0.引言
之前我们讲解过canal的各种应用,但是对于生产环境来讲,服务高可用是必须保证的。因此canal单节点是不能满足我们的需求的。就需要搭建canal集群。
1. canal集群模式
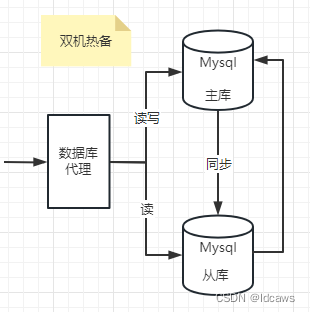
从架构方式上出发,我们用来保证服务高可用的手段主要是主从架构、集群架构。有时我们也把主从归结到集群架构中,但严格意义上讲,集群架构是指多节点同时运行,而主从架构同一时刻只有一个节点运行,另一个节点作为备用,只有当主节点宕机时,备用节点才会启用。
canal的集群模式是哪一种呢?
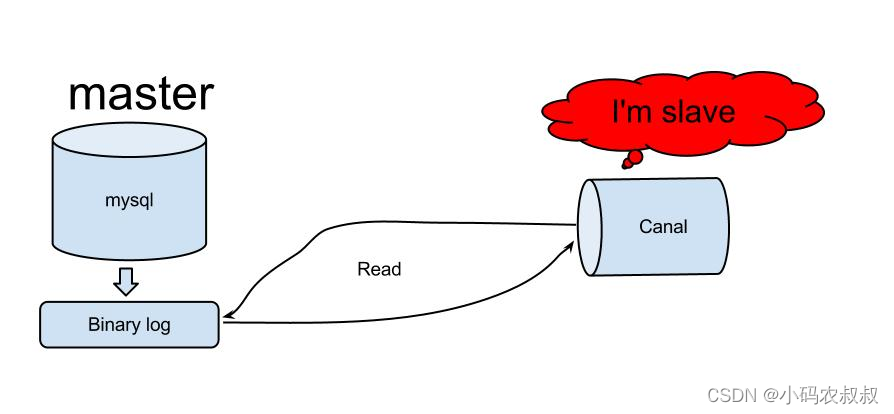
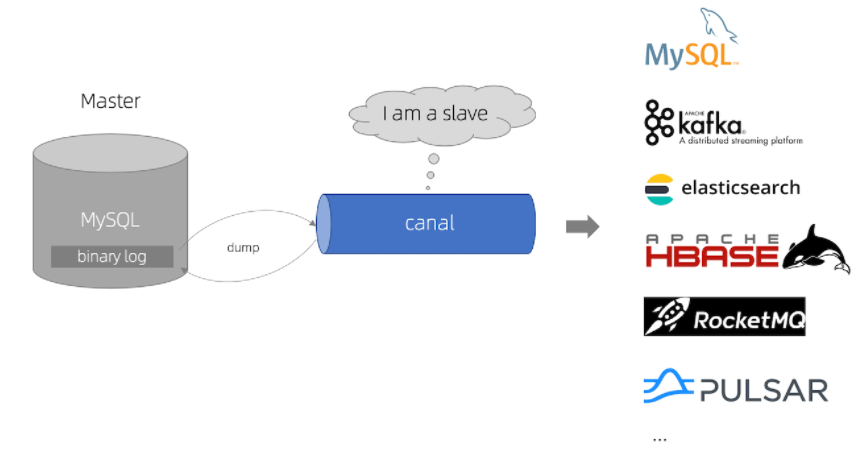
我们首先要理解canal实现数据同步的依赖于binlog,也依赖于mysql dump指令,binlog本身的特性就要求数据原子性、隔离性,有序性,同时mysql dump指令是比较占用mysql服务器资源的,所以要尽可能少的避免,为此canal服务端同一时刻只能有一个节点来读取binlog进行同步。
