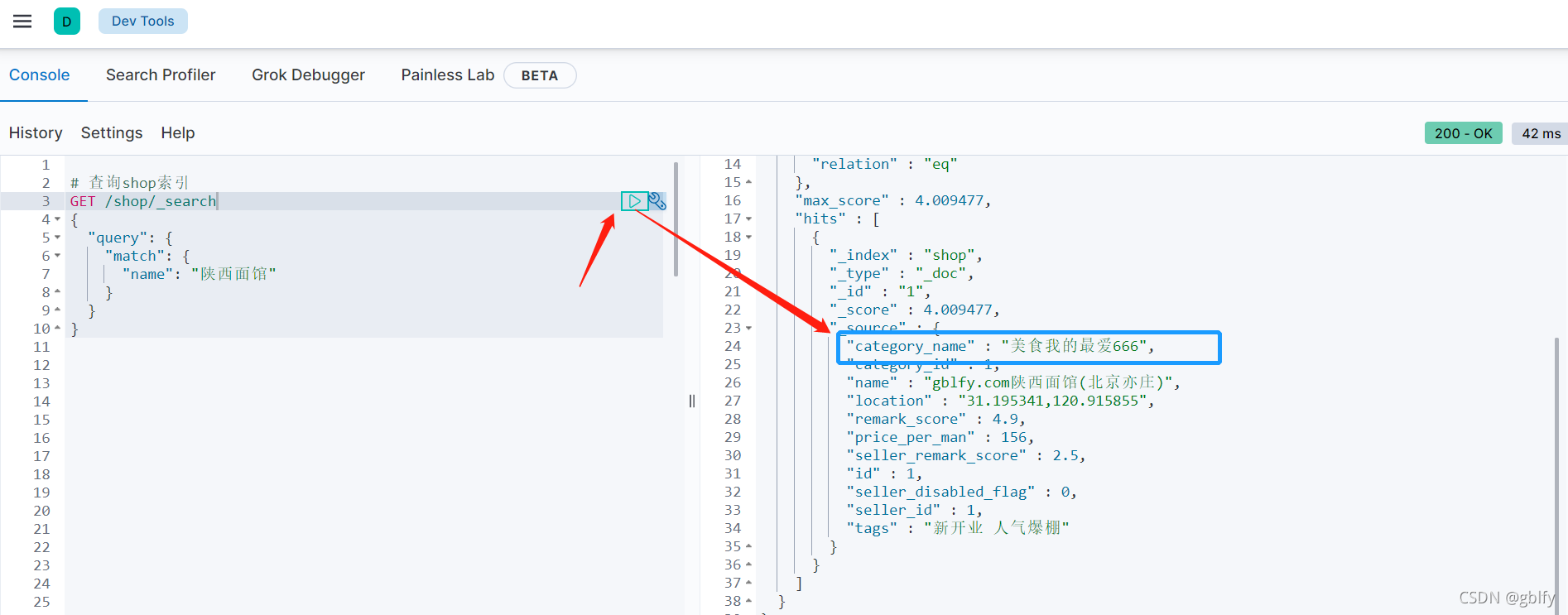
2.4. 索引查询
# 查询shop索引
GET /shop/_search
{"query": {"match": {"name": "陕西面馆"}}
}
2.5. 关联数据修改
单表增量同步,官网本身就支持,关联表数据修改,增量准实时同步,官网是不支持的。因此,咱们需要继续测试修改关联表的数据,再次验证。
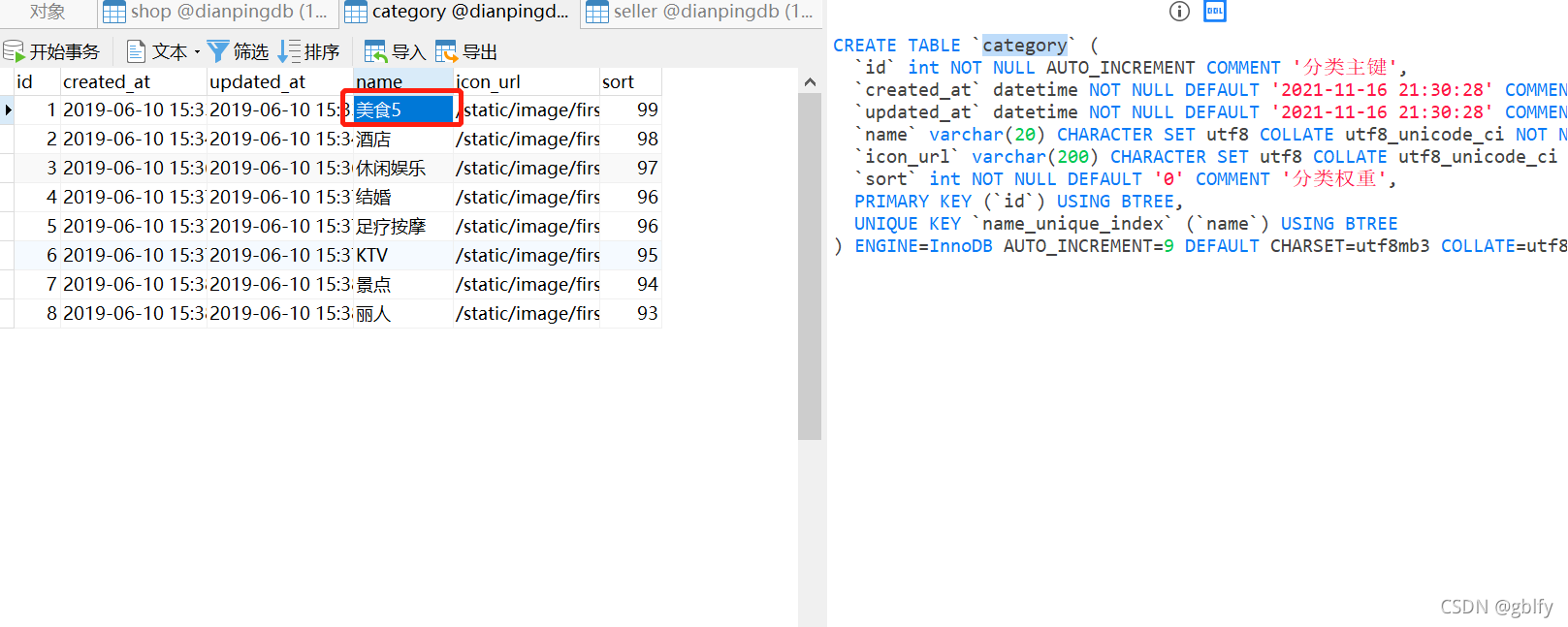
修改dianpingdb数据库中category表中ID=1的数据中name的值
