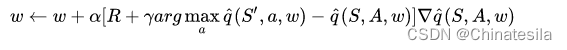目录
机器学习求解组合优化问题
求解组合优化问题的传统方法
精确算法:
启发式算法:
机器学习的相关知识
注意力机制
深度强化学习
主线奖励和稀疏奖励问题:
稀疏奖励问题:
辅助奖励函数设计
On-Policy 和Off-Policy问题:
Online和Offline问题:
无模型和有模型问题:
函数拟合算法:
机器学习求解组合优化问题
组合优化的一些基本问题
(1)背包问题KP有限容量背包和一系列具有不同重量和价值的物品,可行解集合由物品集合组成,物品的总重量不超过背包的限制,目标是最大化背包内物品的价值。(2)旅行商问题TSP一组城市,目标是找到只访问每一个城市一次并返回起点的最短的路径,问题定义在一个无向边权图上,每个边具有不同的权重,可行解集合是所有的只访问每一个城市一次并返回起点的路径,目标函数是最小化路径的权重和。(3)车辆路径问题VRPTSP问题的一个推广,目标是找到访问所有城市的最佳路线,使得总成本最小,路线长度、时间、或者车辆数量,同时满足约束条件。(4)极大团问题MC给定无向图,目标是找到最大的节点子集构成团,G的一个团是G的一个完全子图。(5)最大割问题(MaxCut)(6)最小顶点覆盖问题(MVC)(7)最大独立集问题(MIS)(8)最大覆盖问题(MCP)(9)可满足性问题(SAT)
求解组合优化问题的传统方法
精确算法:
分支定界法、动态规划法优缺点:能够得到问题的精确解问题规模扩大时,该类算法需要很大的计算量,难以扩展到大规模问题近似算法:贪心、局部搜索算法、线性规划、松弛算法、序列算法优缺点:在可接受的时间内得到一个近似的最优解,解的质量具有理论保证,当问题规模很大时,开销依然很大。
启发式算法:
模拟退火、禁忌搜索、进化算法、粒子群算法优缺点:比精确算法、近似算法快,但是对解的质量没有保证
机器学习的相关知识
注意力机制
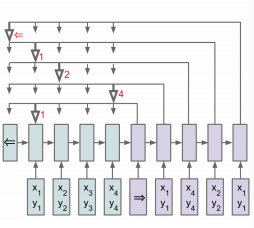
注意力机制(Attention Mechanism)是人们在机器学习模型中嵌入的一种特殊结构,用来自动学习和计算输入数据对输出数据的贡献大小。本文以一个基于注意力机制的机器翻译模型为例,从人的直觉、中英文翻译的常识、特征工程等角度,对注意力机制的思想和机理进行了阐述;并介绍了一种常见的注意力机制实现形式,即基于感知机的注意力机制;还介绍了一种比较经典的注意力机制,即自注意力机制(self-attention)解释:数据处理的一种方式,有选择性的处理信号,即对接收到的数据,选择性的关注其中一部的特征,而不是全部。