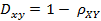文章目录
- 综述
- 腾讯 | 从零开始了解推荐系统全貌
- 阿里 | 新时期的阿里妈妈广告引擎架构
- 特征工程
- 推荐系统之数据与特征工程
- 数据生成
- 数据预处理:ETL
- 特征工程
- 未来
- 画像/用户行为
- 飞猪旅行用户理解服务架构
- 倒排
- 百度广告倒排服务极致优化
- 粗排
- 阿里粗排技术体系与最新进展分享
- 推荐系统(5):粗排工程实践与思考
- 美团搜索粗排优化的探索与实践 (2022-08-11)
- 效果优化:精排Teacher模型蒸馏粗排Student模型
- 效果性能联合优化:基于神经网络架构搜索的粗排建模方案
- 爱奇艺短视频推荐:粗排篇
- 腾讯音乐:全民 K 歌推荐系统架构及粗排设计
- 多样性保证:DPP概率模型
- 粗排阶段性能与效率的权衡:基于可学习特征选择的方法(2021-11-02)
- 精排
- 微博推荐实时大模型的技术演进(2023-04-24)
- 模型训练
- 百度基于 GPU 的超大规模离散模型训练框架 PaddleBox 与 FeaBox(2023-03-12 )
- PaddleBox:百度基于 GPU 的超大规模离散 DNN 模型训练解决方案
综述
腾讯 | 从零开始了解推荐系统全貌
https://www.6aiq.com/article/1601290232724
阿里 | 新时期的阿里妈妈广告引擎架构
https://www.6aiq.com/article/1654269863835
统一运行时 :所有模块选择统一的运行时框架,来托管PaaS层的能力
统一数据抽象 :将引擎依赖的各种数据统一抽象为Table(倒排/正排/KV等),业务开发只需要配置化地依赖Table,即可在自己的DAG中去直接消费。
统一业务抽象 :有了1/2后,继续对业务编程接口和算子进行规范化:算子的输入输出均为标准Schema的数据Table、去除对Session的依赖,从接口上让算子功能内聚;同时合理抽象所有算子的颗粒度,算子粒度变小之后,复用性大大提升。
优点:策略可以在不同模块复用。策略已经覆盖到了粗排、精排、重排等多个阶段,各阶段的逻辑要保持一致性,那么就需要相同的策略算子和子图在引擎的各阶段能够尽量复用。但是,不同阶段的计算特点不同,比如粗排广告比精排大一个数量级,但是精排广告比粗排计算精度要高,因此需要算子和子图能够以本地集成和服务化调用等多种形式来灵活部署和访问
特征工程
推荐系统之数据与特征工程
https://www.codenong.com/cs106528496/
讲解推荐系统所依赖的数据,怎么处理这些数据,让数据转换成推荐算法可以直接使用的形式,最终我们就可以构建高效、精准的推荐模型,这些处理好的适合机器学习算法使用的数据即是特征,而从原始数据获得特征的过程就是特征工程
数据生成
数据类型