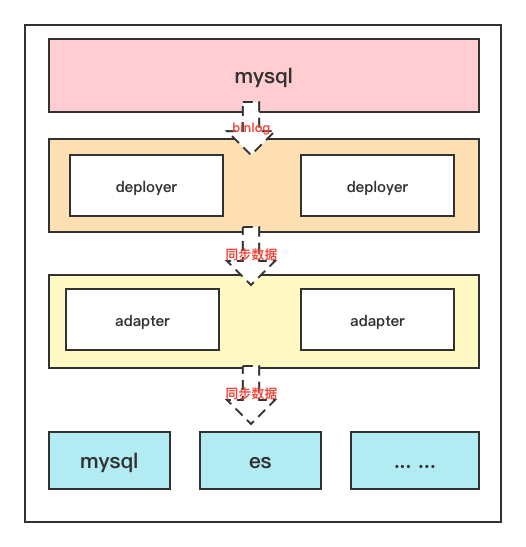
因此在这样的基础之上,canal的集群模式实际上就是主从模式。那么我们要进行搭建的也就是主从。
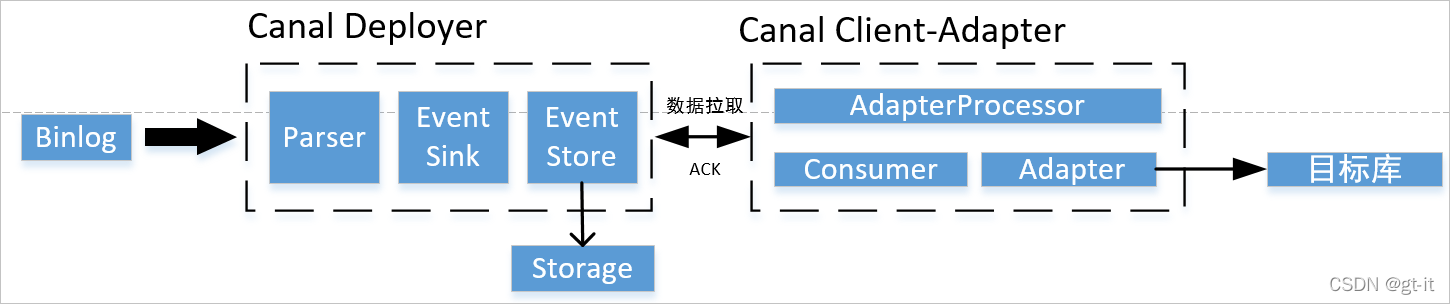
我们知道canal中有服务端deployer和客户端adapter,服务端负责从mysql中读取binlog,而客户端负责从服务端读取同步过来的binlog数据,处理后将同步数据发送到目标服务端,比如redis、es或其他的关系性数据库等
这一点,在官方文档中也有解释,特此引用,帮助大家理解
canal的ha分为两部分,canal server和canal client分别有对应的ha实现
canal server: 为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
主从节点之间如何协调配合?
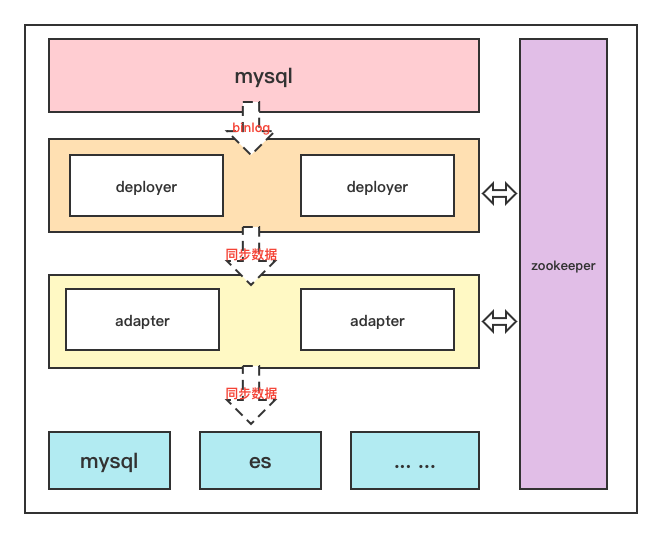
确定了集群架构后,迎面而来的就出现了另一个问题:从节点如何知道主节点宕机了,如何知道自己何时开始工作?同时主节点同步数据的进度从节点如何知道,从节点不可能再从头开始同步数据吧?