特征工程:模型外部的注意力机制对原始的特征进行筛选,得到一个高质量的特征子集,这样可以帮助模型选择最有效,适当规模的特征。深度学习领域的注意力机制目的,让模型学会为输入的各个维度打分,然后按照得分对特征加权,以突出重要特征对模型后续部分模块的影响。接下来以一个循环神经网络为例子,介绍注意力机制的运用,这是没有注意力机制时的情况编码器最后生成z4而解码器部分只以z4和y序列的输出来得到最后结果,这在某些情况下时不合理的,忽略了相关性的因素。例如在翻译的过程中,从前到后,I对应我,此时不需要考虑到后续的输入,因此,直接使用z4是不是不合理呢,而中国人的人字就需要综合考虑前面的所有输入以及输入翻译得到的结果。这里使用注意力机制做了什么呢,其实就是计算了编码器和解码器在各个时间步的输出的相关度。
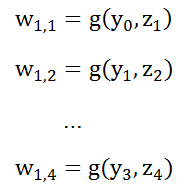
表示编码器神经元的第i个输出对于解码器的第j个输出的贡献,
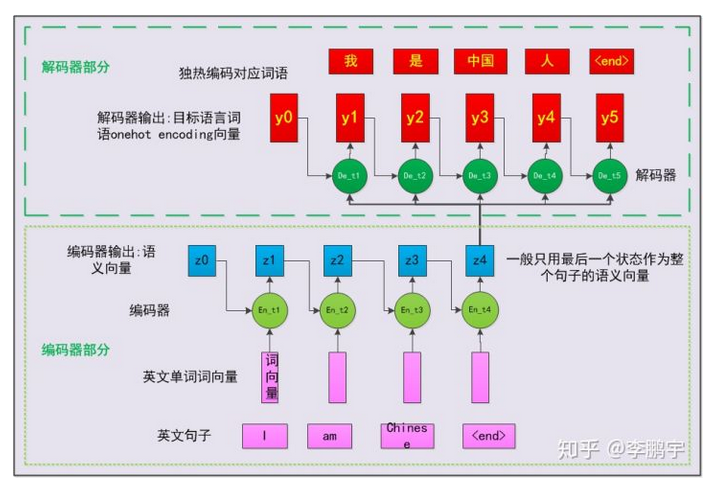
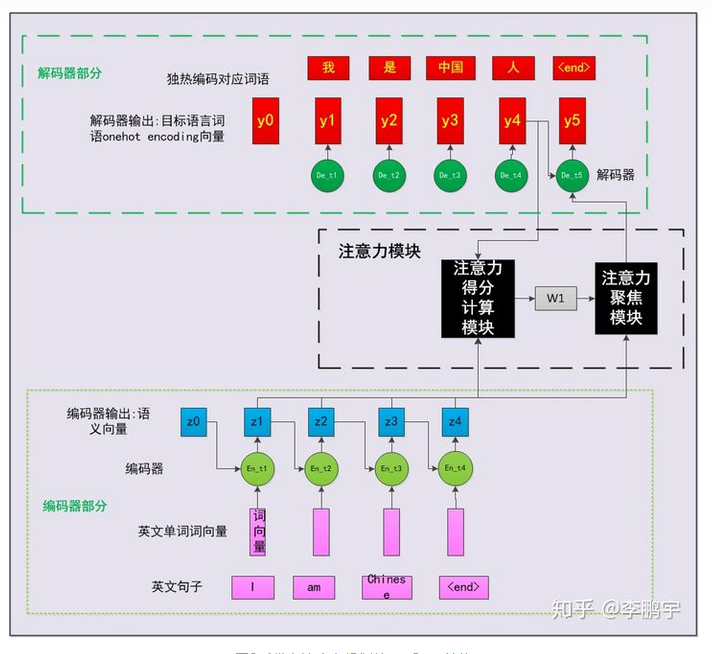
注意力的作用训练状态下,学习编码器时间步的输出和解码器输出的相关度,并在使用的时候用注意力模块对编码器的输出添加不同的权重。循环神经网络RNN用于处理序列数据求解输入序列X对应的输出序列Yh是隐藏单元,W是权重矩阵,b是偏置,f是非线性激活函数。RNN的其他形式LSTM或者GRU,用于解决长时间梯度消失的问题
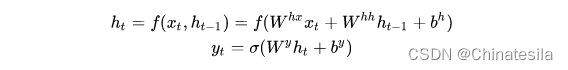
图神经网络GNN通过更新节点的状态来有效铺货单个节点之间的交互,在GNN模型中是通过与相邻节点交换信息来周期性的更新节点的隐藏状态,知道达到稳定的平衡。
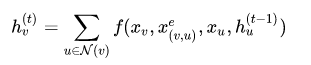
深度强化学习
基于交互的面向目标的学习,从与环境的交互之间学习,目标是最大化奖励函数,此外,强化学习实现了探索机制。
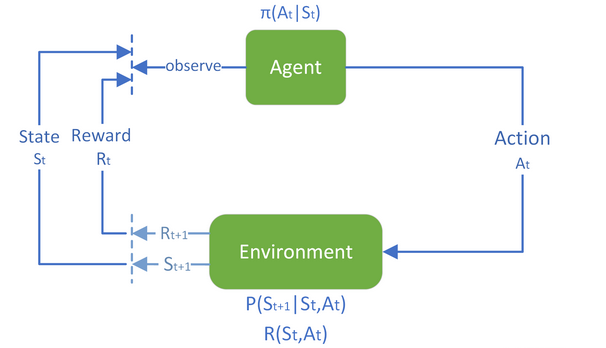
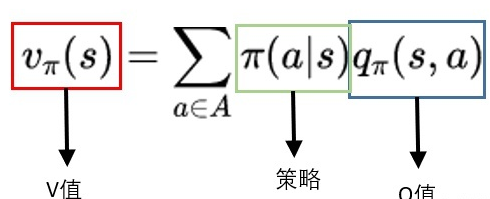
