前言
本实例采用python3环境,编辑器采用Jupyter Notebook,安装使用方法请参考,本实例中所用到的附件内容放在文末,如果想要自行运行一下代码,可以尝试一下。
Jupyter Notebook介绍、安装及使用教程
亲和性分析示例
终于迎来了第一个数据挖掘的例子,我们拿这个亲和性分析的示例来具体看下数据挖掘到底
是怎么回事。数据挖掘有个常见的应用场景,即顾客在购买一件商品时,商家可以趁机了解他们
还想买什么,以便把多数顾客愿意同时购买的商品放到一起销售以提升销售额。当商家收集到足
够多的数据时,就可以对其进行亲和性分析,以确定哪些商品适合放在一起出售。
实例代码和注释
import numpy as np #导入numpy库,并在下面调用时简写为np
dataset_filename = "affinity_dataset.txt"
#将txt文件内容赋值给变量dataset_filename
#使用numpy库的loadxt方法,读取txt文件,将读取后的内容赋值给变量X。此时的X存储的是一个数据集,例如
#[[1,2,3],
# [4,5,6]]
X = np.loadtxt(dataset_filename)
#每一个X都有一个shape属性,是对X向量的描述,samples指样本,features指特征
# X:shape(n_samples,n_features)
# eg:x:[[1,2,3],[4,5,6]]
# n_samples:2
# n_features:3
n_samples, n_features = X.shape
#输出数据集中有多少个样本多少个特征
print("这个数据集有 {0} 样本和{1} 个特征".format(n_samples, n_features))
运行结果

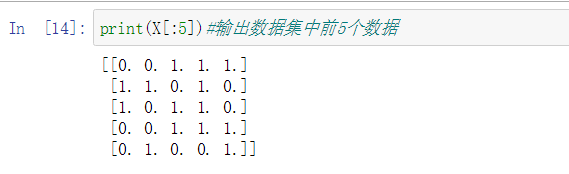
print(X[:5])#输出数据集中前5个数据
运行结果
features = ["bread", "milk", "cheese", "apples", "bananas"]# 定义一个由5种商品组成的数组
# 首先,这些行都有一个前提:一个人买苹果
num_apple_purchases = 0 #设置购买苹果次数的初值为0
for sample in X: #for循环利用数据集X中的数据表示多次购买if sample[3] == 1: # 因为在features数组中苹果的索引为3,所以sample[3]==1表示这个人买苹果num_apple_purchases += 1 #每当有人购买苹果时,购买苹果的次数加一
print("{0}个人买了苹果".format(num_apple_purchases)) #输出循环结束后购买苹果的次数
运行结果

# 一个人买苹果的案例中有多少与买香蕉的人有关?
# 记录规则有效和无效的两种情况。
rule_valid = 0 #定义变量rule_valid,记录有效的情况
rule_invalid = 0 #定义变量rule_invalid,记录无效的情况
for sample in X: #for循环利用数据集X中的数据表示多次购买if sample[3] == 1: # 如果这个人买苹果if sample[4] == 1: #如果这个人还买了香蕉# 如果这个人买了苹果和香蕉,规则有效的情况加一rule_valid += 1else:# 如果这个人买了苹果,没有买香蕉,规则无效的情况加一rule_invalid += 1
# 输出规则有效出现的次数
print("{0} 次发现了该规则有效的案例".format(rule_valid))
# 输出规则无效出现的次数
print("{0} 次发现了该规则无效的情况".format(rule_invalid))
运行结果

# 现在我们有了计算支持度和置信度所需的所有信息
support = rule_valid # Support是发现规则的次数,即置信度。
# 发现规律的次数除以购买苹果总的次数得到规律得到支持度confidence
confidence = rule_valid / num_apple_purchases
# 输出发现规则的次数和计算所得的支持度
print("支持度为 {0} 并且置信度为 {1:.3f}.".format(support, confidence))
# 支持度可以用以下公式表示为百分比:
print("按百分比算,置信度为 {0:.1f}%.".format(100 * confidence))
运行结果

