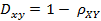点击上方“后端技术精选”,选择“置顶公众号”
技术文章第一时间送达!
作者:刚入道的大学僧
本文系投稿,原文内容点击阅读原文直达
一、分析背景与分析目的
随着科技的迅速发展,计算机的普及及对人类生活的渗透,越来越多的高校 开设“计算机科学技术”专业及其他相关专业,使其成为了全国热门专业之一,同时伴随着大量创新的计算机职业岗位的出现。岗位的出现必然对人才提出了充分的需求。
但是,就目前而言,计算机专业就业整体下滑。当前社会就业竞争激烈,IT行业虽然发展速度快、人才缺口逐渐增大,但是很多IT行业求职者求职目标不明确、不了解就业行情,大学毕业生的就业压力更是空前扩大,面对一个自己心仪的公司,可能要和很多人竞争一个岗位。对于有些专业技能硬和综合素质高的应聘者,由于不了解就业行情以及企业招聘需求、缺乏应聘经验和策略,屡次与自己理想的企业擦肩而过,而企业也不易招聘到所需的可靠型人才。
针对这一日益突出的就业问题,我们想到应用当今热门的大数据分析与应用技术,对计算机行业招聘信息做一些比较详细的分析。“大数据”在物理学、生物学、环境生态学等领域以及军事、金融、通讯等行业存在已有时日,近年来互联网和信息行业的发展而引起人们关注。