- 特征数据源:用户行为、用户属性(画像)、item属性、上下文信息(当时的时间、地点、设备、app版本等)
- 数据类型:数值、文本、图片、音视频
- 数据组织形式:结构化(文本、数值类,比如用户、物品属性)、半结构化(日志信息)、非结构化(音视频)
数据收集
- 行为数据:客户端埋点上报
- 用户属性:注册时提前收集、app权限上报
- item属性:物料提供方具备
- 上下文信息:app实时获取
数据预处理:ETL
ETL(Extract-Transform-Load),用来描述数据从生产源到最终存储之间的一系列处理过程,一般经过抽提、转换、加载
E
- 行为数据:分离线和实时,离线通过ETL进入数仓,实时流通过Kafka等消息队列被实时(如Spark Streaming、Flink)处理,或者进入HBase、ES等实时存储供后面的业务查询
- 用户属性:一般实时性不高,如果实时性高的通过binlog、消息队列
- 上下文数据:实时流
T
由于抽取的数据多源、多端规范不一,所以需要对抽取的数据进行数据清洗、格式转换、缺失值填补、去重等操作,最终得到格式统一、高度结构化、数据质量高、兼容性好的数据,供推荐算法的特征工程处理。
L
加载是把数据加载至最终的存储,比如数据仓库、关系型数据库、KV等。对于离线的推荐系统,训练数据放到数仓中,属性数据存放到关系型数据库中。
特征工程
特征工程是将原始数据转换为特征的过程
特征的取值类型:离散特征、连续(数值)特征、时空特征、文本特征、富媒体特征
特征的可解释性:显式特征、隐式特征
特征工程的步骤
特征预处理:缺失值处理、归一化、异常值与数值截断、非线性变换
特征构建
- 离散特征:如性别、学历、视频类型、标签、导演。(编码方式:one-hot编码、散列编码、计数编码、离散特征之间交叉、离散特征与连续特征交叉)
- 连续(数值)特征:(编码方式:直接使用、离散化、特征交叉)
- 时空特征:(编码方式:转化为数值、将时间离散化)
- 文本特征:(编码方式:TF-IDF、LDA、Word2Vec)
- 富媒体特征:可转为向量表示
- 嵌入特征:基于内容的嵌入:使用标的物属性(如视频标题、标签、海报图、视频、音频等信息),通过 NLP、CV、深度学习等技术生成嵌入向量。基于行为的嵌入:基于用户与标的物的交互行为数据生成嵌入
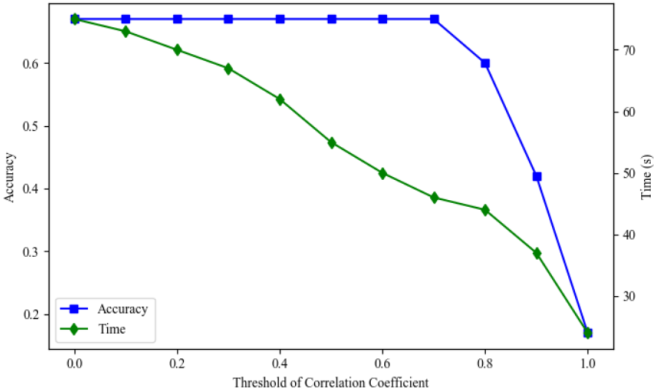
特征选择 - 基于统计量选择:选择方差大的特征、皮尔逊相关系数、覆盖率、假设检验、互信息(表示相关性)
- 基于模型选择:基于模型参数、子集选择 (自动选特征的技术方案)
特征评估:特征覆盖率、特征的维度、定性分析、定量分析
未来
融合更多的数据源来构建更复杂的推荐模型、深度度学习等复杂技术减少人工特征工程的投入、实时数据处理与实时特征工程(现在很多公司已经实现了)、自动化特征工程
画像/用户行为
飞猪旅行用户理解服务架构
https://zhuanlan.zhihu.com/p/618707844