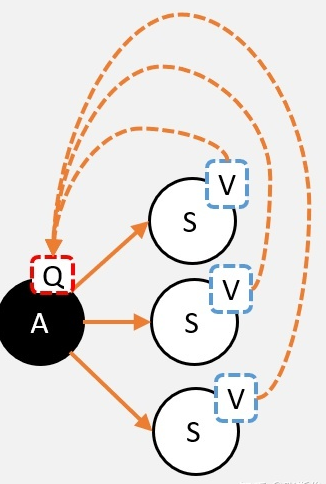
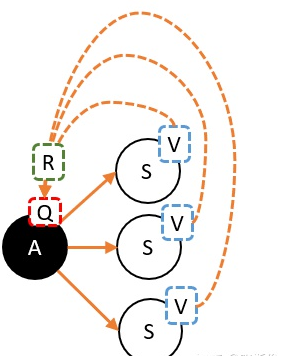
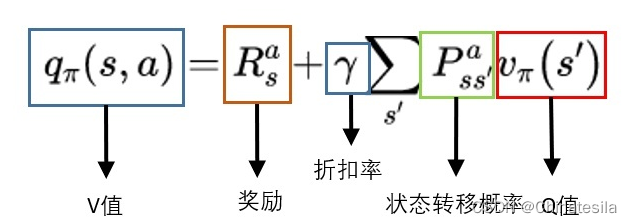
奖励函数时目标累计的一个子元素收益/奖励是智能体目标的一种形式化、数值化的表征, 智能体所有的 “目标” 或 “目的” 都可以归结为:最大化智能体收到的标量奖励信号的累计和(称之为“收益”)的概率期望值 —— Richard S.Sutton 收益是通过奖励信号计算的,而奖励函数是我们提供的,奖励函数起到了人与算法沟通的桥梁,奖励函数对于强化学习来说相当于模型训练的指导者。强化学习的Q值、V值、奖励首先有一个马尔可夫链,包括状态集合,每个状态对应的动作集合,状态转移举着,每个动作的奖励R,奖励可能是正的也可能是负数。Q值,评估动作的价值, 它代表了智能体选择这个动作后,一直到最终状态奖励总和的期望V值,评估状态的价值, 它代表了智能体在这个状态下,一直到最终状态的奖励总和的期望而我们后续所有地工作都是未来找到最准确地Q值或者V值,以便我们选择最适宜地策略。V和Q可以互相换算:用Q值换算V值:
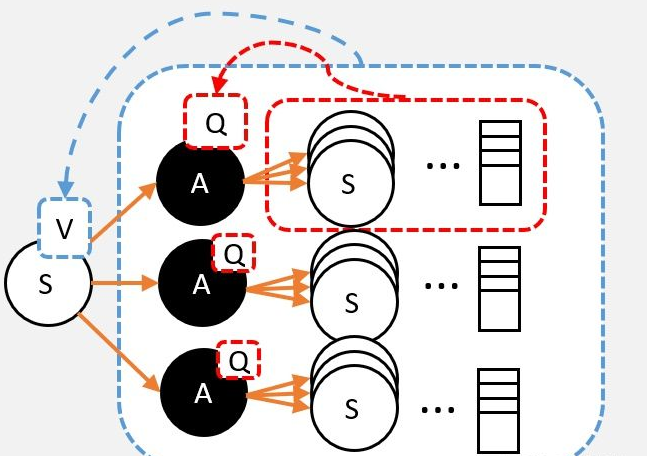
这里需要用到策略,即在某个状态时选择动作的概率用V值算Q值:
这里会用到状态转移概率矩阵,并加上奖励R。
主线奖励和稀疏奖励问题:
主线事件:强化学习的任务目标通常可以分为两类1、定性目标,如下棋获胜,游戏通关。2、定量目标,收益最大化或者消耗最小化主线奖励:根据主线事件可以相应地定义主线奖励1、定性任务,可以在目标达成时给奖励2、定量任务,依据本身或者它的某种度量给奖励但如果只使用主线奖励,往往导致稀疏奖励问题当任务复杂时,仅仅依靠主线奖励无法明确的指导模型的训练,导致盲目探索,算法难以收敛。
稀疏奖励问题:
1、设法提升有效转移的出现概率和利用效率,如事后经验回放、蒙特卡洛树搜索、层级强化学习、增加辅助任务等
2、使用遗传或者进化算法代替强化学习方法,这两类方法可以在超长时间跨度下收集稀疏奖励作为优化的依据,而不会受限于episode导致长度导致的贡献度分配困难。
3、完善对奖励函数的设计
辅助奖励函数设计
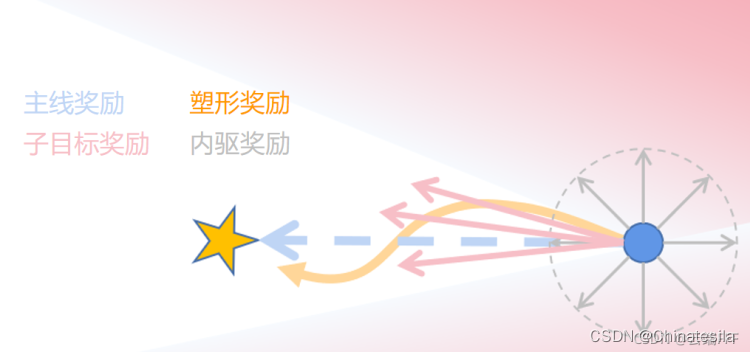
在主线回报的基础上增加其他的奖励或者惩罚,使得反馈变得稠密