随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。动辄达到数百TB甚至数十至数百PB规模的行业,企业大数据已远远超出了现有传统的计算技术和信息系统的处理能力。因此,寻求有效的大数据处理技术、方法和手段已经成为现实世界的迫切需求。人们将越来越多的意识到数据对企业的重要性。大数据时代对人类的数据驾驭能力提出了新的挑战,也为人们获得更为深刻、全面的洞察能力提供了前所未有的空间与潜力。
我们这一项目研究能够帮助应聘者以及即将步入社会的大学生大体了解策略和方法,在求职时有更清晰、明确的目的性和针对性。我们通过爬取各企业招聘信息,立足于帮助应聘者们明确企业需要什么样的技术型人才、各种职位的薪资水平以及热门程度、竞争力大小等等,对有关IT行业最新的的招聘信息进行统计和分析,并以网页和微信小程序等形式可视化呈现出来,力求帮助求职者更多地了解企业招聘的动向、职场信息的变化、当今社会最紧缺、最热门的技术等等。我们希望通过我们的数据分析,可以帮助学生或者准备跻身于IT行业的学习者们明确学习动向、确立更清晰的学习目标和努力方向;帮助求职者们在职场清晰完美的展现风采,增加就业竞争力;帮助企业招聘者了解国内各知名企业招聘的大体趋势,以便做好招聘方向的调整。
二、分析思路