from collections import defaultdict #导入defaultdict库
# 现在计算所有可能的规则
#用defaultdict(int)设置默认类型为int,初始值为0,用于计数
valid_rules = defaultdict(int)
invalid_rules = defaultdict(int)
num_occurences = defaultdict(int)
for sample in X:for premise in range(n_features): # n_features在这里表示的是一个人买商品的个数,买了几个商品就循环几次if sample[premise] == 0: continue # 判断该行的某一列元素是否位0,即是否购买,若为0,跳出本轮循环,测试下一列# 记录有购买的一列num_occurences[premise] += 1for conclusion in range(n_features): #当读取到某一列有购买后,再次循环每一列的值if premise == conclusion: #排除相同的一列,若循环到同一列,则跳出循环,比较下一列continueif sample[conclusion] == 1: #当sample[conclusion] 的值为1时,满足了当顾客购买前一件商品时也买了这种商品#记录下该规则出现的次数valid_rules[(premise, conclusion)] += 1else:#当不满足时即 sample[conclusion]=0 时,记录下不满足该规则的次数invalid_rules[(premise, conclusion)] += 1
support = valid_rules #支持度=规则出现的次数
confidence = defaultdict(float) #强制将置信度转为浮点型#计算某一规则的置信度,并将其存在字典confidence中
for premise, conclusion in valid_rules.keys():confidence[(premise, conclusion)] = valid_rules[(premise, conclusion)] / num_occurences[premise]
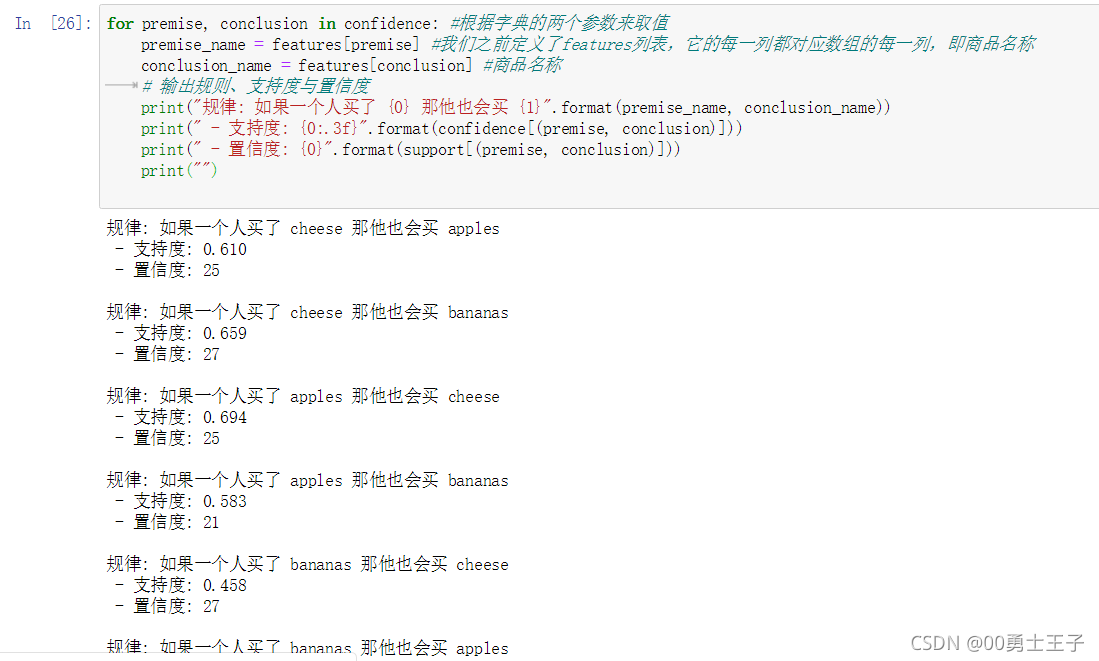
for premise, conclusion in confidence: #根据字典的两个参数来取值premise_name = features[premise] #我们之前定义了features列表,它的每一列都对应数组的每一列,即商品名称conclusion_name = features[conclusion] #商品名称# 输出规则、支持度与置信度print("规律: 如果一个人买了 {0} 那他也会买 {1}".format(premise_name, conclusion_name))print(" - 支持度: {0:.3f}".format(confidence[(premise, conclusion)]))print(" - 置信度: {0}".format(support[(premise, conclusion)]))print("")运行结果
def print_rule(premise, conclusion, support, confidence, features): #定义函数,用于输出规则‘支持度与置信度premise_name = features[premise] #我们之前定义了features列表,它的每一列都对应数组的每一列,即商品名称conclusion_name = features[conclusion] #商品名称# 输出规律、支持度与置信度print("规律: 如果一个人买了 {0} 那他也会买 {1}".format(premise_name, conclusion_name))print(" - 支持度: {0:.3f}".format(confidence[(premise, conclusion)]))print(" - 置信度: {0}".format(support[(premise, conclusion)]))print("")
premise = 1
conclusion = 3
# 调用函数输出规则
print_rule(premise, conclusion, support, confidence, features)
运行结果