1、子目标奖励任务目标分解子目标,按照子目标对主目标的贡献大小和作用方向给与奖励和处罚,这个操作也叫贡献度分配,子目标分为鼓励型和回避型两种。
2、塑形奖励向没有定义奖励信号的状态添加奖励信号,即塑形奖励,给每个状态设定一个势能函数,表示当前状态与目标的距离。
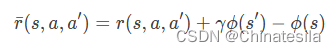
只要状态距离结果差距很小,就可以给与一个高的势能函数,但正向的额外奖励导致reward hacking问题,因此通常改为负的塑形回报,迫使agent尽快到达终点。但这种方式不能保证最优策略不变。reward hacking问题:在设置某个状态的奖励之后,使得模型在这些设置了正向奖励的状态上来回转移,而不是向着目标前进。但一直添加负数的奖励又使得模型不进行状态转移,即使随机概率很大,模型也趋向于待在原地。
3、内驱奖励不针对任何具体的目标,而是无差别地股力agent探索未知状态,用于加强探索。复杂任务的奖励函数很难设计,因为向agent传达目标很困难。
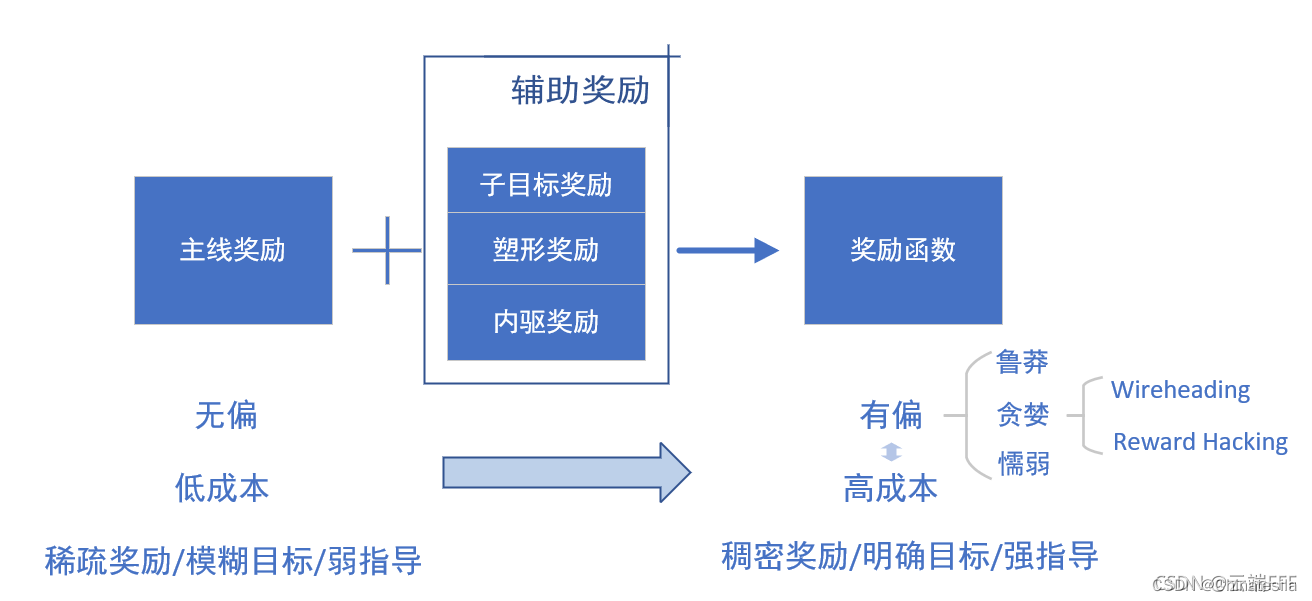 主线奖励针对性地地鼓励主线事件发生,只有在定性目标达成或定量目标得到优化时才会得到奖励,因此优化收益就等价于促进定性目标达成、定量目标极值化,这通常是无偏的,但是奖励比较稀疏 但引入辅助奖励可能导致目标偏差,而减小这种偏差意味着高昂的成本。
主线奖励针对性地地鼓励主线事件发生,只有在定性目标达成或定量目标得到优化时才会得到奖励,因此优化收益就等价于促进定性目标达成、定量目标极值化,这通常是无偏的,但是奖励比较稀疏 但引入辅助奖励可能导致目标偏差,而减小这种偏差意味着高昂的成本。
On-Policy 和Off-Policy问题:
经典解释:两者在学习方式上的区别:若agent与环境互动,则为On-policy(此时因为agent亲身参与,所以互动时的policy和目标的policy一致);若agent看别的agent与环境互动,自己不参与互动,则为Off-policy(此时因为互动的和目标优化的是两个agent,所以他们的policy不一致)。
两者在采样数据利用上的区别:
On-policy:采样所用的policy和目标policy一致,采样后进行学习,学习后目标policy更新,此时需要把采样的policy同步更新以保持和目标policy一致,这也就导致了需要重新采样。