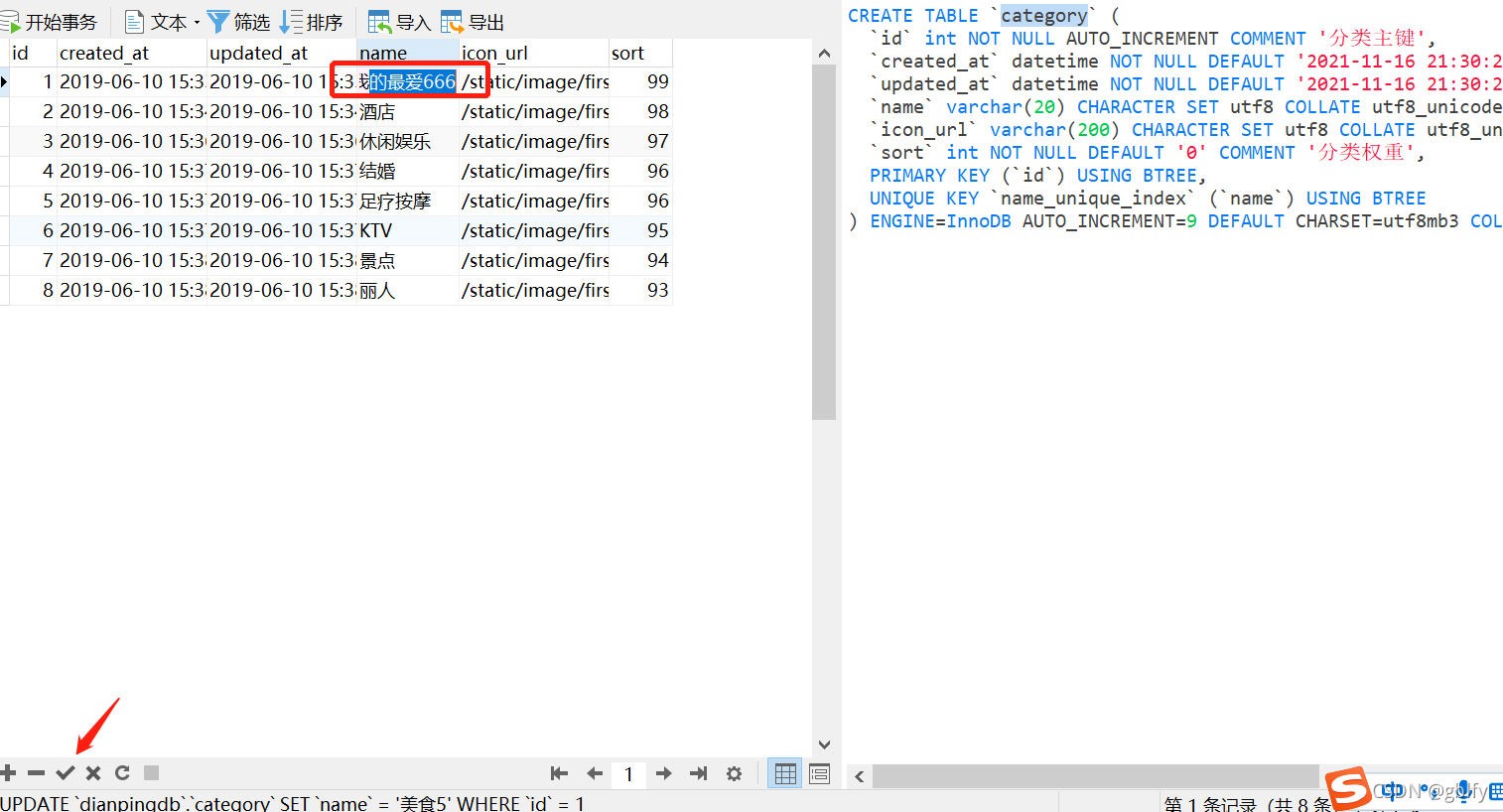
将美食5 调整为美食我的最爱666,提交事务!
修改前:
修改后:
2.6. 数据监控
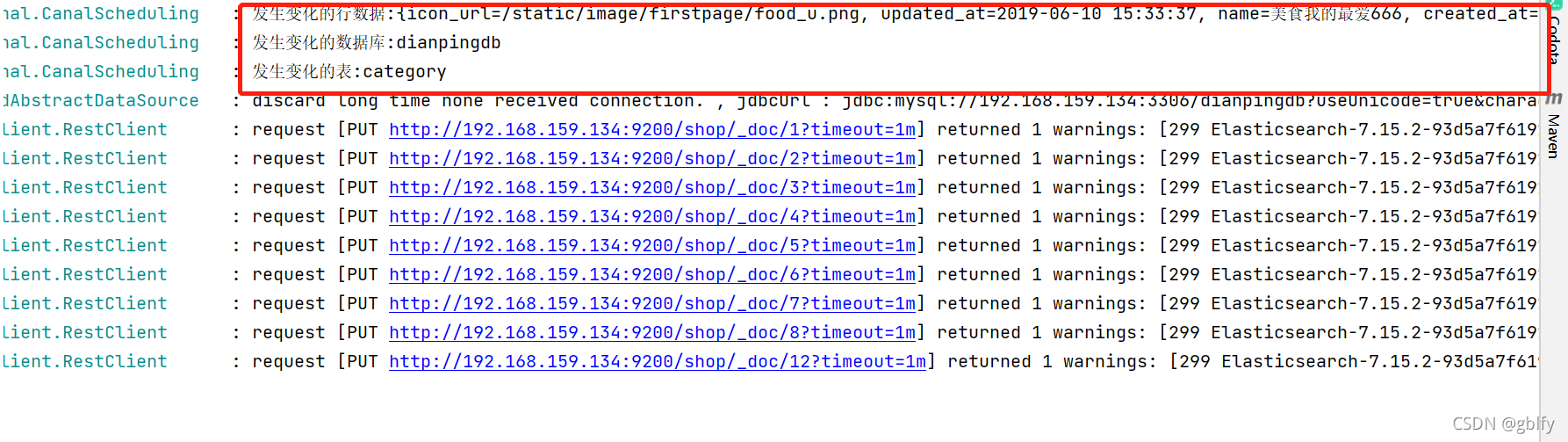
2021-11-23 16:25:16.325 INFO 3792 --- [ scheduling-1] c.imooc.dianping.canal.CanalScheduling : 发生变化的行数据:{icon_url=/static/image/firstpage/food_u.png, updated_at=2019-06-10 