在进行数据分析之前,我们团队已经对51Job人才招聘网等国内各招聘网站进行了招聘信息的爬取,我们主要利用Python爬虫技术获取到了网站上各计算机行业相关的不同地区的详细招聘信息,我们获取的信息属性主要包括信息来源、发布时间、招聘岗位名称、工作所在的省市、地区、对求职者工作经验的要求、学历要求、岗位职责要求、其他要求、员工福利、员工上限、员工下限、员工均值、招聘人数、工作所属公司、公司主要经营类别、公司性质、公司介绍、薪资区间、薪资上限、薪资下限、薪资均值,总计上百万条数据。
随后,我们又使用Kettle对这些数据进行了数据清洗。这些具有规模性、真实性、时效性、结构性的数据为我们团队的数据分析奠定了良好的基础。
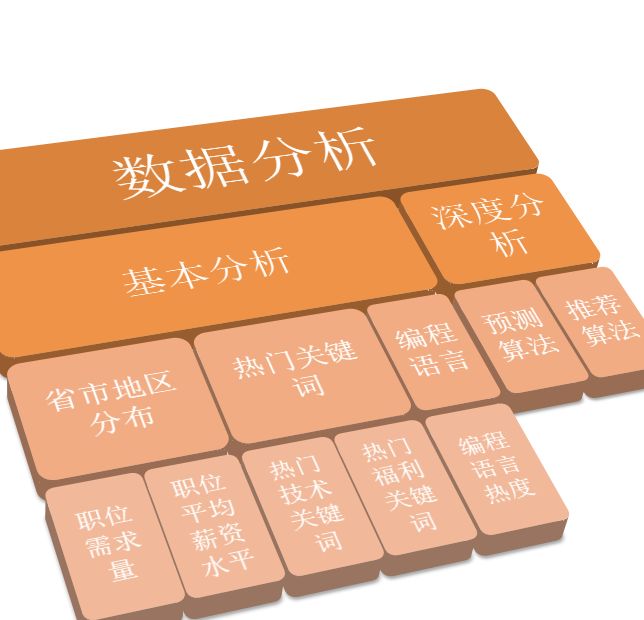
我们团队人员通过共同协商,最终决定先从各省市职位需求量及平均薪资水平、招聘信息中出现的热门技术关键词和福利关键词、编程语言热度等方面进行数据分析,然后再进行较为深度的时间序列预测、协同过滤推荐等算法分析。分析的工具主要选用Python3,因为Python中含有大量如同Pandas、Numpy、Matplotlib等第三方模块,非常方便数据的归类分析处理以及可视化展现。为了使数据分析的结果以更直观的形式展现,我们又使用了Tableau和java。