RTUS:实时用户理解服务中心
把用户多方面、多维度的兴趣理解或者是意图预测存到实时DB内。下游各个场景如果需要用户各个维度理解时,直接调用接口去查询。实现数据复用,模型复用,减少性能开销。
- 多链路数据融合:对服务端日志、客户端日志、专链数据异步融合。用统一的schema进行数据收集,形成统一的数据链路
- 数据和模型复用: TODO
倒排
百度广告倒排服务极致优化
https://baijiahao.baidu.com/s?id=1752248929718505328
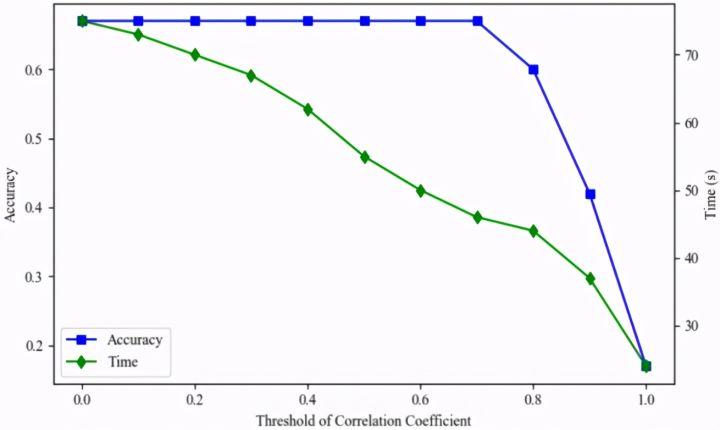
Array比较于List,对cache更友好。但是使用Array,如果满足修改实时生效,开销更大。因此文章提出了一种内存数据结构:HybridIndexTable(HIT)混合倒排表
特点
1 用HashMap索引keysign
2 短链采用连续存储,长链则是一棵叶子连续存储的前缀树,前缀树则参考了业界AdaptiveRadixTree,简称ART(重点在于自适应)
3 短链和叶子的连续存储都采用了自研的RowContainer,简称RC
但是注意,HIT是连续存储,但是append-only、标记删除
优化
1 通过LeafCompaction优化稀疏。因为key值分布稀疏,可能导致子树扇出小但是深度很深。通过自适应动态span提升平均扇出,降低树高,通过叶子合并解决叶子数据稀疏的问题
2 RCU(Read Copy Update)面向读者实现读写安全。这里不采用CAS是因为CAS常见写法是while循环直到成功,如果有10个线程都在高速修改一个链表尾巴,这时候CAS只是说把陷入内核省掉了,但是还是要不停地循环,不能完全释放并行的能力,最好能从业务上打散。另一方面,CAS也有问题,多核下 CPU cache coherence protocol总线仲裁,导致破坏流水线。
粗排
阿里粗排技术体系与最新进展分享
https://zhuanlan.zhihu.com/p/355828527
https://zhuanlan.zhihu.com/p/371025064
CODL Model serving中的优化
并行化:请求并行、多线程并行、GPU
行列转化:将行计算重构成列计算,对同一列上的稀疏数据进行连续存储,之后利用MKL优化单特征计算,使用SIMD优化组合特征算子,以达到加速的目的。
Float16:NVIDIA的Turning架构对Float16的矩阵乘法有额外的加速。使用MPS (Multi-Process Service)解决kernel启动的开销
推荐系统(5):粗排工程实践与思考
https://zhuanlan.zhihu.com/p/474874372
本文介绍的粗排架构是基于双塔的,可借鉴的点:对于双塔粗排,由于item向量训练可能为小时级,因此新入池的item是找不到item向量的。一种可行的做法是,对于这部分item,可以通过本地TF,来预估item向量,并embedding缓存到cache