# 按支持排序
# pprint()模块打印出来的数据结构更加完整,每行为一个数据结构,更加方便阅读打印输出结果
from pprint import pprint #导入pprit模块
pprint(list(support.items())) #完整打印出list(support.items())
运行结果

from operator import itemgetter #导入itemgetter模块
# 对class_counts字典进行排序,找到最大值,就能找出具有给定特征值的个体在哪个类别中出现次数最多
sorted_support = sorted(support.items(), key=itemgetter(1), reverse=True)
# 对置信度字典进行排序后,输出置信度最高的前五条规则
#用for循环输出规则
for index in range(5): print("规律 #{0}".format(index + 1))(premise, conclusion) = sorted_support[index][0]print_rule(premise, conclusion, support, confidence, features)运行结果

# 输出置信度最高的规则。首先根据置信度进行排序
sorted_confidence = sorted(confidence.items(), key=itemgetter(1), reverse=True)
# 对置信度字典进行排序后,输出置信度最高的前五条规则
#(ps:这15和13不是一模一样的吗,什么鬼)#用for循环输出规则
for index in range(5): print("Rule #{0}".format(index + 1))(premise, conclusion) = sorted_confidence[index][0]print_rule(premise, conclusion, support, confidence, features)运行结果

附件:affinity_dataset.txt
将下面的数据复制粘贴到txt文件中并命名为affinity_dataset.txt即可
0 0 1 1 1
1 1 0 1 0
1 0 1 1 0
0 0 1 1 1
0 1 0 0 1
0 1 0 0 0
1 0 0 0 1
1 0 0 0 1
0 0 0 1 1
0 0 1 1 1
1 1 0 0 1
0 1 0 0 0
0 0 0 0 1
0 0 1 0 1
0 1 0 0 1
0 0 1 1 1
1 0 0 0 1
0 0 1 1 1
1 1 0 0 0
0 1 0 0 0
0 0 1 0 0
0 1 0 0 1
0 1 0 0 0
0 1 0 0 1
0 0 1 1 1
0 0 1 1 0
0 0 1 0 1
0 0 0 0 1
0 1 0 0 0
0 1 0 1 0
1 1 1 0 1
1 1 0 0 1
0 0 1 1 1
0 0 1 0 1
0 0 1 1 1
0 0 1 1 0
0 1 1 0 1
0 0 1 1 0
0 1 0 0 1
0 0 0 0 1
0 0 1 0 1
1 1 0 1 1
1 0 0 0 1
0 0 1 1 1
0 1 0 0 0
0 1 0 1 1
0 1 0 0 0
0 1 0 0 0
0 0 1 1 0
0 0 1 1 1
0 1 0 1 0
0 1 1 0 0
0 0 1 1 0
0 0 1 1 1
1 0 0 0 0
0 1 0 1 0
1 0 0 0 1
0 1 0 0 0
0 0 0 0 1
0 0 1 1 1
0 1 1 1 1
1 1 0 0 0
0 0 1 0 1
1 0 0 0 1
1 1 0 0 0
0 1 1 0 0
0 0 0 0 1
0 1 0 0 0
0 0 1 1 1
0 1 0 0 1
1 0 0 0 1
1 0 0 0 1
0 1 0 0 1
0 0 1 1 1
1 0 1 0 1
1 1 0 0 1
0 1 0 0 1
1 1 1 0 1
0 0 1 1 1
1 0 0 0 0
0 0 1 1 1
1 1 0 1 0
0 0 1 0 0
0 0 1 0 1
0 1 0 0 0
1 1 0 0 0
0 0 0 1 0
0 0 0 1 1
0 1 0 0 0
0 1 0 0 0
1 1 0 0 1
0 0 1 0 0
0 1 0 0 1
1 1 0 1 0
1 0 0 0 1
0 1 0 0 0
0 0 1 1 0
0 1 1 0 0
0 0 1 1 0
0 0 0 0 1