最终我们选择了通过网页前端以及手机客户端用户App两种软件形式比较完美地将数据展示出来。我们拟定的数据分析主要内容层次结构如下图所示:
三、分析内容
1、我们首先从整体分析,从全国各地区计算机相关职位需求量的分布情况入手进行分析,主要分为三个步骤,层层递进。
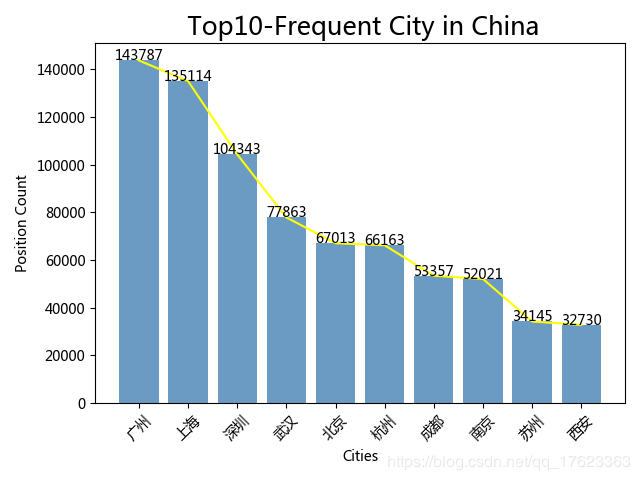
1)第一步,我们首先做了对各个城市职位需求量的统计,得到了存放相关数据的表格,并选择了职位需求量排名最多的前十名城市通过matplotlib进行展示,如下图所示:
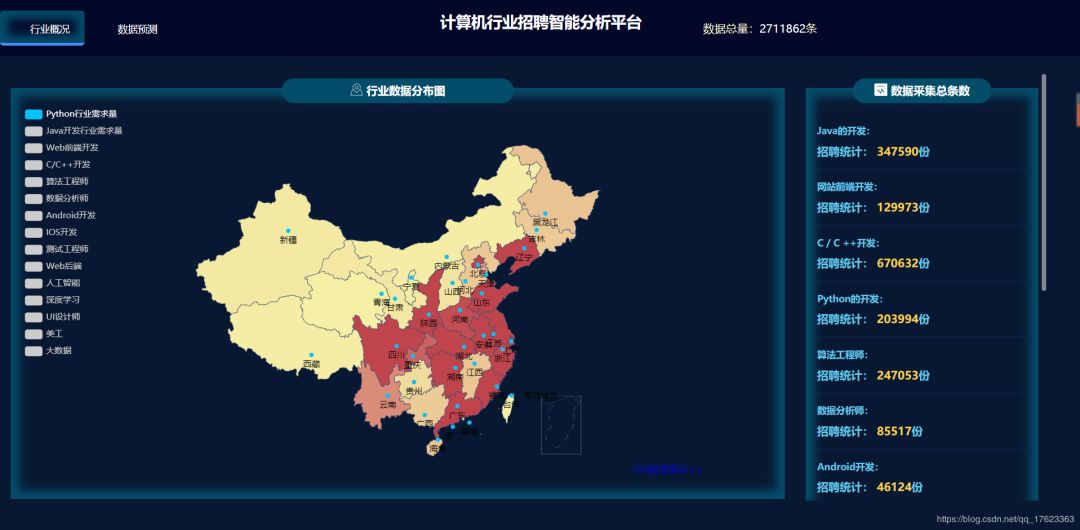
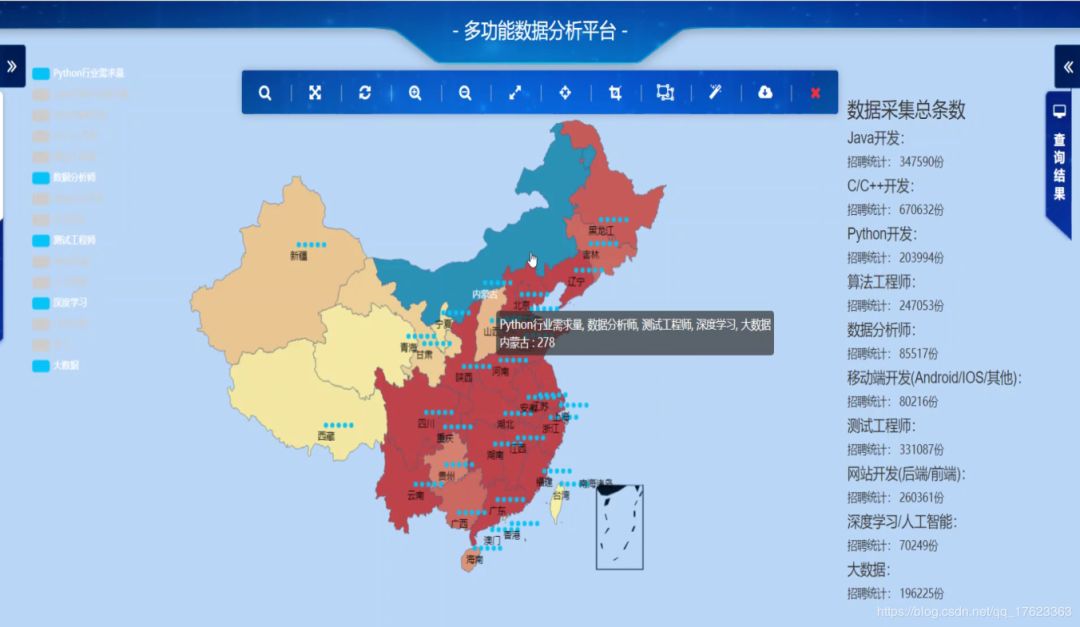
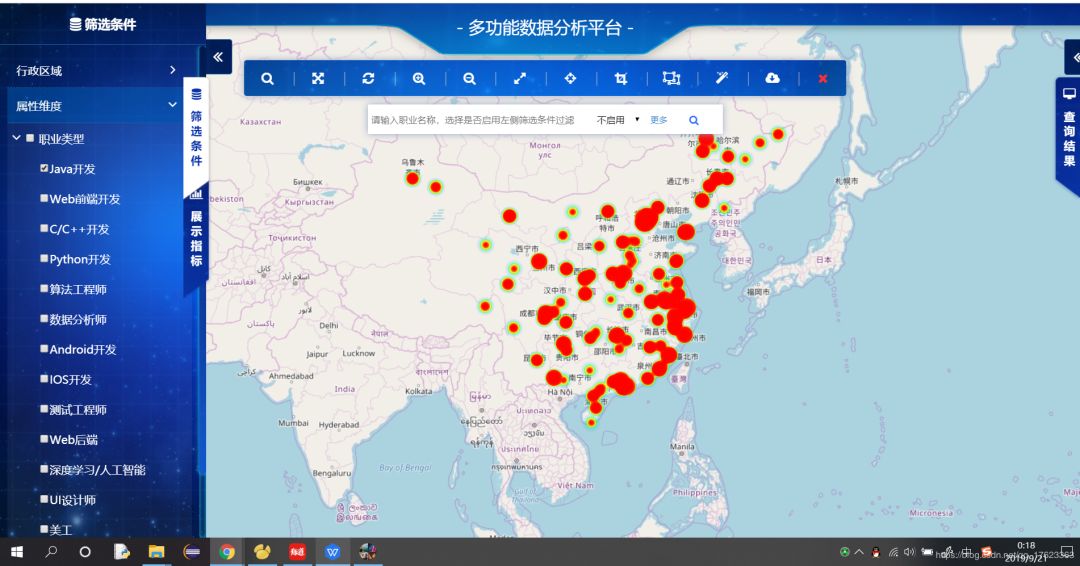
2)那么各个地区都需要招聘什么岗位呢?于是我们将各地区的招聘信息按照职位不同进行分类,统计各地区不同职位的招聘需求量,侧面反映出就职岗位的热度。图3所示以广州市为例,最热门的职位招聘需求量统计。由于这条分析内容较为复杂,为了更有层次感地完成这项分析任务,我们创建了数据库,并在自己开发的网站上利用SpringBoot、Mybatis连接高德地图API进行经纬度匹配,利用多维度GIS方式展示,效果图如图4所示: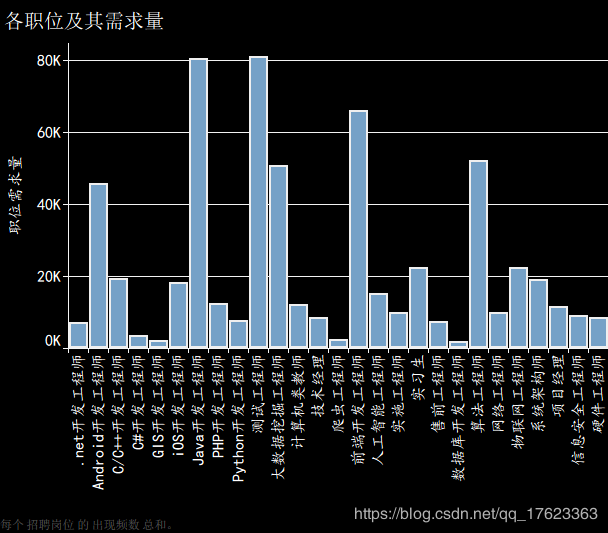