针对第一个大家可能会想到发送心跳包来实现,第二个那么就需要一个第三方来存储同步的进度,于是乎结合这两点,我们想一想,什么样的第三方组件具备了心跳维护功能(也就是注册服务的功能),还具备了文件存储及同步的功能
这不就是zookeeper的天然属性嘛。所以我们需要zk来作为调节主从节点的第三方组件。相当于是作为注册中心和配置中心的作用
于是架构变成了这样的形式
2. canal集群搭建
梳理完原理后,我们来看看实际如何搭建
2.1 环境准备
为了保证演示的完整性,除了演示canal集群搭建,我们还会通过集群模式来同步mysql数据到es
所以我们前期需要准备:
- 一个mysql数据库,并开启binlog,以及创建一个canal账号,给予权限
- 一个es+kibana的服务
- 一个zookeeper服务
- 两个服务器,用于部署canal
关于mysql开启binlog,创建用户并赋权因为之前已经讲过,不再累叙,有需要的参考以下博文:
通过canal1.1.5实现mysql8.0数据增量/全量同步到elasticsearch7.x
2.2 集群搭建
2.2.1 zookeeper搭建
这里为了方便演示,采用docker搭建zk
docker run -d -e TZ="Asia/Shanghai" -p 2181:2181 --name zookeeper zookeeper
2.2.2 服务端deployer搭建
1、查询数据源mysql服务的binlog位置
# 源mysql服务器中登陆mysql执行
show binary logs;
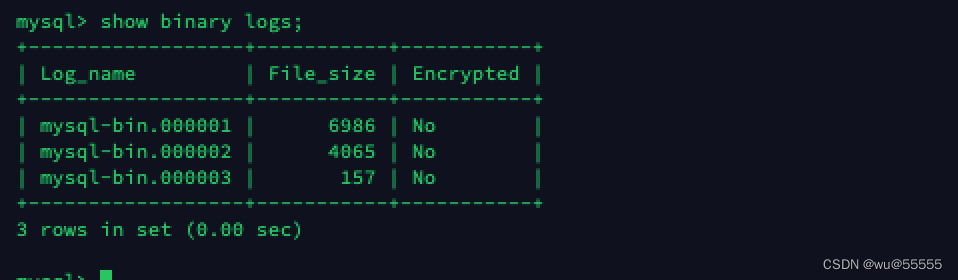
记住该查询结果,我们后续配置中将使用
2、截止本文canal的最新版为1.1.6,所以文本使用该版本进行演示,canal1.1.6版本需要jdk11+,canal1.1.5及以下使用jdk1.8+即可
canal1.1.6下载地址
或者直接在服务器上通过wget指令下载
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.deployer-1.1.6.tar.gz
3、解压安装包
tar -zxvf canal.deployer-1.1.6.tar.gz