美团搜索粗排优化的探索与实践 (2022-08-11)
https://tech.meituan.com/2022/08/11/coarse-ranking-exploration-practice.html
效果优化:精排Teacher模型蒸馏粗排Student模型
蒸馏方案
精排结果蒸馏:策略1:在用户反馈的正负样本基础上,随机选取少量精排排序靠后的未曝光样本作为粗排负样本的补充。策略2:直接在精排排序后的集合里面进行随机采样得到训练样本,精排排序的位置作为 label 构造 pair 对进行训练。策略3:基于策略2的样本集选取,采用对精排排序位置进行分档构造 label ,然后根据分档 label 构造 pair 对进行训练
精排预测分数蒸馏:希望粗排模型输出的分数与精排模型输出的分数分布尽量对齐
特征表征蒸馏:将对比学习技术应用到粗排建模中,使得粗排模型在蒸馏精排模型的表征时,也能蒸馏到序的关系
效果性能联合优化:基于神经网络架构搜索的粗排建模方案
同时优化粗排模型的效果和性能,选择出满足粗排时延要求的最佳特征组合和模型结构。
效率建模:为了在模型目标中建模效率指标,我们需要采用一个可微分的学习目标来表示模型耗时,粗排模型的耗时主要分为特征耗时和模型结构耗时。
爱奇艺短视频推荐:粗排篇
https://www.6aiq.com/article/1614422394959
本质上仍为双塔粗排
腾讯音乐:全民 K 歌推荐系统架构及粗排设计
https://www.6aiq.com/article/1615248202348
其基本结构仍然为双塔。思考方式可以借鉴:
路线1:把粗排作为召回的延伸,通过实时serving或实时指标对召回排序的结果做一个选择。
路线2:把粗排当成是精排的迁移或压缩(实际上现在都是路线2)
模型蒸馏,弥补子模型缺少复杂结构或交互结构导致的部分收益损失
特征蒸馏,通过一个更大的teacher模型学习全量特征,再把学到的知识迁移到子模型,即弥补了上述的部分特征损失
在粗排中使用时,结构仍为双塔,粗排模型未使用交叉特征。在user tower和item tower交互后,加上精排模型的logits信息,共同构成粗排的优化目标
多样性保证:DPP概率模型
选择出一个子集使得多样性和相关性联合建模的收益最大。直观理解,先基于多样性和相关性构建一个矩阵,该矩阵行列式的物理含义是矩阵中各向量张成的平行多面体体积的平方,这样就把问题转换成了一种可度量的方式:要想同时最大化多样性和相关性,只需要最大化平行多面体的体积。
DPP模型贯穿整个推荐链路,包括粗排后、精排后(rerank)
粗排阶段性能与效率的权衡:基于可学习特征选择的方法(2021-11-02)
https://zhuanlan.zhihu.com/p/428178907
精排
微博推荐实时大模型的技术演进(2023-04-24)