3)每个岗位的薪资水平又如何呢?这些职位的最高薪资和最低薪资的差距有如何?对此,我们进行了稍微更深层次的分析。根据较为科学的统计方式,平均水我们选用算术平均数来表示,薪资上下限的差距属于数据的离散程度,因此我们选用了标准差这一指标,数学理论计算公式如下:
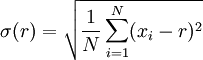
其中,N代表自由度,xi表示不同样本的值,这里指各个职位的薪资均值,r表示样本均值,这里指所有职位薪资均值的平均值。根据公式我们进一步编写了python程序并得到了进一步分析之后的数据,用Tableau呈现的效果图如图6。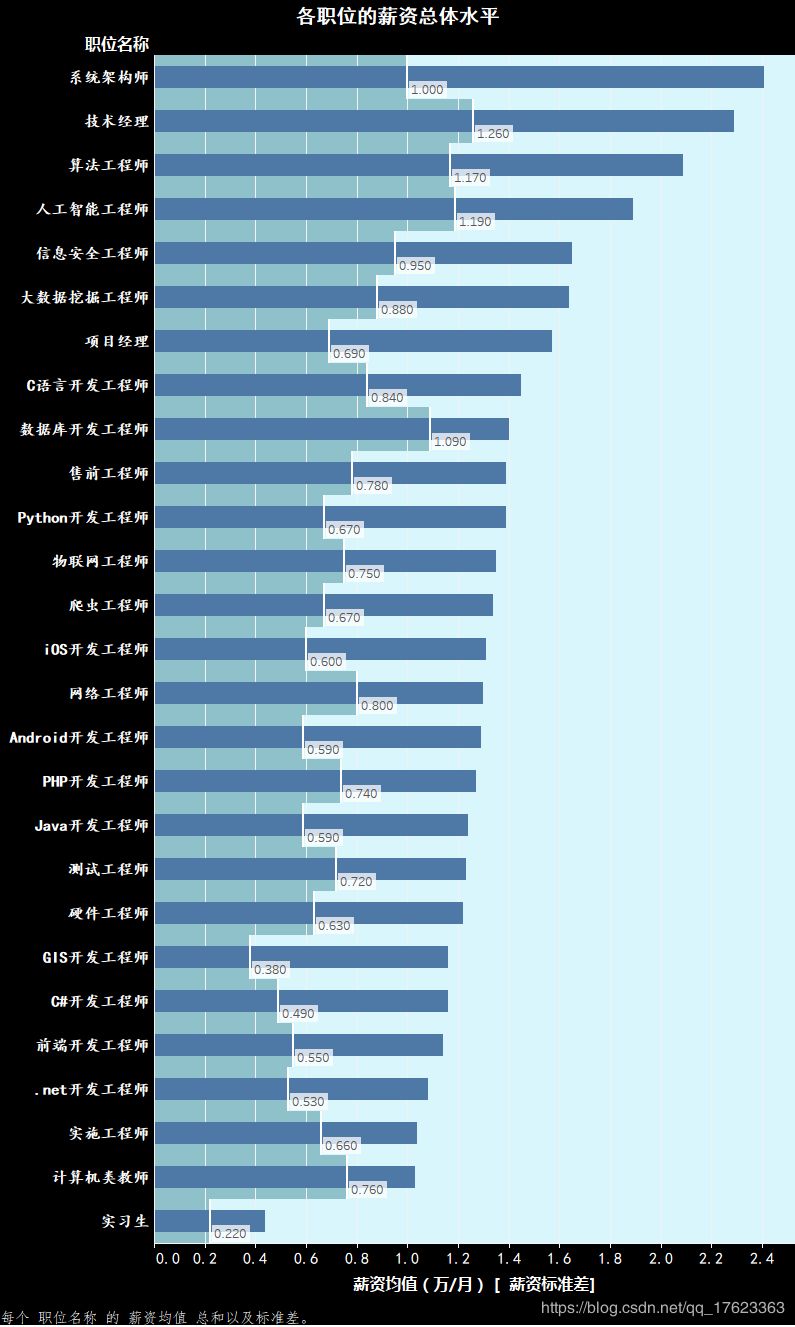
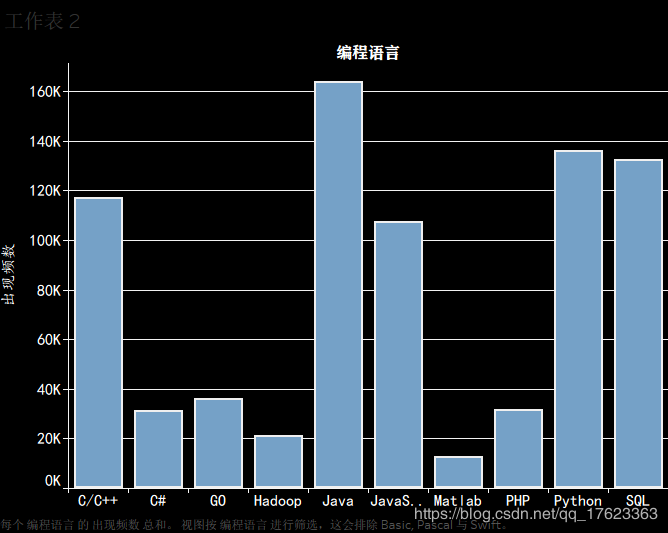
2、最热门的几种编程语言,根据招聘信息中编程语言出现次数而统计热门度。
3、我们利用python3的jieba模块对招聘信息进行关键字提取,最热门的技术,统计出几种最热门的技术关键词,所占比重如下图: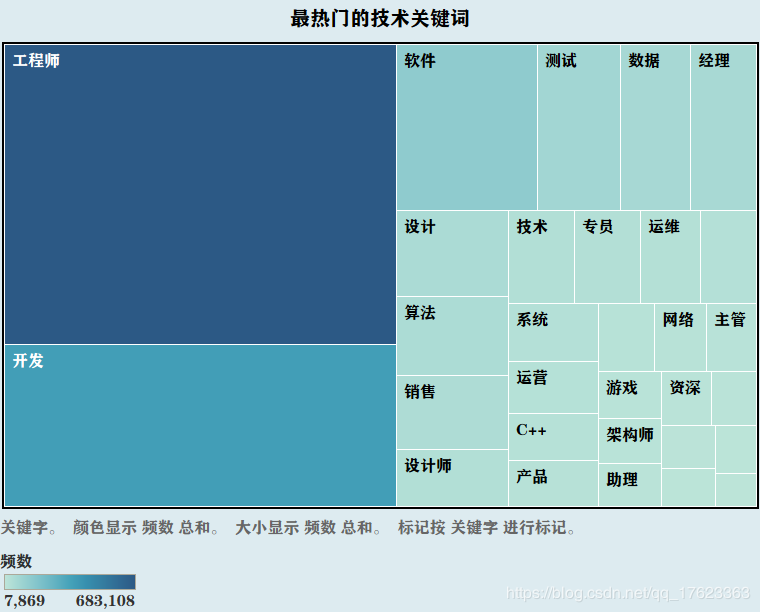