4、新建一个实例cluster用于本次演示
cd deployer
cp -R conf/example conf/cluster
5、修改配置文件canal.properties
vim conf/canal.properties
修改内容
# 设置canal服务端IP
canal.ip =192.168.244.25
# zk地址,多个地址用逗号隔开
canal.zkServers =192.168.244.1:2181
# 实例名称
canal.destinations = cluster
# 持久化模式采用zk
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
6、修改配置文件instance.properties
vim conf/cluster/instance.properties
修改内容:
# 每个canal节点的slaveId保持唯一,在1.0.26版本后已经能够自动生成了, 无需设置
# canal.instance.mysql.slaveId=1
# 设置binlog同步开始位置
canal.instance.master.address=192.168.244.17:3306
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=0
canal.instance.master.timestamp=1665038153854
# 数据源账号密码
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
mysql数据同步起点说明:
- canal.instance.master.journal.name + canal.instance.master.position : 精确指定一个binlog位点,进行启动
- canal.instance.master.timestamp : 指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动
- 不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)
7、参考上述配置调整deployer节点2,注意deployer服务ip调整为当前节点的ip
8、启动两个节点,需要注意的是,启动第二个节点的时候是不会启动成功的,如我们上述所说同时只会有一个canal服务运行,当另一个canal服务宕机时该备用节点会自动启动的
./bin/startup.sh
2.2.3 客户端adapter配置
1、下载adapter安装包,可以如上述一样在github页面上下载,也可以通过指令下载
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.adapter-1.1.6.tar.gz
2、解压压缩包
tar -zxvf canal.adapter-1.1.6.tar.gz
3、修改配置文件application.yml
vim conf/application.yml
修改内容,所需调整项已用【】标识
server:port: 8081
spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8default-property-inclusion: non_nullcanal.conf:mode: tcp #tcp kafka rocketMQ rabbitMQflatMessage: true# zk地址【1】zookeeperHosts: 192.168.244.1:2181syncBatchSize: 1000# 出现报错时的重试次数retries: 0timeout:accessKey:secretKey:consumerProperties:# canal tcp consumer# deployer服务端地【2】# canal.tcp.server.host: 127.0.0.1:11111# zk地址【3】canal.tcp.zookeeper.hosts: 192.168.244.1:2181canal.tcp.batch.size: 500canal.tcp.username:canal.tcp.password:srcDataSources:# 源数据库地址,可配置多个canalDs: # 命名自定义【4】url: jdbc:mysql://192.168.244.17:3306/canal_test?useUnicode=trueusername: canalpassword: canalcanalAdapters:- instance: cluster # 服务端配置的实例名称【5】groups:- groupId: g1outerAdapters:# 开启日志打印- name: logger# 配置目标数据源【5】- key: es# es7 or es6name: es7 hosts: http://192.168.244.11:9200 # 127.0.0.1:9300 for transport modeproperties:mode: rest # or rest or transport# es账号密码security.auth: elastic:elastic # only used for rest mode# es集群名称cluster.name: blade-cluster
4、创建同步配置文件user.yml
vim conf/es7/user.yml
文件内容
注意事项:这里有一个坑点,就是书写的sql中不要用“``”符号括上你的表名,否则会导致无报错但数据一直无法同步
dataSourceKey: canalDs # 这里的key与上述application.yml中配置的数据源保持一致
outerAdapterKey: es # 与上述application.yml中配置的outerAdapters.key一直
destination: cluster # 默认为example,与application.yml中配置的instance保持一致
groupId:
esMapping:_index: user_type: _doc_id: idsql: "SELECTid,seq_no,name,age,address FROMuser"
# etlCondition: "where t.update_time>='{0}'"commitBatch: 3000
这里可根据自己的数据库表创建对应的文件,我这里只同步了一张表,es中的索引mappings如下,同步前请提前创建好索引