https://mp.weixin.qq.com/s/wRi0YJLpru5M1My0H2Ww0w
1. 技术迭代
1.1. 多目标
主要目标:点击、互动、时长、负反馈、完播、下刷
技术点: 融合系数计算:静态融合、离线计算升级为自动搜参。融合方式:打分公式融合升级为模型融合
1.2. 多任务
用1个模型训练好多个目标,优点
- a. 有相关性的目标之间通过浅层的共享表示互相分享、互相补充学习到的领域相关信息,从而相关目标互相促进学习,进而提升模型颈估能力
- b. 多任务学习的本质是迁移学习,互动目标通过迁移(共享)点击目标的浅层网络,可缓解互动目标正样本稀疏向题,这也是电商类公司借助多任务模型大幅提升转化率的主要原因
- c. 模型大小近似一个单目标模型大小,节省资源
- d. 平均多个任务噪声从市学习到更一般的表征,增强泛化能力
技术点: 从MMOE 开始,到 SNR,再到 DMT,最后到全量的 MM,其实就是在 SNR 上做了融合网络等优化。
1.3. 多场景
背景:场景有大有小,小场景收敛的没那么好,因为数据量不足,而大场景的收敛比较好,即使两个场景都差不多大,中间也会有一些涉及到知识迁移会对业务有收益。和多任务在技术上有很多相通的点。
技术点:
- a. 以MMOE/CGC为基础结构(京东DNDNN/美团MBN-V4):共享专家部分由多个场景样本联合训练,或主从结构有部分专家共享、部分专家独有,上层每个场景有各自独立的塔结构
- b. 阿里STAR模型:星结构,每个场景拥有自己独立的参数,同时场景间拥有共享的参数。场景间共享参数和场景独有参数相乘,得到实际每个场景的参数
- c. MDN base SNR
- d. SNR + EPNET
1.4. 兴趣表征
用户行为序列建模
技术点:pooling、attention(DIN)、RNN类(RNN\LSTM\GRU)、transformer(支持并行计算/与缓存提速,主要包括ATRank, BST, DSIN , TISSA, SDM , KFAtt , DFN, SIM, DMT)
把序列拉长(点击、时长、互动序列等),可能带来更好的算法效果,但是需要算力成本也更大。但是超长的序列,价值未必突出,大家关注点变化快,信息流中7天前的信息分发就较少了。太长的行为序列可能会对预估用户对item的偏好价值有减弱。当然也取决于不同场景。对低频/回流用户,结论可能不同
1.5特征
技术点
匹配特征:用户对于单个物料、单个内容类型、单个发博者建立一些比较详细的统计数据,都能带来一些收益。
多模态特征: 推荐模型是基于用户行为的,有一些低频、冷门的 Item 在整个系统中用户行为不足,引入更多的先验知识能带来更多收益。多模态通过引入 NLP 等技术引入一批语义进来,对于低频和冷启动都是有帮助的
链路表达一致性
粗排精排一致性:LTR
粗排模型优化:使用DNN和级联模型做STACKING架构。粗排内先用双塔做一层筛选,之后在过滤阶段给粗排的DNN模型。
