作者|Kenichi Nakanishi 编译|VK 来源|Towards Data Science

我有一个爱买植物的未婚妻,还有一只爱啃植物的猫——我想,有什么比把一个能告诉我植物是否安全的分类器更好呢!
需要注意的一点是,这里所做的所有工作都是在google colabs上完成的,使用的notebook可以在我的Github上找到:https://github.com/kenichinakanishi/houseplant_classifier
步骤1-获取数据
不幸的是,我找不到一个适合我在Kaggle上或使用Google的数据集搜索的预先制作的图像数据集。所以,我准备建立我自己的!
我决定使用ASPCA的《猫和狗的植物毒性清单》,我已经用了好几次了。这给了我们一个很好的核心工作。为了从网站上获取这些文本数据,我们可以求助于BeautifulSoup,这是一个Python库,用于从HTML和XML文件中提取数据。
from urllib.request import Request, urlopen
from bs4 import BeautifulSoupdef getHTMLContent(link):html = urlopen(link)soup = BeautifulSoup(html, 'html.parser')return soup然而,当查看他们的网站时,该表并不是一个易于访问的html表,而是将数据存储为面板中的行。幸运的是,beauthulsoup为我们提供了一种简单的方法来搜索解析树,以找到我们想要的数据。例如:
req = Request('https://www.aspca.org/pet-care/animal-poison-control/cats-plant-list', headers={'User-Agent': 'Mozilla/5.0'})
webpage = urlopen(req).read()# 爬取数据
soup = BeautifulSoup(webpage, 'lxml') # 搜索解析树以从表中获得所有内容
content_list = soup.find_all('span')[7:-4] # 将其放入一个dataframe中进行进一步处理
df_cats = pd.DataFrame(content_list) 在收集完原始数据后,我们需要将其分为多个列,并进行一些拆分:
# 清理字符串
df_cats[0] = df_cats[0].apply(lambda x: str(x).split('>')[1][:-3])
df_cats[4] = df_cats[4].apply(lambda x: str(x).split('>')[1][:-3])
df_cats[1] = df_cats[1].apply(lambda x: str(x).split('(')[1][0:-4])# 删除无用的列并重命名列
df_cats = df_cats.drop(columns=[2,3,5,6]).rename(columns = {0:'Name',1:'Alternative Names',4:'Scientific Name',7:'Family'})# 将有毒和无毒植物分开
df_cats['Toxic to Cats'] = True
first_nontoxic_cats = [index for index in df_cats[df_cats['Name'].str.startswith('A')].index if index>100][0]
df_cats.loc[first_nontoxic_cats:,'Toxic to Cats'] = False然后,我们可以对特定于狗的列表重复此过程,然后合并数据帧并清理nan:
# 合并数据框架到一个,用于保留只存在于一边的值
df_catsdogs = df_dogs.merge(df_cats, how='outer', on=['Name','Alternative Names','Scientific Name','Family'])
df_catsdogs = df_catsdogs.fillna('Unknown')
aspca_df = df_catsdogs.copy()# 假设对猫和狗有相同的毒性
aspca_df['Toxic to Cats'] = aspca_df.apply(lambda x: x['Toxic to Dogs'] if (x['Toxic to Cats'] == 'Unknown') else x['Toxic to Cats'], axis=1)
aspca_df['Toxic to Dogs'] = aspca_df.apply(lambda x: x['Toxic to Cats'] if (x['Toxic to Dogs'] == 'Unknown') else x['Toxic to Dogs'], axis=1)
步骤2-浅度清理
接下来,我们可以开始进行浅度清理,包括查看数据集,决定要使用哪些关键特征,并标准化它们的格式。
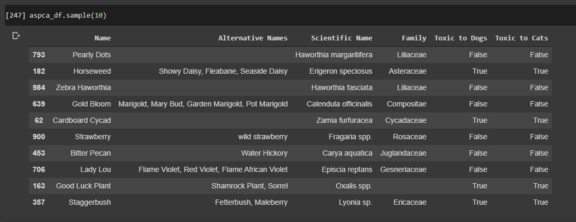
我们目前有名字,替代名称,学名,家族以及毒性列,所有这些都是从用BeautifulSoup在ASPCA网站上爬来的。
由于我们将使用谷歌图像搜索收集图像,因此我们决定根据每种植物的确切学名进行搜索,以获得尽可能具体的图像。像“珍珠点”、“大象耳朵”、“蓬松褶边”和“粉红珍珠”这样的名字会很快返回我们所寻找的植物之外的结果。
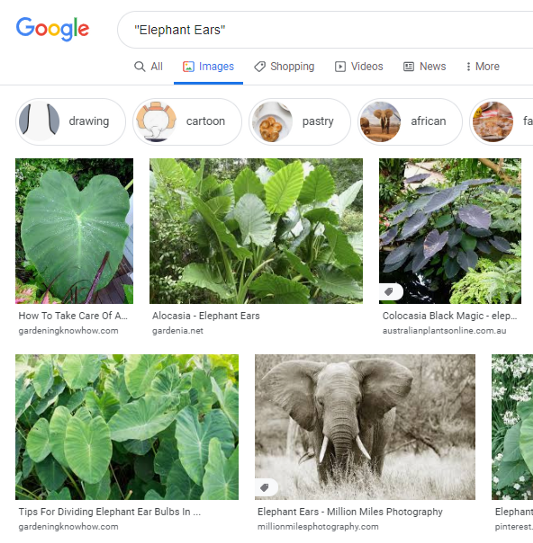
我们编写了几个快速函数来应用于该系列,以尝试将数据标准化以便进一步清理。
# 确保每个学名的标点符号正确
def normalize_capitalization(x):first_word, rest = x.split()[0], x.split()[1:]first_word = [first_word.capitalize()]rest = [word.lower() for word in rest]return ' '.join(first_word+rest)# 清理那些名字不同的重复物种
def species_normalizer(word):if word.split()[-1] in ['sp','species','spp','sp.','spp.']:word = ''.join(word.split()[:-1])return word# 从名称中删除cv,因为这是一种过时的表示品种的方式
def cv_remover(word):if 'cv' in word:word = word.replace(' cv ',' ')return word# 从名称中删除var
def var_remover(word):if 'var' in word:word = word.replace(' var. ',' ')return word# 应用每个函数
aspca_df['Scientific Name'] = aspca_df['Scientific Name'].apply(normalize_capitalization)
aspca_df['Scientific Name'] = aspca_df['Scientific Name'].apply(species_normalizer)
aspca_df['Scientific Name'] = aspca_df['Scientific Name'].apply(cv_remover)
aspca_df['Scientific Name'] = aspca_df['Scientific Name'].apply(var_remover)# 删除特殊字符
aspca_df['Scientific Name'] =