{"user" : {"mappings" : {"properties" : {"address" : {"type" : "text","analyzer" : "ik_smart"},"age" : {"type" : "integer"},"name" : {"type" : "keyword"},"seq_no" : {"type" : "keyword"}}}}
}
5、另一台adapter节点也同样配置
6、启动adapter
./bin/startup.sh

2.2.4 测试
1、我们在数据库中添加数据
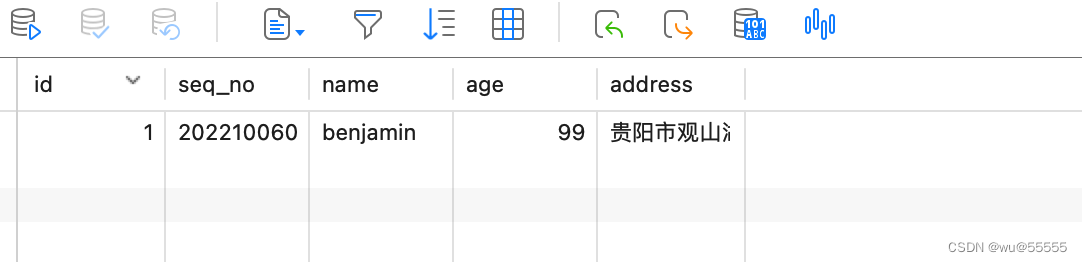
2、查看adapter节点日志
tail -f logs/adapter/adapter.log
节点1:

节点2:

可以看到数据同步分发到节点1了,同步成功后日志后会有Affected indexes: xxx 的字样
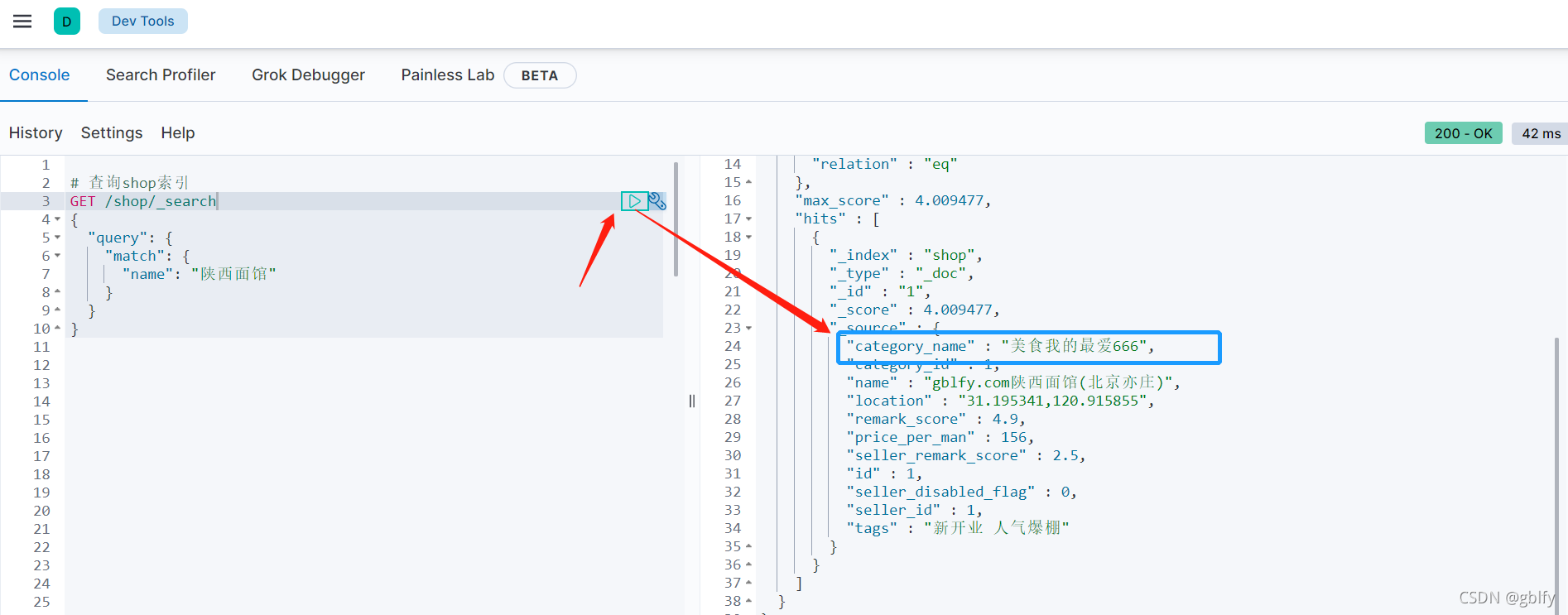
3、我们到kibana中查询数据
GET user/_search
结果显示同步正常

4、现在我们将正在工作的那台deployer服务关闭,模拟宕机
如果不知道哪台deployer正在工作,查看日志即可,不断有日志输出的就是正在工作的
cd ../deployer
./bin/stop.sh
5、查看备用deployer节点日志
cat logs/cluster/cluster.log
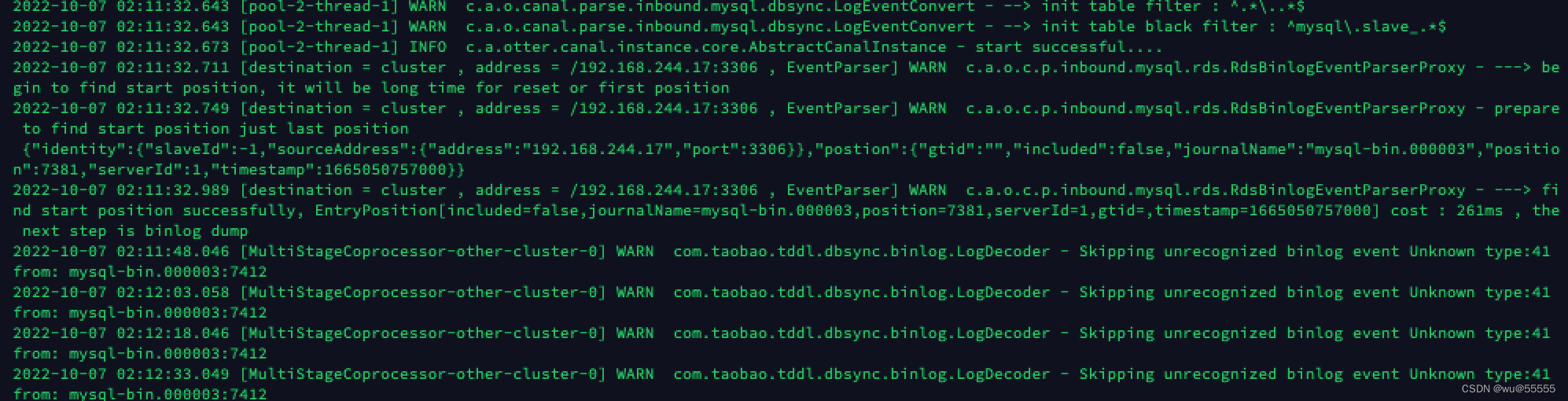
6、再新增一条数据,看看是否能正常同步
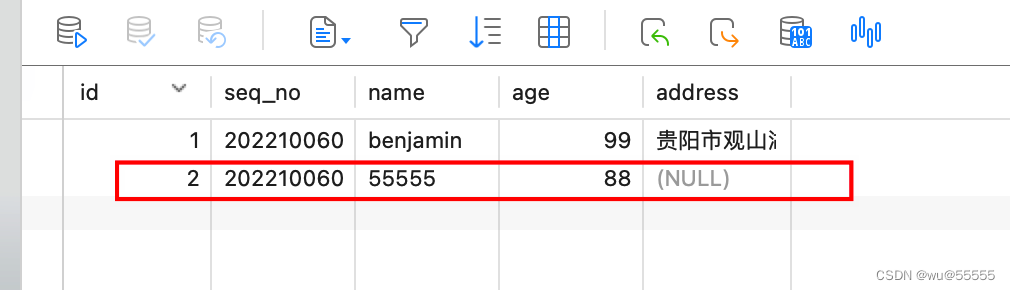
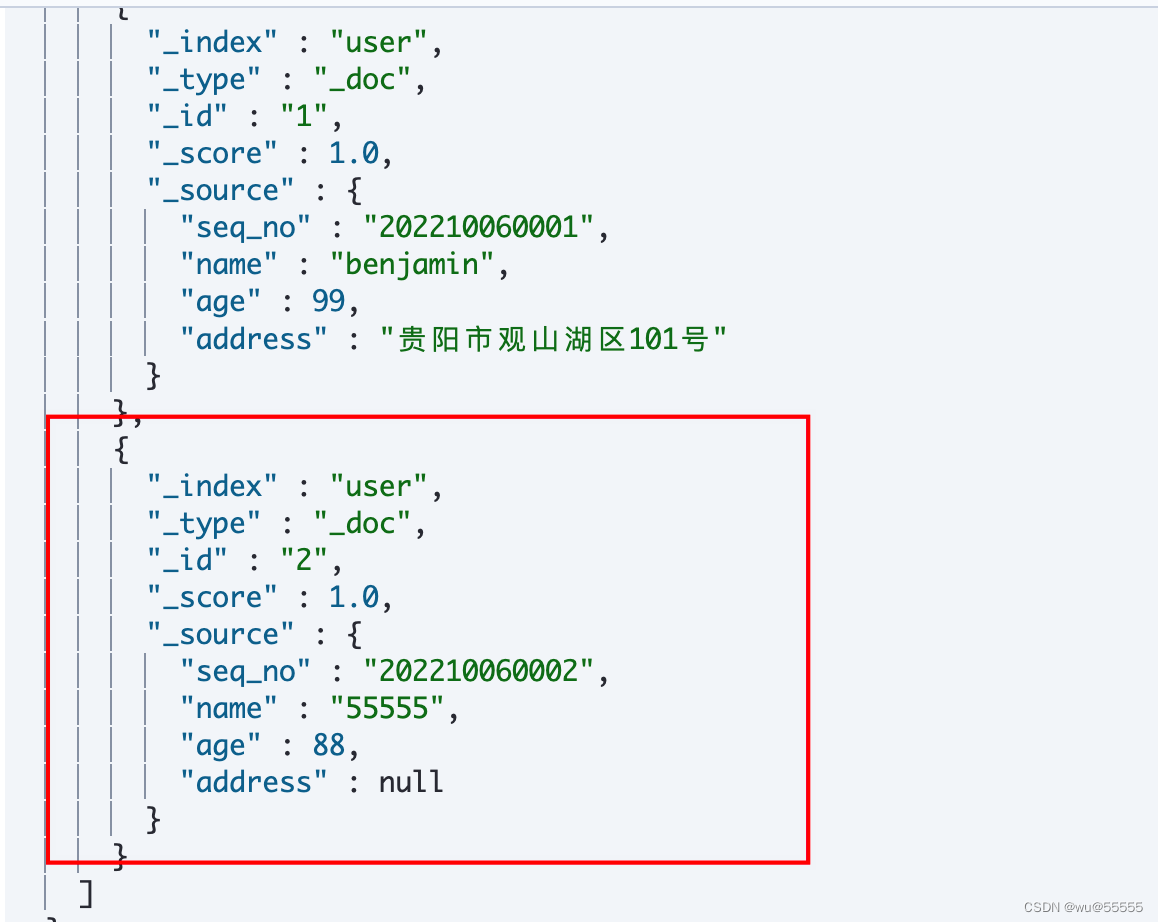
7、kibana中查看数据,数据同步成功,说明deployer节点自动切换成功
8、下面我们接着模拟一下adapter节点宕机:我们将其中一个adapter节点关闭
9、新增一条数据
10、查看kibana,数据正常同步

总结
deployer节点同时只会运行一个,而adapter节点是采用服务分发的机制,多节点同时服务,由zk分发请求到具体的adapter节点上执行数据同步任务
下期,我们接着讲讲如何结合canal-admin来管理集群节点