模型训练
百度基于 GPU 的超大规模离散模型训练框架 PaddleBox 与 FeaBox(2023-03-12 )
https://zhuanlan.zhihu.com/p/613322265
PaddleBox聚焦训练性能、稳定性、成本
存储挑战:实现了分布式的 GPU 稀疏参数服务器、SSD 的超大的稀疏参数服务器
性能挑战:软件上,大小流水线架构,异构硬件最大化并行。硬件上:性能最优的CPU/GPU/SSD/网卡布局设计
通信挑战:升级网卡拓扑,GPU直接高速通信。梯度聚合+量化通信,降低数据量
FeaBox 基于 GPUBox 的一体化特征抽取框架
一体化流式框架,提升性能和易用性。基线复用+列存储,解决IO和重复计算问题。异构特征抽取,支持CPU/GPU混合特征抽取
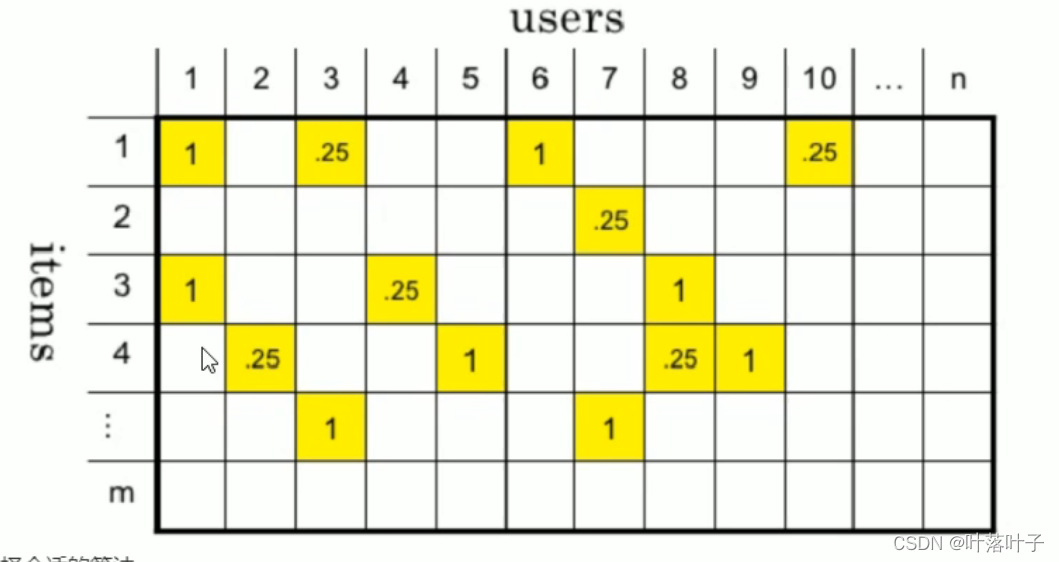
异构调度策略:
依据 DAG 的拓扑实现分层调度。在同层之内,尽量使得 CPU 和 GPU 去并行。在同一层内,首先异步的调度 GPU 节点,进行GPU 操作。再同步调用 CPU 节点,使得GPU和GPU并行执行。
对于同层的 GPU 节点,我们还又会做 KernelFusion 来减小 Launch 的开销。最后在 GPU 透传之后,将结果列转行,转到 CPU 的内部,最后弹出数据。
显存分配:显存池,在显存池上进行分层
显存分配方案
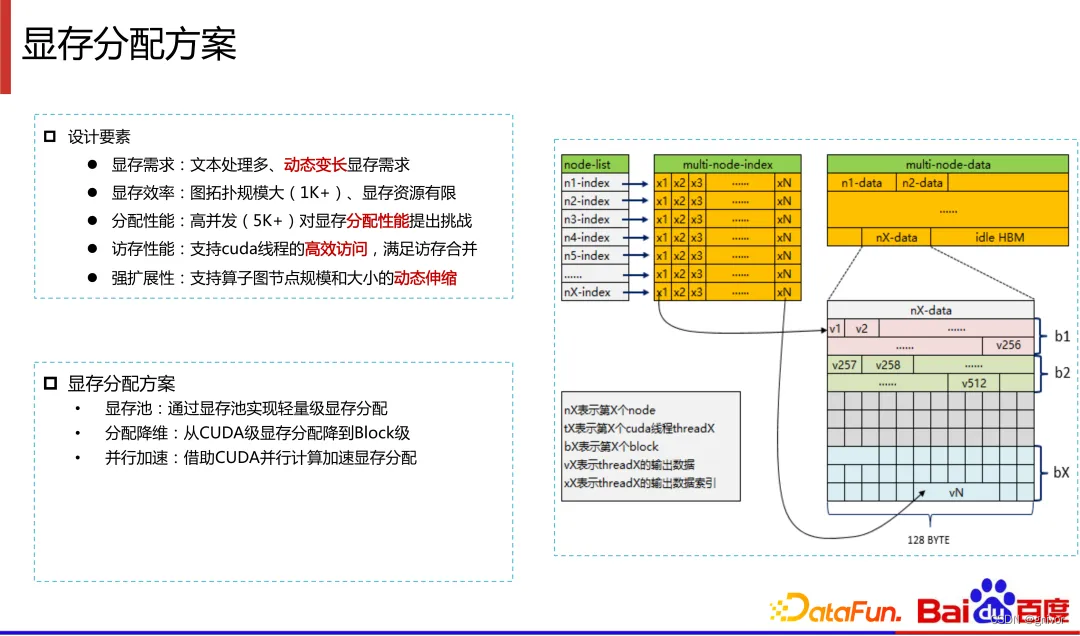
PaddleBox:百度基于 GPU 的超大规模离散 DNN 模型训练解决方案
https://www.6aiq.com/article/1667215658349
处理超大离散DNN模型的训练,传统分布式CPU解决方案存在成本问题、通信长尾和稳定性问题、算力问题。PaddleBox提出了基于GPU的分布式GPU 稀疏参数服务器
特点
存储大:支撑超大模型参数存储的SSD参数服务器
超大规模异构存储稀疏参数服务器,支持单机10TB、万亿维参数存储
IO优化 :构建多级全内存hash索引,实现对SSD数据一次性的准确读写,每次查询最多一次IO
查询剪枝 :结合数据访问的冷热比例,MEM Cache 存储热数据;使用BloomFilter判断当前key 是否在SSD上进一步降低无效的访盘次数。这两种剪枝策略使得SSD查询次数降低一个数量级
底层优化 :通过异步IO和数据对齐等优化技术,SSD读写性能提升5倍,直达SSD理论极限5*3GB/s
训练快:支撑参数高效访存的HBM参数服务器
采用SSD参数服务器后,单台GPU服务器即可进行超大模型训练,但是其训练速度却并没有得到很大提升。原因在于训练过程中Sparse参数的超高频CPU-GPU通信,无法充分发挥GPU超强算力。
解决:多机多卡分布式GPU稀疏参数服务器。HBM、MEM和SSD三层参数服务器自动化协同,既具备SSD的大容量,又具备HBM的高性能。