4、求职者非常关心工作的福利待遇,因此我们又对各企业对招聘职位的福利进行了关键词提取分析,各关键词占比如下图。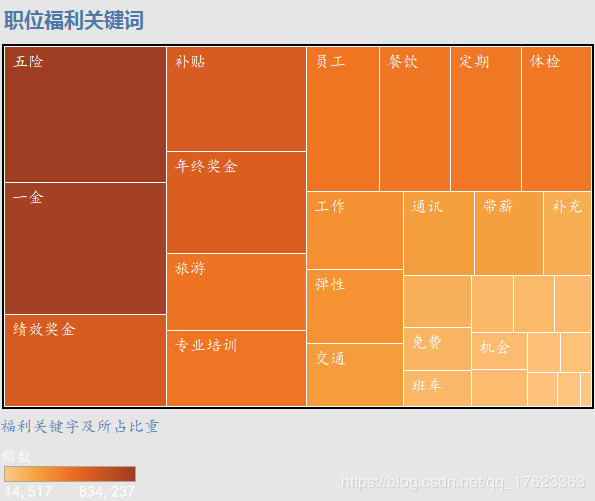
5、以上数据分析结果只是能展示出来,没有明显的实用效益。为此,我们更深入地探究了一下,采用了数据预测算法预测趋势数据预测采用ARIMA模型(Autoregressive Integrated Moving Average model),差分整合移动平均自回归模型,见图10,通过数据与本身之间的关系进行对未来数据走向的预测。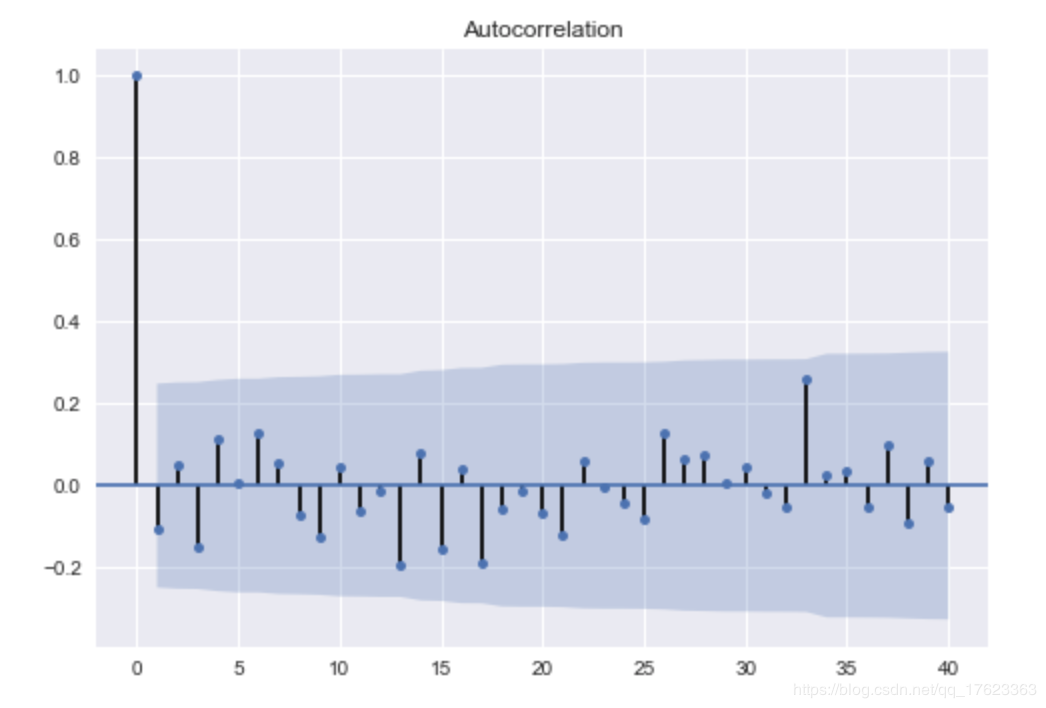
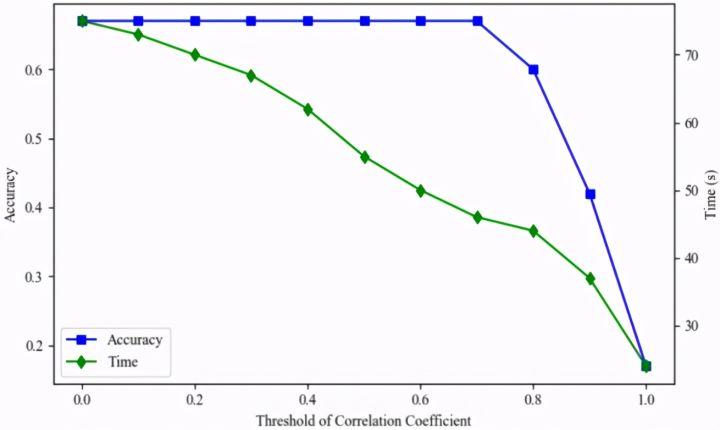
6、我们还进行了一项深入分析——基于皮尔逊相关系数的协同过滤算法。根据这个算法,我们就可以为不同用户推荐他们各自感兴趣、适合他们的招聘信息。皮尔逊相关系数( Pearson correlation coefficient),又称皮尔逊积矩相关系数(Pearson product-moment correlation coefficient,简称 PPMCC或PCCs),是用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。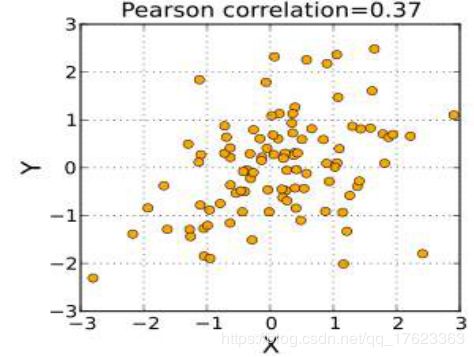