Off-policy:采样的policy和目标的policy不一样,所以你目标的policy随便更新,采样后的数据可以用很多次也可以参考。 总结一句话:训练地策略和环境交互的策略是否一致,一致时on,不一致off。
Online和Offline问题:
offpolicy还是online的,因为虽然环境交互的策略不是当前策略,但是后续还是会对目标策略进行更新的,也就是说模型还是在线的,但是offline模型就完全脱离了和环境的交互,即只使用已经得到的数据集合。比较来看,on-policy的探索粒度是最细的,因此它难以收敛,而offline容易收敛,但可能不会得到好的结果,特别是数据不够全面的情况下。对于强化学习来说,可以说最开始都是offline的,因为在一个回合内,我们不会考虑对状态价值的更新,而是等到回合结束才会更新策略,而online要求我们在回合进行过程中对状态的估值进行更新,这是因为当状态很多时,offline会导致模型训练很慢,效果不好。大致的分法是MC法和TD法。
无模型和有模型问题:
可以大致解释为强化学习任务的环境的状态转移概率矩阵,即如果已经知道状态转移概率矩阵,问题是有模型的,否则是无模型的,当针对无模型的问题时,因为没有转移概率矩阵,所以只估计V值地化话,无法找到对应状态地最优操作,进而应该估计Q值,即针对状态地某个动作地奖励值,而未来找到最优策略,应该尽可能地遍历到所有可能地动作。这里引出了on ,off policy,onplicy选择的方法是:在动作选择时加入机制,因为改变策略会导致环境地不稳定,难以兼顾探索和改进,所以在动作选择时应该采取一种机制,兼顾探索和改进,这种机制也可能是动态的,例如在前期注重探索,而在后期注重改进。offpolicy选择的方法是:使用两个策略,行为和目标策略,一个负责实施策略产生样本这是行为策略,另一个负责学习产生策略,这是目标策略。而一段时间内行为策略不变,在一个周期后同步成目标策略。而因为两个策略不同导致样本产生的概率不同,因此需要对回报进行调整 ,若目标策略π选择某个操作的概率大于b选择该操作的概率,那么应该放大G的效果,反之则应该缩小。
函数拟合算法:
MC
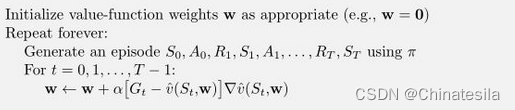
用估值和整体回报的差值来更新估值函数的参数。
基于 bootstrapping 的 TD

用上个状态的估值和下个状态的估值加参数加奖励的差值来更新参数。
sarsa:

sarsa到Q-learning,将w更新修改为