15:33:37, name=美食我的最爱666, created_at=2019-06-10 15:33:37, id=1, sort=99}
2021-11-23 16:25:16.334 INFO 3792 --- [ scheduling-1] c.imooc.dianping.canal.CanalScheduling : 发生变化的数据库:dianpingdb
2021-11-23 16:25:16.338 INFO 3792 --- [ scheduling-1] c.imooc.dianping.canal.CanalScheduling : 发生变化的表:category
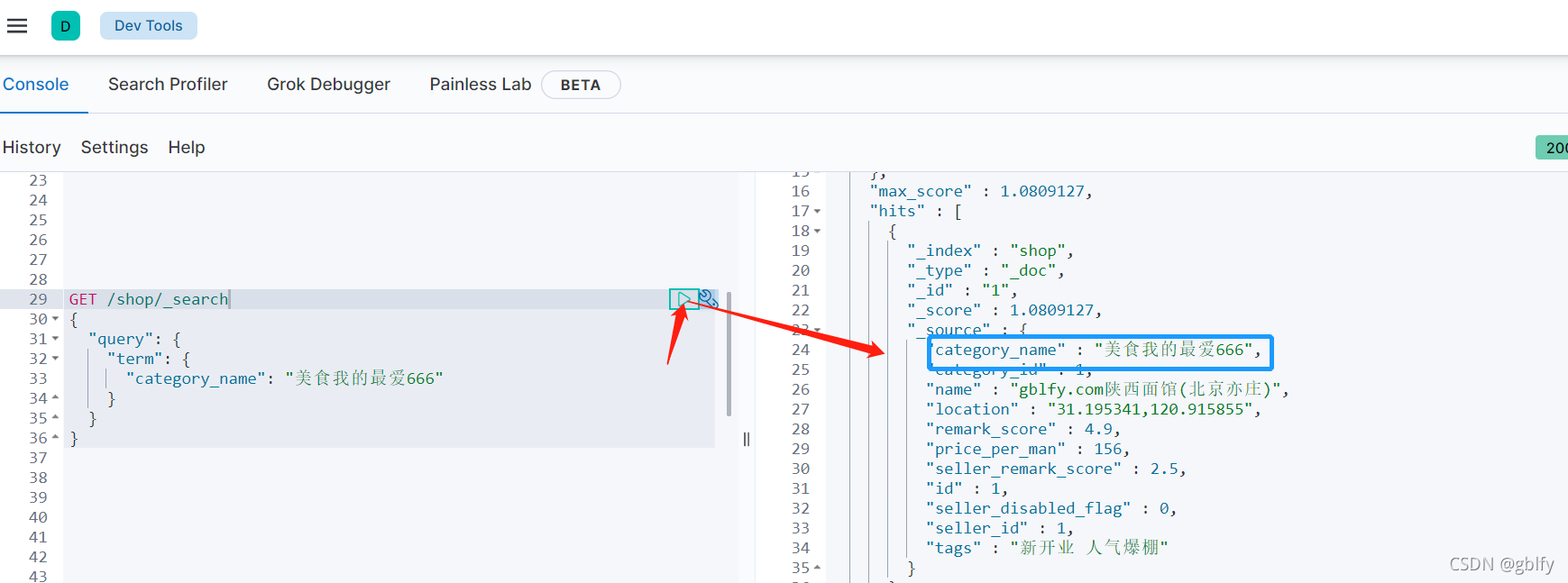
2.7. 索引查询
GET /shop/_search
{"query": {"term": {"category_name": "美食我的最爱666"}}
}
# 查询shop索引
GET /shop/_search
{"query": {"match": {"name": "陕西面馆"}}
}
至此,我们完成了通过java代码的方式,灵活化的根据ID去接入我们对应es增量的准实时更新!小伙伴们,一起加油!