四、结论与总结
通过对采集到的计算机相关招聘信息的较为详细的分析,我们团队总结出了以下几点结论:
1、总体而言,我国计算机行业相关的职位需求量很大,尤其广州、上海、深圳等科技发达的沿海城市,对计算机类人才的需求还是很多的。其中职位需求量最大的为广州市,在本次统计中累计达到148737。
2、从计算机相关的各职位而言,开发类工程师的人才需求量非常多,且薪资水平是相当高的。此外,由于如架构师这样的职位必须具备非常广泛的专业技能,所以这类职位薪资水平相对较高,本次我队统计的架构师薪资均值高达约2.4万人民币/月。计算机类的工程师、开发人员的薪资水平一般是远高于计算机类讲师的。一般企业中管理者、经理的薪资都要高于普通员工、实习生的薪资,分析结果符合职场形势。
3、从编程语言的热门度而言,根据我们采集到的这些数据中显示结果,Java还处于企业招聘最看重的一门语言,因为Java语言的功能强大,很多企业运营的软件项目都离不开Java相关的程序编写,而且继承了多年以来的Java在项目开发中的重要作用,这种大的趋势潮流不易被突破。其次,由分析结果可知,企业招聘中Python、SQL、C/C++、JavaScript的出场率也是非常高的。毕竟据官方统计,Python和JavaScript近年来热度不断上升,随着用途的不断增加,功能不断增强,根据ARIMA算法预测将来这两种语言热度还会呈上升趋势。而SQL、C/C++则是非常经典、稳定的语言,在很多开发项目中具有不可替代的作用,因此公司招聘对其非常重视。
4、大部分企业都会拿“五险”、“ 一金”、“ 年终奖金”等福利待遇来吸引求职者,而这些福利恰好也是大部分求职者渴望得到的。总而言之,我们团队通过自己采集国内计算机相关招聘信息,并对这些数据并进行一系列分析,从各方面把我国当前计算机行业就业情况做了一定的了解和汇报,而得到的结果总体而言符合实际,基本与官方权威统计一致。虽然我们进行数据分析的方案和做法还存在很多不足,但这一过程中我们获益匪浅,进步了很多,我们仍会继续努力,力求统计更具规模性、多样性、及时性的数据,采用更加有效的分析方式,研究更高性能、更深层次的数据挖掘算法,这样才能总结、展示出更加真实、有效的分析成果。
附: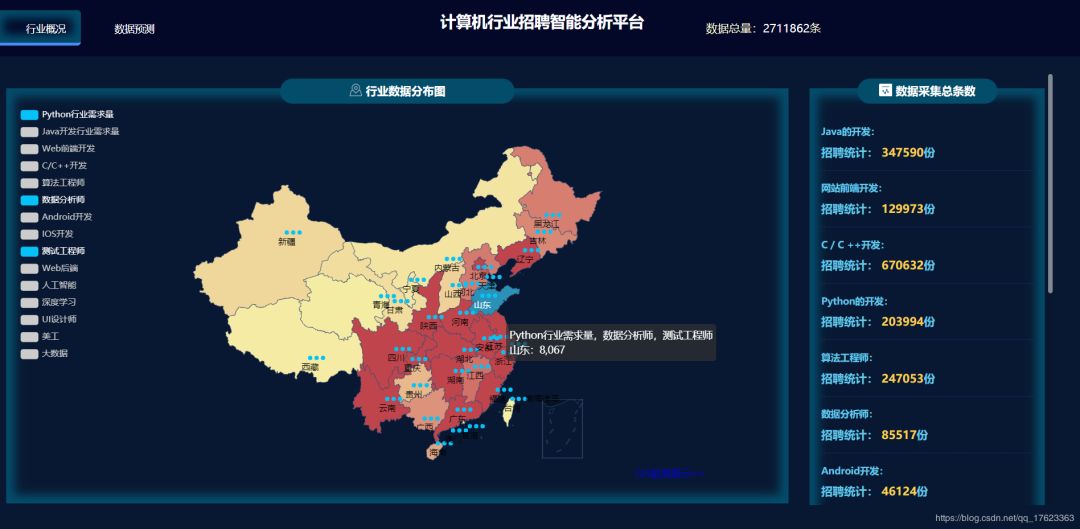
 代码量太大,就不贴代码了。
代码量太大,就不贴代码了。
推荐阅读(点击即可跳转阅读)
1.
2.
3.
4.
5.